【文本数据挖掘】中文命名实体识别:HMM模型+BiLSTM_CRF模型(Pytorch)【调研与实验分析】
1️⃣本篇博文是【文本数据挖掘】大作业-中文命名实体识别-调研与实验分析
2️⃣在之前的自然语言课程中也完成过一次命名实体识别的实验 【一起入门NLP】中科院自然语言处理作业三:用BiLSTM+CRF实现中文命名实体识别(TensorFlow入门)【代码+报告】,当时使用TensorFlow实现了一种方法,在这次实验中学习了Pytorch实现HMM模型以及BiLSTM+CRF模型。
目录
- 一、任务描述
- 二、中文NER方法
-
- 1. 基于词典和规则的模式匹配方法
- 2. 基于统计机器学习的方法
- 3. 基于深度学习的方法
- 三、实验说明
-
- 1. 实验环境
- 2. 运行步骤
- 3. 目录说明
- 四、实验数据
- 五、模型概述
-
- 模型一:HMM
-
- HMM概述
- HMM训练
- 维特比算法
- 模型二:BiLSTM_CRF
-
- LSTM 与 BiLSTM
- 条件随机场 CRF
- 六、模型评估
-
- HMM
- BiLSTM_CRF
一、任务描述
命名实体识别(Named Entity Recognition,NER)是自然语言处理(Natural Language Processing,NLP)领域的子任务,通常解释为从一段非结构化文本中,将那些人命名实体识别(Named Entity Recognition, NER)是指从自由文本中识别出属于预定义类别的文本片段。类通过历史实践规律认识、熟知或定义的实体识别出来,同时也代表了具有根据现有实体的构成规律发掘广泛文本中新的命名实体的能力。实体是文本中意义丰富的语义单元,识别实体的过程分为两阶段,首先确定实体的边界范围,然后将这个实体分配到所属类型中去。
比如:“ACM宣布,深度学习的三位创造者Yoshua Bengio, Yann LeCun, 以及Geoffrey Hinton获得了2019年的图灵奖”。那么NER的任务就是从这句话中提取出
- 机构名:ACM
- 人名:Yoshua Bengio, Yann LeCun,Geoffrey Hinton
- 时间:2019年
- 专有名词:图灵奖
NER任务最早由第六届语义理解会议(Message Understanding Conference)提出,当时仅定义一些通用实体类别,如地点、机构、人物等。目前命名实体识别任务已经深入各种垂直领域,如医疗、金融等。
二、中文NER方法
1. 基于词典和规则的模式匹配方法
模式匹配方法应用最早,也被称作 NER 专家系统方法(Expert System,ES)。ES 要求包含专业最高水平知识,提取专家知识并将其转换为规则形式。基于词典和规则的模式匹配方法需要领域专家由语法规则等构造大量的规则模板,符合ES知识获取的定义。
模式匹配方法准确率高,但众多实体识别规则的制定依赖领域专家,领域间基本无复用。此外,领域词典需定期维护,不断涌现的新实体与实体的不规则性使得难以构造完备的词典。即使存在缺点,模式匹配方法依旧被应用,因为某些领域实体的规则可以被穷举95%以上,规则仍是提取裁判文书部分实体的首选,同时在之后的机器学习、深度学习 NER 模型中加入规则和字典能够提高准确率。
2. 基于统计机器学习的方法
