基于RNN的情感分析
基于RNN的情感分析
文本情感分类是情感分析领域的核心问题,旨在解决评论情感极性的自动判断问题。本次使用深度学习技术来解决文本分类问题,主要分为以下两个部分:
- 归纳总结传统情感分类技术,包括基于字典的方法、基于机器学习的方法、两者混合方法、基于弱标注信息的方法以及基于深度学习的方法;
- 针对前人情感分类方法的不足,详细介绍所提出的面向情感分类问题的弱监督深度学习框架。此外,还介绍了评论主题提取相关的经典工作。最后,总结了情感分类问题的难点和挑战,并对未来的研究工作进行了展望;
本次实验对aclImdb电影评价数据集进行深度学习,用pytorch构建和训练基于循环神经网络LSTM的模型,并利用此模型对于给定的电影评论文本进行预测,判断改评论是正面的还是负面的。试验后准确率高达98%。
一、情感分类的实现方法
1、RNN
RNN(recurrent neural network,循环神经网络),在一般的神经网络由输入层、隐藏层、输出层构成。
RNN在处理序列数据上是高效的,在此模型中有着一些特殊的信号决定了此模型是否需要记住上下文信息。他们可以从上一个时间步获取信息并传递到下一个时间步中。下图是一个标准循环神经网络的图像。
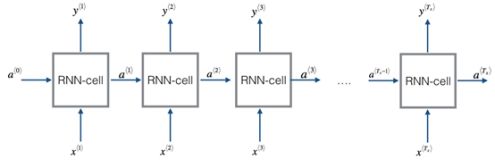
然而传统神经网络有一个缺点就是,同一层的神经元不会相互传递,这就导致了在一些语言翻译中表现不佳,以为在翻译时,下一个单词和上一个是有联系的,语言就是关联的。一个一个翻译出来的准确率很低。
RNN可以让隐藏层的神经元相互交流,将上一个输出结果以信息方式储存在隐藏层,在下一个单词翻译时,上一个输出也对它有影响,这就把单词翻译贯通了起来。其实现过程如图所示。

RNN 按下图所示时间顺序展开,在 t 时刻,网络读入第 t 个输入 xt,以及前一时刻状态值ht−1(向量表示,h0表示初始化为 0 的向量),从而计算出本时刻隐藏层的状态值ht,若函数表示为f,则公式表示为:
ht=f(xt,ht−1)=σ(Wxhxt+Whhht−1+bh);
其中,Wxh是输入层到隐藏层的矩阵参数,Whh为隐藏层到隐藏层的矩阵参数,bh为隐藏层偏置参数。RNN隐藏层的状态向量被送入一个Softmax分类器,然后判断其情感;
2、 LSTM
保留了文本中的长期依赖信息,通过对循环层的刻意设计避免了长期依赖和梯度消失问题。输入单元输入数据x(t),隐藏层输出hh(t),在这些单元中,隐藏层表达复杂,主要分为4个部分:
输入门i、输出门o、遗忘门f、记忆控制器c,将LSTM表示函数记为F,
ht = F (xt ,ht−1) ;
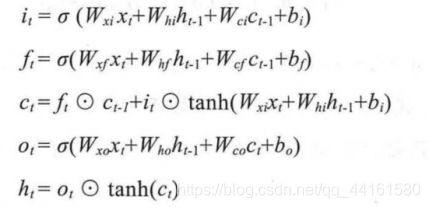
其中W及b是模型参数,tanh是双曲正切函数;
二、 情感分类的研究思路
设计通过python爬虫与和自己构建的电影类的情感字典来分析影评。数据分析中要使用弱标注进行标注和结巴分词进行分词。其中情感词典的构建以知网的HowNet和台湾的NTDSP为基础,选取20个核心词汇用PMI来计算新词的情感倾向在求PMI值的和来确定是否为正面词汇,以此来构建情感词典。利用情感词典和找到情感词,否定词,程度副词计算出情感值。利用SVM进行分类计算出最优参数,再利用准确率召的形式回率来表现影评的情感,再用词云图和分析表来呈现所计算各种结果。
三、文本情感分类的RNN方法
文本分类是自然语言处理的一个常见任务,它把一段不定长的文本序列变换为文本的类别。本节关注它的一个子问题:使用文本情感分类来分析文本作者的情绪。这个问题也叫情感分析,并有着广泛的应用。例如,我们可以分析用户对产品的评论并统计用户的满意度,或者分析用户对市场行情的情绪并用以预测接下来的行情。
在这里我们将使用RNN(循环神经网络如图5所示)对电影评论进行情感分析,结果为positive或negative,分别代表积极和消极的评论。至于为什么使用RNN而不是普通的前馈神经网络,是因为RNN能够存储序列单词信息,得到的结果更为准确。这里我们将使用一个带有标签的影评数据集进行训练模型。
将单词传入到嵌入层而不是使用ONE-HOT编码,是因为词嵌入是一种对单词数据更好的表示。
在嵌入层之后,新的表示将会进入LSTM细胞层。最后使用一个全连接层作为输出层。我们使用sigmiod作为激活函数,因为我们的结果只有positive和negative两个表示情感的结果。输出层将是一个使用sigmoid作为激活函数的单一的单元。
四、实验过程
1、导入并读取数据集
fname = os.path.join(DATA_ROOT, 'aclImdb_v1.tar.gz')
//将压缩文件进行解压
if not os.path.exists(os.path.join(DATA_ROOT, 'aclImdb')):
print("从压缩包解压...")
with tarfile.open(fname, 'r') as f:
f.extractall(DATA_ROOT)
// 解压文件到此指定路径
from tqdm import tqdm
// 可查看读取数据的进程
def read_imdb(folder='train', data_root=r'E:\data\aclImdb'):
data = []
for label in ['pos', 'neg']:
