配置GPU版本的pytorch和torchvision,初学GPU版本torch踩坑
首先我们来了解一些经常用到的词!!
在我们学习pytorch时,都想用GPU跑,因为GPU支持并行,可以大大加快运行速度。
那么具体为什么GPU比CPU快呢?看这:
为什么GPU能比CPU快??
在了解这个之后,我相信我们也会经常听到CUDA这个名词。
CUDA呢他其实是一个框架,在这个框架上它支持GPU的使用,所以我们后面装的torch库和torchvision库都是cu版本的,相当于把这个框架也给装了进去,然后就支持了GPU。
讲一下torch和pythorch。
当时我被这个困扰了很久,因为没有认真看过他们。
后面才知道torch是一种由lua语言开发的框架,而pytorch就是装了一个python版本的torch,所以在python里面还是导入的torch。
怎么查看自己电脑支不支持cuda呢?也就是能不能运行GPU?
xin+r进入命令行输入 nvidia-smi
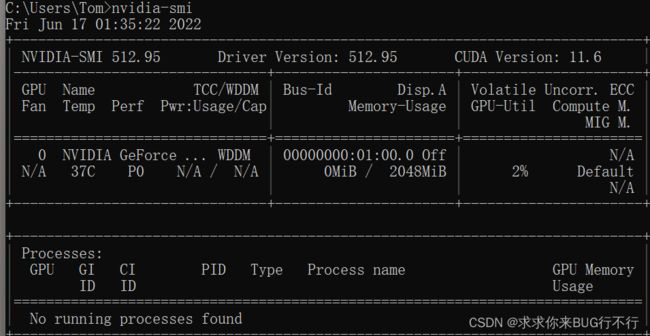
出现这个就代表你电脑有这个框架,可以支持GPU。我的版本比较新,因为我去官网下载了驱动。
官网在这
注意,只是在这个链接里面学习更新自己的CUDA而已,我用他那个方法直接在官网生成命令。
https://pytorch.org/ (pytorch)官网,在这里生成安装命令。
生成的命令:

可以看到他是直接安装的库,而一般都是默认装的CPU版本的,所以说还是没有正确的安装GPU版本。
参考的这个大佬的博客!!!
大哥呀1!!!点击这里
上面大哥说的也很清楚了吧。跟着做完之后就成功了安装GPU版本的torch等库。
之后就好了。
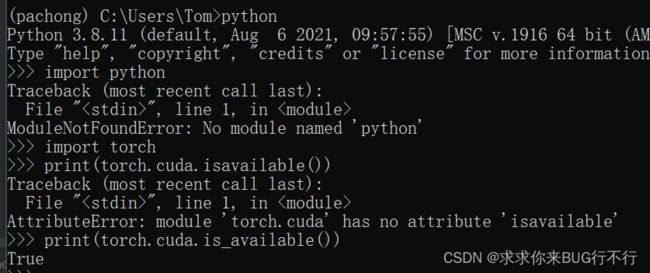
现在就可以使用了。
这里再附上一篇小土堆大哥基础torch和gpu的使用。
这里面是搭建一个基础的网络并进行预测与反向传播。
有着基本的搭建思想以及训练思想。
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
# from model import *
# 准备数据集
from torch import nn
from torch.utils.data import DataLoader
# 定义训练的设备
device = torch.device("cuda")
train_data = torchvision.datasets.CIFAR10(root="../data", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10, 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
tudui = Tudui()
tudui = tudui.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 优化器
# learning_rate = 0.01
# 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("../logs_train")
for i in range(epoch):
print("-------第 {} 轮训练开始-------".format(i+1))
# 训练步骤开始
tudui.train()
for data in train_dataloader: #一次取得64个图片,一个批
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad() #一个bathc进行一次更新,计算下一个的时候上一个的梯度需要清零
loss.backward() #Pytorch的autograd就会自动沿着计算图反向传播
optimizer.step() #参数更新
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
安装gpu版本的torch坑就在自动安装和手动下载库安装这里。后者得到解决。
后面的代码也是搭建了一个基本的网络,值得学习!!!
深夜淦,遭不住了,睡了睡了·~~~