机器学习--(线性回归&逻辑回归)算法
1、线性回归算法
y = kx+b
线性回归
-
线性关系
-
非线性关系
损失函数(最小二乘法)
j(w) = (h(x)-y)^2
=(w*x-y)^2
目标函数:最开始预测出来的模型(w已知)
起始点是已知的(目标函数是已知=>w已知)
第一个w是已知的,损失函数求导
计算下一个w:当前的w-当前求导之后的函数上*学习率(步长)=>已知
学习率不能太大也不能太小
-
太大=>就会跳过最低点
-
太小=>迭代次数多
线性回归优化
-
正规方程(一次计算得到最佳的w)
-
LinearRegression
-
-
梯度下降(迭代寻找w)
-
SGDRegressor
-
线性回归模型评估
-
均方误差
-
mean_squared_error(y_true, y_pred)
过拟合和欠拟合
-
过拟合:训练集效果好,测试集效果差
-
特征过多,存在嘈杂特征
-
解决办法
-
重新清洗数据
-
增加训练数据
-
降维
-
正则化
-
L1正则
-
L2正则
-
-
-
-
欠拟合:训练集和测试集效果都不好
-
特征太少
-
解决方法
-
添加新的特征
-
添加多项式特征(平方立方)
-
-
正则化
-
减少对模型影响大的特征
-
L1正则
-
可以使得其中一些特征W的值直接为0,删除这些特征的影响
-
LASSO回归: from sklearn.linear_model import Lasso
-
-
L2正则
-
可以使得其中W的变小,其中很小的w值会趋近于0,削弱某些特征的影响
-
Ridge回归: from sklearn.linear_model import Ridge
-
模型加载和保存
import joblib
# 加载
joblib.dump(estimator,'path/test.pkl')
# 加载
joblib.dump(estimator,'path/test.pkl')
#案例:
# 1.获取数据
data = load_boston()
# 2.数据集划分
x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, random_state=22)
# 3.特征工程-标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4.机器学习-线性回归(岭回归)
# 4.1 模型训练
estimator = Ridge(alpha=1)
estimator.fit(x_train, y_train)
# 4.2 模型保存
joblib.dump(estimator, "./data/test.pkl")
# 4.3 模型加载
estimator = joblib.load("./data/test.pkl")
# 5.模型评估
# 5.1 获取系数等值
y_predict = estimator.predict(x_test)
print("预测值为:\n", y_predict)
print("模型中的系数为:\n", estimator.coef_)
print("模型中的偏置为:\n", estimator.intercept_)
# 5.2 评价
# 均方误差
error = mean_squared_error(y_test, y_predict)
print("误差为:\n", error)正则化案例:
X10 = np.hstack([X2,X**3,X**4,X**5,X**6,X**7,X**8,X**9,X**10])
estimator3 = LinearRegression()
estimator3.fit(X10,y)
y_predict3 = estimator3.predict(X10)
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict3[np.argsort(x)],color = 'r')
plt.show()
# 打印回归系数
estimator3.coef_
from sklearn.linear_model import Lasso # L1正则
from sklearn.linear_model import Ridge # 岭回归 L2正则
X10 = np.hstack([X2,X**3,X**4,X**5,X**6,X**7,X**8,X**9,X**10])
estimator_l1 = Lasso(alpha=0.005,normalize=True) # 调整alpha 正则化强度 查看正则化效果 normalize=True 数据标准化
estimator_l1.fit(X10,y)
y_predict_l1 = estimator_l1.predict(X10)
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict_l1[np.argsort(x)],color = 'r')
plt.show()
estimator_l1.coef_ # Lasso 回归 L1正则 会将高次方项系数变为0
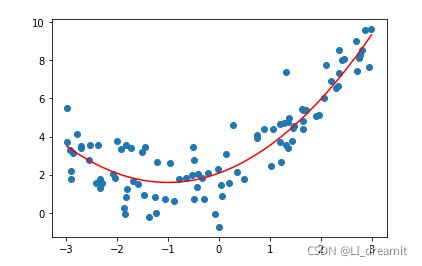
X10 = np.hstack([X2,X**3,X**4,X**5,X**6,X**7,X**8,X**9,X**10])
estimator_l2 = Ridge(alpha=0.005,normalize=True) # 调整alpha 正则化强度 查看正则化效果
estimator_l2.fit(X10,y)
y_predict_l2 = estimator_l2.predict(X10)
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict_l2[np.argsort(x)],color = 'r')
plt.show()
estimator_l2.coef_ # l2 正则不会将系数变为0 但是对高次方项系数影响较大

岭回归实现波士顿房价预测
# 1.获取数据
data = load_boston()
# 2.数据集划分
x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, random_state=22)
# 3.特征工程-标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4.机器学习-线性回归(岭回归)
estimator = Ridge(alpha=1)
# estimator = RidgeCV(alphas=(0.1, 1, 10))
estimator.fit(x_train, y_train)