folder_name = os.path.join(data_root, folder, label)
// 拼接文件路径 如:E:\data\aclImdb\train\pos\
for file in tqdm(os.listdir(folder_name)):
// os.listdir(folder_name) 读取文件路径下的所有文件名,并存入列表中
with open(os.path.join(folder_name, file), 'rb') as f:
review = f.read().decode('utf-8').replace('\n', ' ').lower()
data.append([review, 1 if label == 'pos' else 0])
// 将每个文本读取的内容和对应的标签存入data列表中
random.shuffle(data)
// 打乱data列表中的数据排列顺序
return data
2、数据预处理
通常而言,未标注好的数据具有大量的噪声,噪声会对模型的效果产生直接的影响,所以在使用这些数据前,应当对数据进行数据预处理,比如分词、标注、空间向量转换等。
// 空格分词
def get_tokenized_imdb(data):
'''
:param data: list of [string, label]
'''
def tokenizer(text):
return [tok.lower() for tok in text.split(' ')]
return [tokenizer(review) for review,_ in data]
// 只从data中读取review(评论)内容而不读取标签(label),对review使用tokenizer方法进行分词
// 创建词典
def get_vocab_imdb(data):
tokenized_data = get_tokenized_imdb(data)
// 调用get_tokenized_imdb()空格分词方法获取到分词后的数据tokenized_data
counter = collections.Counter([tk for st in tokenized_data for tk in st])
// 读取tokenized_data列表中每个句子的每个词,放入列表中。
//collections.Counter()方法可计算出列表中所有不重复的词数总和
return Vocab.Vocab(counter, min_freq=5)
// 去掉词频小于5的词
//对data列表中的每行数据进行处理,将词转换为索引,并使每行数据等长
def process_imdb(data, vocab):
max_len = 500
// 每条评论通过截断或者补0,使得长度变成500
def pad(x):
return x[:max_len] if len(x) > max_len else x + [0]*(max_len - len(x))
// x[:max_len] 只获取前max_len个词
// x + [0]*(max_len - len(x)) 词数小于max_len,用pad=0补长到max_len
tokenized_data = get_tokenized_imdb(data)
// 调用方法获取分词后的数据
features = torch.tensor([pad([vocab.stoi[word] for word in words]) for words in tokenized_data])
// 将词转换为vocab词典中对应词的索引
labels = torch.tensor([score for _, score in data])
return features, labels
3、创建数据迭代器
// 创建数据迭代器
batch_size = 64
train_set = Data.TensorDataset(*process_imdb(train_data, vocab))
test_set = Data.TensorDataset(*process_imdb(test_data, vocab))
train_iter = Data.DataLoader(train_set, batch_size, True)
test_iter = Data.DataLoader(test_set, batch_size)
// for X, y in train_iter:
// print('X', X.shape, 'y', y.shape)
// break
//'#batches:', len(train_iter)
// X torch.Size([64, 500]) y torch.Size([64])
4、构建循环神经网络
//class BiRNN(nn.Module):
def __init__(self, vocab, embed_size, num_hiddens, num_layers):
super(BiRNN, self).__init__()
self.embedding = nn.Embedding(len(vocab), embed_size)