统计机器学习时代,NER的发展基于大规模有标注语料库(监督数据集)的出现,从编制全面的不易变通的规则系统到期待机器通过大规模语料库的训练自动识别语言规律。语料库中的语言学知识体现在用特征模板来解释实体上下文的特征,使机器理解实体周围成分的含义,这称为特征提取,目的是为了提高统计模型的准确率。
基于统计机器学习的方法是从给定的、已标注好的训练集出发,通过人工构建特征,并根据特定的模型对文本中每个词进行标签标注,实现命名实体识别。
在基于机器学习的命名实体识别方法中,标注的词语通常使用 IOBES 标注集表示,即每个词可以用5类标签进行分类标注。因此基于机器学习的方法也称为序列标注法。
典型的基于统计机器学习的实体识别技术:
- 隐马尔可夫模型(Hidden Markov Model,HMM)
- 最大熵马尔可夫模型(Maximum Entropy Markov Model,MEMM)
- 支持向量机(Support Vector Machine,SVM)模型
- 条件随机场(Conditional Random Fields,CRF)模型
基于统计机器学习算法的命名实体识别模型对特征选取的要求较高,并且需要丰富的语料库。适用于专业性比较强的领域,可在一定程度上提高分词的准确性。
但是,统计机器学习的 NER受限于高质量的大规模标注语料库以及对丰富的、不畏惧语料变迁挑战的特征模板的需要,构建特征模板开销巨大但准确率会相应提高,因此在后续 NER 发展中,特征工程的保留也可助力实体识别。
3. 基于深度学习的方法
深度学习提供了代替复杂庞大的特征工程的解决方案,让机器自动找出潜在的特征模板集合。PLM 动态训练词向量使文本获得更好的向量化表示,进而利用特征提取器提取文本特征,再通过解码器获得预测的序列标签,具体如下:
- 对输入文本基于静态词向量或者动态的 PLM进行向量化表示(Input Representation,IR),具体分为基于字(character)或单词(word)的方式,或融合两种方式的信息(hybrid)进行向量化。IR 阶段需要有效地融合
词和字的信息,还可辅助以统计机器学习方法使用的特征工程。 - 文本编码层(Context Encoder,CE)或序列建模层,对于 IR 阶段输出的向量化文本采用特征提取器进一步提取文本特征。
- 标签解码层(Tag Decoder,TD),将 CE 层输出的向量输入解码网络得到最佳序列标签。
在深度学习的方法中,Word2vec-BILSTM-CRF的组合取得了当时英文NER最佳的效果,之后被应用到中文NER中,深度学习时代BERT-BILSTM-CRF的组合
也成为了性能提升时的参照。表深度学习准确率高,但仍需要大规模的标注数据集和高资源的算力,PLM 的应用对于小模型的训练是一种负担。
三、实验说明
1. 实验环境
- Windows os
- python 3.6.2
- torch 1.2.0+cpu
2. 运行步骤
python3 main.py:训练和评估模型,会打印出模型的精确率、召回率、F1分数值以及混淆矩阵。
python3 test.py:训练完毕之后加载模型进行评估
3. 目录说明
│ data.py:数据处理与加载脚本
│ evaluate.py:验证脚本