# 5.模型评估
# 5.1 获取系数等值
y_predict = estimator.predict(x_test)
print("预测值为:\n", y_predict)
print("模型中的系数为:\n", estimator.coef_)
print("模型中的偏置为:\n", estimator.intercept_)
# 5.2 评价
# 均方误差
error = mean_squared_error(y_test, y_predict)
print("误差为:\n", error)线性回归实例:
import pandas as pd
#数据读取#
#index_col=0 ,数据的第一列是索引,指定索引列
store=pd.read_csv('data/store_rev.csv',index_col=0)
#了解event的具体值
store.event.unique()
#array(['non_event', 'special', 'cobranding', 'holiday'], dtype=object)
#这些类别对应的revenue(销售额)是怎样的
store.groupby(['event'])['revenue'].describe()
#这几个类别对应的local_tv(本地电视广告投入)是怎样的
store.groupby(['event'])['local_tv'].describe()
#所有变量,任意两个变量相关分析
#local_tv,person,instore是比较好的指标,与revenue相关度高
store.corr()
#其他变量与revenue的相关分析
#sort_values 将revenue排序,ascending默认升序,False为降序排列
#看到前3个相关变量为local_tv,person,instore
store.corr()[['revenue']].sort_values('revenue',ascending=False)
可视化分析
#可视化分析
import seaborn as sns
import matplotlib.pyplot as plt
#线性关系可视化
#斜率与相关系数有关
sns.regplot(x='local_tv',y='revenue',data=store)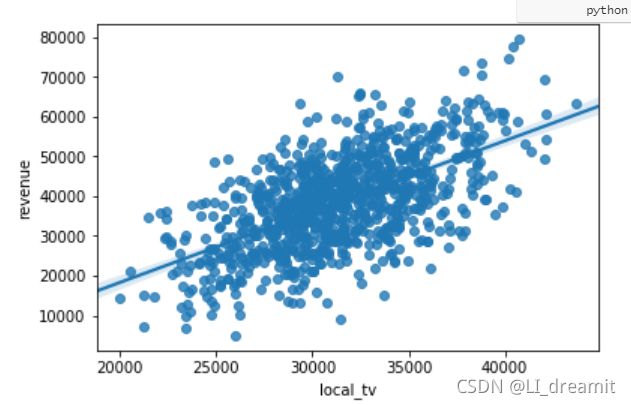
#线性关系可视化
sns.regplot(x='person',y='revenue',data=store)

sns.regplot(x='instore',y='revenue',data=store)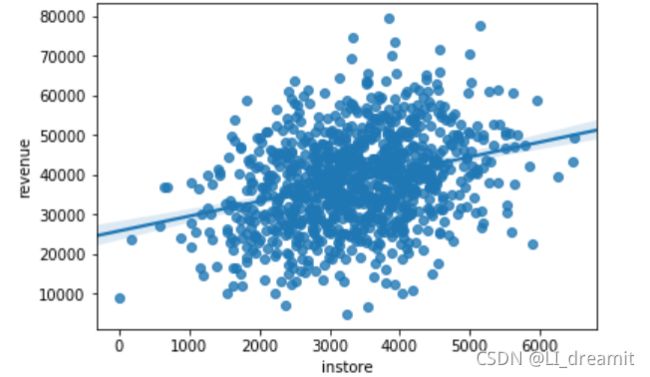
线性回归分析
#删除缺失值,数据有缺失,不处理会报错,需要处理缺失值
store.dropna(inplace=True)
#或者填充缺失值
#缺失值处理,填充0
store=store.fillna(0)
#缺失值处理,均值填充
store=store.fillna(store.local_tv.mean())
store.info()
#设定自变量和因变量
y=store['revenue']
#第一次三个
x=store[['local_tv','person','instore']]
#第二次四个
#x=store[['local_tv','person','instore','online']]
#数据标准化处理
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
x1 = scaler.fit_transform(x)
from sklearn.linear_model import LinearRegression
# 实例化api
model=LinearRegression()
# 训练模型
model.fit(x1,y)
# LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
# 自变量系数
model.coef_
# array([41478.6429907 , 48907.03909284, 26453.89791677])
# 模型的截距
model.intercept_
# -17641.46438435701
# 最后得到x和y的关系为:y=41478*local_tv + 48907*person + 26453*instore - 17641
# 模型的评估,x为'local_tv','person','instore'
y_predict=model.predict(x)#计算y预测值
from sklearn.metrics import mean_squared_error
mean_squared_error(y,y_predict)
# 1.9567577917634842e+182、逻辑回归算法
应用场景
-
广告点击率
-
是否为垃圾邮件
-
是否患病
-
金融诈骗
-
虚假账号
lr原理
将线性回归的结果作为输出值,
将线性回归的输出值输入到sigmoid函数,
最后会输出[0,1],默认sigmoid函数阈值0.5
损失函数
-
对数似然损失
优化
-
梯度下降
lr api
-
sklearn.linear_model.LogisticRegression(solver='lbfgs', penalty=‘l2’, C = 1.0)
-
solver可选参数:{'liblinear', 'sag', 'saga','newton-cg', 'lbfgs'},
-
默认: 'lbfgs';用于优化问题的算法。
-
对于小数据集来说,“liblinear”是个不错的选择,而“sag”和'saga'对于大型数据集会更快。
-
对于多分类问题,只有'newton-cg', 'sag', 'saga'和'lbfgs'可以处理多项损失;“liblinear”仅限于“one-versus-rest”分类。
-
-
penalty:正则化的种类
-
C:正则化力度
-
模型评估
混淆矩阵
-
TP 真正例
-
FP 伪正例
-
FN 伪反例
-
TN 真反例
精确率 TP/(TP+FP)
召回率 TP/(TP+FN)
F1-score
值越大,模型效果越好
from sklearn.metrics import classification_report
roc曲线和auc
roc曲线:tpr和fpr组成的点,由不同的阈值,就会产生不同的tpr和fpr,就组成了不同点
auc:roc曲线下面的面积
-
[0.5-1],越接近1越好,越接近0.5属于乱猜
-
AUC只能用来评价二分类
-
AUC非常适合评价样本不平衡中的分类器性能