self.encoder = nn.LSTM(
input_size=embed_size,
hidden_size=num_hiddens,
num_layers=num_layers,
# batch_first=True,
bidirectional=True
)
self.decoder = nn.Linear(4*num_hiddens, 2)
def forward(self, inputs):
//inputs: [batch_size, seq_len], LSTM需要将序列长度(seq_len)作为第一维,所以需要将输入转置后再提取词特征
// 输出形状 outputs: [seq_len, batch_size, embedding_dim]
embeddings = self.embedding(inputs.permute(1, 0))
// rnn.LSTM只传入输入embeddings, 因此只返回最后一层的隐藏层在各时间步的隐藏状态。
// outputs形状是(seq_len, batch_size, 2*num_hiddens)
outputs, _ = self.encoder(embeddings)
// 连结初始时间步和最终时间步的隐藏状态作为全连接层输入。
// 它的形状为 : [batch_size, 4 * num_hiddens]
encoding = torch.cat((outputs[0], outputs[-1]), dim=-1)
outs = self.decoder(encoding)
return outs
5、数据集训练
// 评估
def evaluate_accuracy(data_iter, net, device=None):
if device is None and isinstance(net, torch.nn.Module):
// 如果没指定device就使用net的device
device = list(net.parameters())[0].device
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
if isinstance(net, torch.nn.Module):
net.eval() # 评估模式, 这会关闭dropout
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train()
// 改回训练模式
else:
// 自定义的模型, 3.13节之后不会用到, 不考虑GPU
if('is_training' in net.__code__.co_varnames):
// 如果有is_training这个参数
// 将is_training设置成False
acc_sum += (net(X, is_training=False).argmax(dim=1) == y).float().sum().item()
else:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
// 训练
def train(train_iter, test_iter, net, loss, optimizer, device, num_epochs):
net = net.to(device)
print("training on ", device)
batch_count = 0
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
【训练结果】
| 迭代次数 | loss | trainacc | testacc |
|---|---|---|---|
| epoch 1 | 0.6267 | 0.634 | 0.798 |
| epoch 2 | 0.1673 | 0.863 | 0.832 |
| epoch 3 | 0.0566 | 0.936 | 0.859 |
| epoch 4 | 0.0230 | 0.969 | 0.855 |
| epoch 5 | 0.0098 | 0.984 | 0.847 |
五、总结
最近这几年自然语言处理变得越来越热门,但是相关算法在很多年以前就已经有了,热门主要的原因在于机器性能的提升、数据爆炸等等一系列相关因素。本文在文本数据量剧增的背景下探讨了使用深度学习判定文本的情感的可行性以及国内外前辈们所做的研究工作,举例说明了深度学习在情感分析上有哪些应用案例,研究了标准RNN模型、RNN单元、长短时记忆单元(LSTM)、门控循环单元(GRU)、切片循环神经网络(SRNN)的结构以及算法,使用了切片循环神经网络来构建此项目并应用在情感分类上。
本项目的不足点在于:
1.数据集上,由于分类标签很少、数据量不足、数据噪声的存在,这注定在测试中无法达到很高的准确率。
2.受时间的限制,本项目的研究与设计也存在着一定的不足,对于本项目中的方法也缺少更多的摸索与探究。
PS.博客是完成课堂实验剩余的时间写的,有些匆忙。
对这个课题感兴趣的可以直接下载我的源码进行测试,链接附上,欢迎一起交流学习~
https://download.csdn.net/download/qq_44161580/16497584