│ evaluating.py:用于评价模型,计算每个标签的精确率,召回率,F1分数
│ main.py:主函数
│ output.txt:保存模型测试结果
│ test.py:测试脚本
│ utils.py
│
├─ckpts:保存训练完成后的模型
│ bilstm_crf.pkl
│ hmm.pkl
│
├─models:具体的模型实现
│ bilstm_crf.py
│ config.py:模型参数与训练参数
│ crf.py
│ hmm.py
│ util.py:工具函数
│
├─ResumeNER:测试/验证/训练语料
│ dev.char.bmes
│ test.char.bmes
│ train.char.bmes
四、实验数据
本实验采用的数据集是论文ACL 2018Chinese NER using Lattice LSTM中从新浪财经收集的简历数据,数据的格式如下,它的每一行由一个字及其对应的标注组成,标注集采用BIOES(B表示实体开头,E表示实体结尾,I表示在实体内部,O表示非实体),句子之间用一个空行隔开。
董 B-TITLE
事 M-TITLE
会 M-TITLE
秘 M-TITLE
书 E-TITLE
、 O
副 B-TITLE
总 M-TITLE
经 M-TITLE
理 E-TITLE
。 O
张 B-NAME
雁 M-NAME
冰 E-NAME
五、模型概述
模型一:HMM
HMM概述
隐马尔可夫模型描述由一个隐藏的马尔科夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程。隐马尔可夫模型由 A,B,π 唯一确定,A,B,π 称为隐马尔可夫模型的三要素。
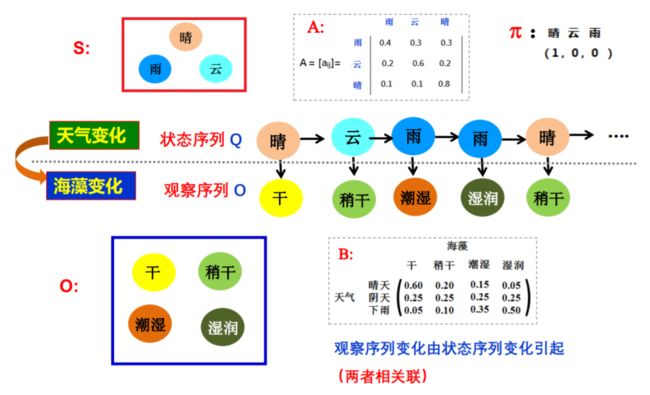
隐马尔可夫研究两件事情变化规律互相影响的问题,在这个例子中,天气的变化会影响海藻的状态(天气晴朗时海藻变得干燥)。
- 状态序列Q:表示起决定的后台本质(晴天,雨天…)
- 观察序列O:表示观察到的前台表象(潮湿,干燥…)
- π :表示初始状态,也就是状态序列的起始值
- 转移矩阵A:描述前后时刻状态变化的概率。比如,当前时刻是雨,下一个时刻是云的概率是0.3,当前时刻是云,下一个时刻是晴的概率是0.8
- 观测概率矩阵B:描述同一时刻从某一状态推出某一个表象的概率。比如,当前晴推出海藻干燥的概率是0.6,阴天推出海藻干燥的概率是0.25。
上述五元组构成了HMM的基本结构。此外,隐马尔可夫模型两个假设
- 观测变量仅依赖于当前时刻的状态变量。(绿色箭头)
- 当前状态仅依赖于前一时刻的状态。(红色箭头)
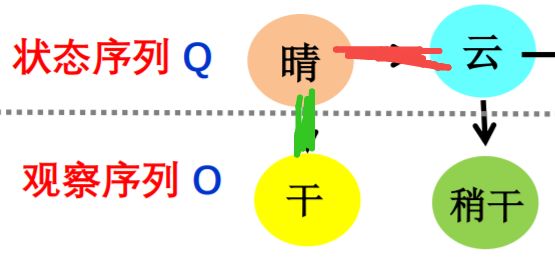
NER本质上可以看成是一种序列标注问题(预测每个字的BIOES标记),在使用HMM解决NER这种序列标注问题的时候,我们所能观测到的是字组成的序列(观测序列),观测不到的是每个字对应的标注(状态序列)。
对应的,HMM的三个要素可以解释为,初始状态分布就是每一个标注作为句子第一个字的标注的概率,状态转移概率矩阵就是由某一个标注转移到下一个标注的概率,观测概率矩阵就是指在某个标注下,生成某个词的概率。根据HMM的三个要素,我们可以定义如下的HMM模型:
"""Args:
N: 状态数,这里对应存在的标注的种类
M: 观测数,这里对应有多少不同的字
"""
self.N = N
self.M = M
# 状态转移概率矩阵 A[i][j]表示从i状态转移到j状态的概率
self.A = torch.zeros(N, N)
# 观测概率矩阵, B[i][j]表示i状态下生成j观测的概率
self.B = torch.zeros(N, M)
# 初始状态概率 Pi[i]表示初始时刻为状态i的概率
self.Pi = torch.zeros(N)
HMM训练
HMM模型的训练过程对应隐马尔可夫模型的学习问题,实际上是根据最大似然的方法估计模型的三个要素,即上文提到的初始状态分布、状态转移概率矩阵以及观测概率矩阵。在估计初始状态分布的时候,假如某个标记在数据集中作为句子第一个字的标记的次数为k,句子的总数为N,那么该标记作为句子第一个字的概率可以近似估计为k/N,使用这种方法,近似估计HMM的三个要素。
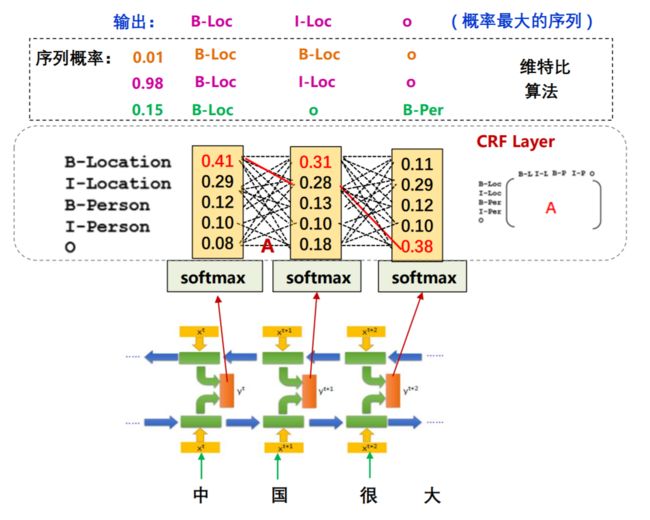
模型训练完毕之后,要利用训练好的模型进行解码,给定模型未见过的句子,求句子中的每个字对应的标注,针对这个解码问题,使用的方法是维特比(viterbi)算法。
维特比算法
Viterbi 搜索算法:利用动态规划使用递归来降低计算复杂度
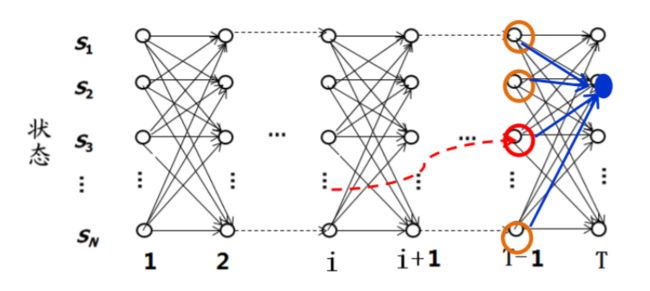
- 如果概率最大路径(或说最短路径)经 i 时刻某个点,一定可以找到S到该点的最短路径(可将i时刻点的最短路径记录)
- 从S到E 的路径必定经过 i时刻的某个点
- 当从状态 i 进入到i+1状态时计算S到i+1 状态时,只考虑 i状态所有节点最短路径和和它们到 i+1状态的距离即可。
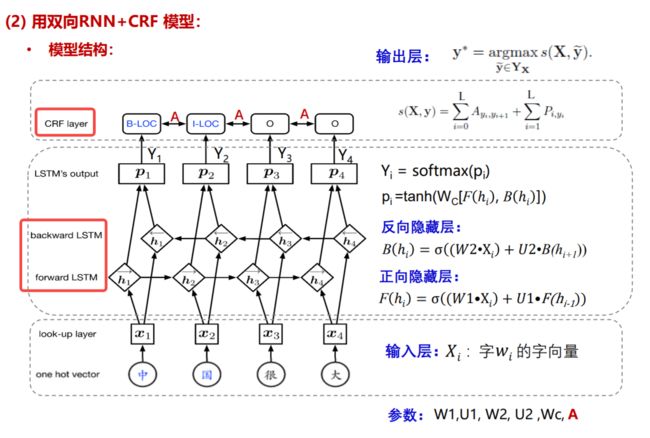
模型二:BiLSTM_CRF
模型结构如下图所示,输入层最主要的是look-up层处理得到词嵌入;中间神经网络层是一个双向LSTM,输出时经过一个softmax;最后在转移矩阵A的限制下,通过CRF层得到预测标签
LSTM 与 BiLSTM
-
LSTM用来解决普通RNN模型存在的长距离依赖问题:距当前节点越远的节点对当前节点处理影响越小,无法建模长时间依赖。
-
RNN由很多循环的单元构成,在标准的RNN中,这个重复的单元只有一个非常简单的结构,比如一个tahn层。
-
LSTM同样也是循环的结构,只是这个重复的单元开始变得复杂起来。
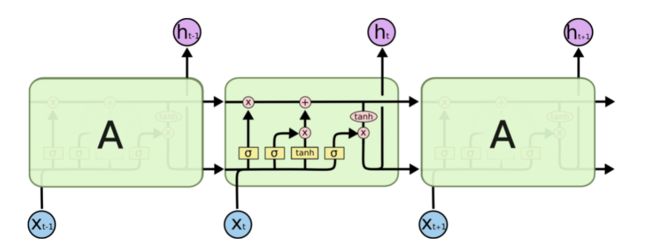
-
在上面的图例中,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。粉色的圈代表 pointwise 的操作,诸如向量的和,而黄色的矩阵就是学习到的神经网络层。合在一起的线表示向量的连接,分开的线表示内容被复制,然后分发到不同的位置。

-
LSTM 的关键就是细胞状态,水平线在图上方贯穿运行。 细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
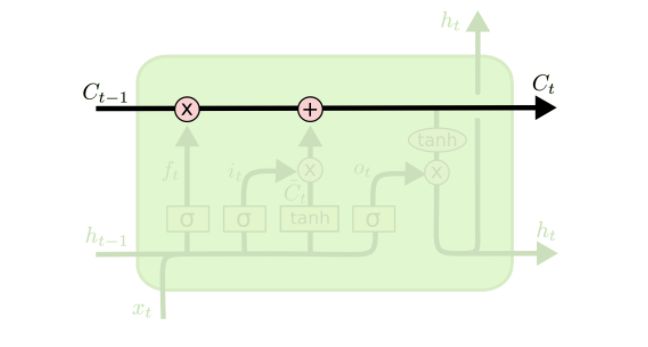
-
LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid 神经网络层和一个 pointwise 乘法操作。下图是一个门结构:
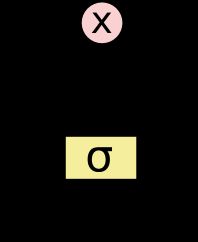
-
Sigmoid 层输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。0 代表“不许任何量通过”,1 就指“允许任意量通过”。LSTM 拥有三个门,来保护和控制细胞状态。
-
遗忘门:决定从细胞状态中丢弃什么信息。
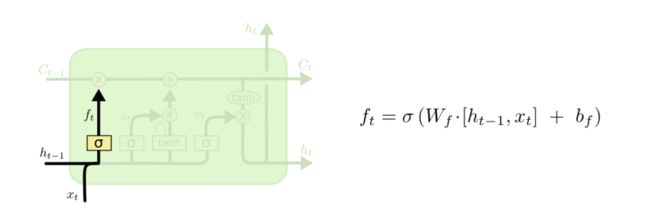
-
输入门:决定什么样的新信息会被存入细胞状态
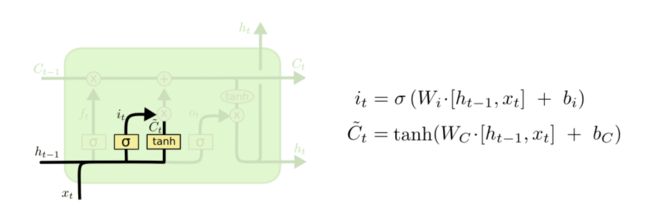
-
输出门:决定输出什么样的值
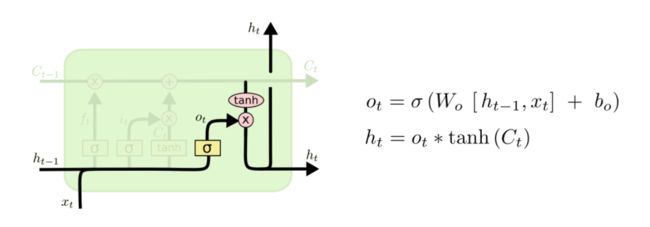
-
LSTM都只能依据之前时刻的时序信息来预测下一时刻的输出,但在有些问题中,当前时刻的输出不仅和之前的状态有关,还可能和未来的状态有关系。比如预测一句话中缺失的单词不仅需要根据前文来判断,还需要考虑它后面的内容,真正做到基于上下文判断。
-
所谓的Bi-LSTM可以看成是两层神经网络,第一层从左边作为系列的起始输入,在文本处理上可以理解成从句子的开头开始输入,而第二层则是从右边作为系列的起始输入,在文本处理上可以理解成从句子的最后一个词语作为输入,反向做与第一层一样的处理处理。最后对得到的两个结果进行处理。
条件随机场 CRF
仅使用BiLSTM和softmax的模型会出现一些问题。如果不使用条件随机场,经过softmax之后,会挑选一个概率最大的标签输出,第一列最大的是0.14,那么对应“中”的标签就应该是B-Location(B代表Begin),代表地名的开始;第二列概率中最大的是0.31,其对应的标签仍然为B-Location,很显然,两个挨着的字是不可能都为地名的开始,那么要如何解决问题这个问题呢?这就是条件随机场的工作了
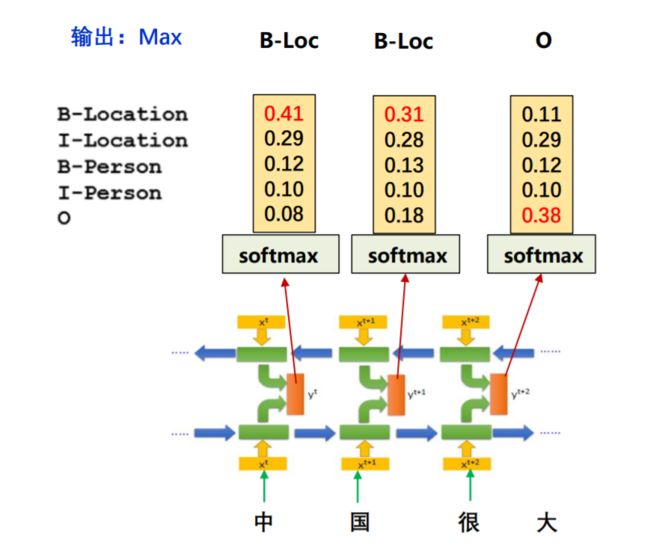
之所以会出现连续的两个B,是因为输出之间没有限制条件,应该告诉模型,如果前一个字是Begin,后一个字的标签就不能是Begin。那么 CRF是如何完成这样的限制的呢? 它是通过一个转移矩阵规定输出序列的概率做到的。
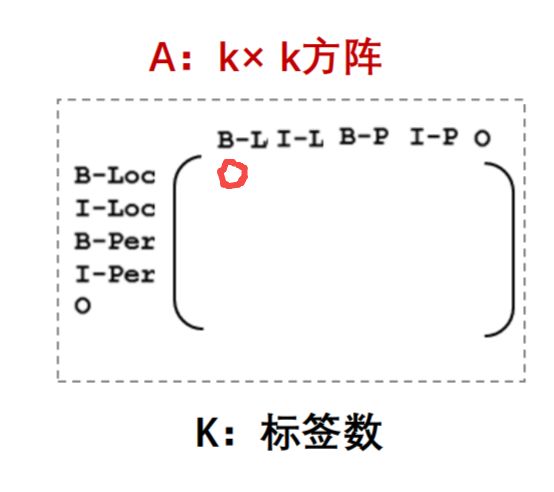
在这个矩阵中,第一行第一列代表前一个字是B-Location,后一个字是B-Location的概率,根据上文的描述,这个概率应该非常小,甚至是0。那么加入了CRF之后的模型结构就应该是下图所示:
六、模型评估
- TP:将正类预测为正类数;
- FN:将正类预测为负类数;
- FP:将负类预测为正类数;
- TN:将负类预测为负类数;
评价指标:
- F1值: = /( + + )
- 召回率: = /( + )
- 准确率: = ( + )/( + + + )
HMM
precision recall f1-score
B-RACE 1.0000 0.9286 0.9630
E-LOC 0.5000 0.5000 0.5000
E-NAME 0.9000 0.8036 0.8491
E-TITLE 0.9514 0.9637 0.9575
B-LOC 0.3333 0.3333 0.3333
M-TITLE 0.9038 0.8751 0.8892
M-NAME 0.9459 0.8537 0.8974
B-CONT 0.9655 1.0000 0.9825
M-EDU 0.9348 0.9609 0.9477
B-NAME 0.9800 0.8750 0.9245
E-PRO 0.6512 0.8485 0.7368
M-ORG 0.9002 0.9327 0.9162
E-RACE 1.0000 0.9286 0.9630
E-CONT 0.9655 1.0000 0.9825
B-EDU 0.9000 0.9643 0.9310
M-PRO 0.4490 0.6471 0.5301
B-ORG 0.8422 0.8879 0.8644
E-ORG 0.8262 0.8680 0.8466
B-PRO 0.5581 0.7273 0.6316
M-LOC 0.5833 0.3333 0.4242
O 0.9568 0.9177 0.9369
M-CONT 0.9815 1.0000 0.9907
B-TITLE 0.8811 0.8925 0.8867
E-EDU 0.9167 0.9821 0.9483
avg/total 0.9149 0.9122 0.9130
BiLSTM_CRF
precision recall f1-score
B-RACE 1.0000 0.9286 0.9630
E-LOC 1.0000 0.8333 0.9091
E-NAME 0.9904 0.9196 0.9537
E-TITLE 0.9819 0.9819 0.9819
B-LOC 1.0000 1.0000 1.0000
M-TITLE 0.9439 0.8933 0.9179
M-NAME 0.9277 0.9390 0.9333
B-CONT 1.0000 1.0000 1.0000
M-EDU 0.9598 0.9330 0.9462
B-NAME 1.0000 0.8929 0.9434
E-PRO 0.9091 0.9091 0.9091
M-ORG 0.9680 0.9593 0.9637
E-RACE 1.0000 1.0000 1.0000
E-CONT 1.0000 1.0000 1.0000
B-EDU 0.9561 0.9732 0.9646
M-PRO 0.7927 0.9559 0.8667
B-ORG 0.9658 0.9693 0.9675
E-ORG 0.9276 0.9042 0.9158
B-PRO 0.8788 0.8788 0.8788
M-LOC 1.0000 1.0000 1.0000
O 0.9558 0.9873 0.9713
M-CONT 1.0000 1.0000 1.0000
B-TITLE 0.9434 0.9288 0.9360
E-EDU 0.9820 0.9732 0.9776
avg/total 0.9580 0.9575 0.9575
参考:NLP实战-中文命名实体识别 需要将data.py文件中的 word, tag = line.strip(‘\n’).split()改为 word, tag = line.strip(‘\r\n’).split()