简述lasso估计以及调节参数的CV与BIC准则
1.Lasso
Lasso方法是系数压缩法中的一种,基于最小二乘方法的Lasso方法是基础,下面对最小二乘下的Lasso进行阐述。
1.1 Lasso估计
Lasso估计最先是由斯坦福大学的著名统计学家Tibshirani[2]提出的,其思想就是加一项惩罚函数,然后进行变量选择和参数估计,其可以表示为:
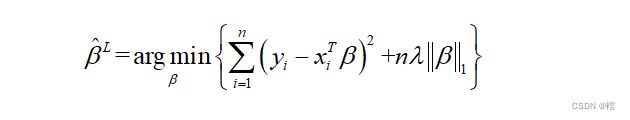
(1)
即Lasso估计就是寻找最小的![]() ,其中,
,其中,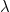 是调节参数,n为样本容量,满足 (1)式的称为正则化Lasso估计。Lasso是一种系数压缩的方法,它最大的优点就是它能够连续缩减、压缩,并且是一种正则化估计,它能够准确选择出那些系数不为0的变量,即重要变量;同时,它也能够准确将一些不相关的变量系数压缩为0,从而实现变量选择。另外它也能给出线性回归模型系数的估计值。也正是基于Lasso估计的提出,Efron等前辈提出了有效的角回归算法,Friedman等前辈提出了坐标下降算法等,这些算法的提出使得基于Lasso方法的变量选择方法迅速发展,且应用于各个领域。
是调节参数,n为样本容量,满足 (1)式的称为正则化Lasso估计。Lasso是一种系数压缩的方法,它最大的优点就是它能够连续缩减、压缩,并且是一种正则化估计,它能够准确选择出那些系数不为0的变量,即重要变量;同时,它也能够准确将一些不相关的变量系数压缩为0,从而实现变量选择。另外它也能给出线性回归模型系数的估计值。也正是基于Lasso估计的提出,Efron等前辈提出了有效的角回归算法,Friedman等前辈提出了坐标下降算法等,这些算法的提出使得基于Lasso方法的变量选择方法迅速发展,且应用于各个领域。
1.2 自适应Lasso估计
由于不同的回归系数对模型的影响程度是不同的,而在 (1)式中,我们可以看见对于模型中不同的回归系数选择了同一个惩罚参数,显然这是不科学、不合理的。因此,为了解决这一问题,Zou[5]提出了自适应Lasso(adaptive Lasso)估计方法,其具体形式表示为:
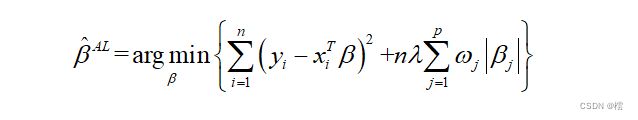
(2)
其中,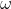 为权重,即通过设置不同的权重,对不同回归系数实行不同程度的惩罚,那些对因变量影响较大的自变量的系数进行较小的惩罚,而对那些对因变量影响较小或者不相关变量的自变量的系数进行较大的惩罚,从而实现自适应的变量选择。
为权重,即通过设置不同的权重,对不同回归系数实行不同程度的惩罚,那些对因变量影响较大的自变量的系数进行较小的惩罚,而对那些对因变量影响较小或者不相关变量的自变量的系数进行较大的惩罚,从而实现自适应的变量选择。
2.调节参数的选择
关于调节参数的选择,也有很多学者研究,有不同的判断准则,但是应用最为广泛的是CV准则和BIC准则。下面对这两种准则做一简单介绍。
(a)CV准则
CV准则最简单的是留一交叉验证方法,它的思想就是把我们的数据集分成两部分,一部分是训练集,另一部分是测试集,如果数据集总共有n个样本,那将其中一个作为测试集,其余(n-1)个当做训练集,然后我们用训练集去拟合得到一个模型,再将测试集的自变量代入,可以得到其对应的因变量y的值。我们从第一个样本开始作为测试集,即第一次去掉(x1,y1),也就是把(x1,y1)当做测试集,剩余的{(x2,y2),...(xn,yn)}这个作为训练集,在这个训练集上去进行拟合线性回归模型,再将x1代入拟合完的线性回归模型中得出y1的拟合值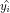 ,
,
![]()
作为训练集,在这个训练集上去进行拟合线性回归模型,再将xi代入拟合好的模型中求得yi的拟合值![]() ,再计算
,再计算
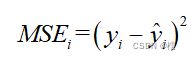
,就这样一直计算n次,得到n个均方误差MSEi,i=1,2,...n于是我们就可以得到n个均方误差的均值为:
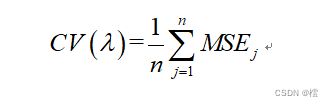
这个是在一个下对应的CV值,我们要选最优的,首先要给予一个初始max,再采用格子点方法,可以采用100个格子点,将其分为100个,
![]()
,i=1,2,....100,,这样在100个下,我们可以对每一个i都求一个CV(i),然后我们再根据CV值最小原则选取最优的,即:
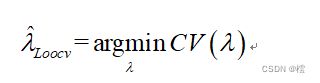
基于CV准则下,将留一交叉验证法改进,我们有k折交叉验证法,两者本质思想是一样的,k折交叉验证法只是将样本分成了k个小组,然后每次留一组去进行测试,其余(k-1)组作为训练集,同理我们每次都可以计算出一个均方误差MSE,这样我们就可以得到k个MSE,它们k个均方误差的均值是:
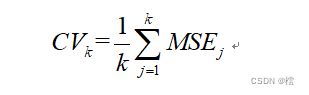
同理,继续采用格子点方法,求出使得CV值最小的那个。显而易见,当k=n时候,k折交叉验证法就是留一交叉验证法。
(b)BIC准则
所谓BIC准则,就是基于贝叶斯方法下的准则,和CV准则一样,首先要给予一个初始值 max,再采用格子点方法,将初始值分割,可以采用100个格子点,将其分为100个,
![]()
,i=1,2,....100,这样在这100个下,根据(1)式和(2)式,我们可以对每一个i都求一个![]() ,进而可以求出 i此对应的BIC( i), 我们再选择最小的 BIC( i)对应的 i,即
,进而可以求出 i此对应的BIC( i), 我们再选择最小的 BIC( i)对应的 i,即
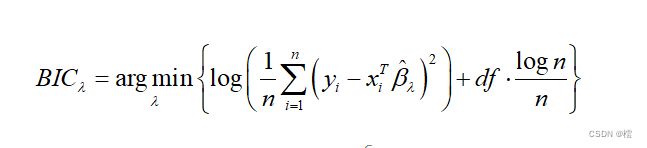
其中df是在 i下求得的回归系数![]() 中系数不为0的个数。这样我们就可以选出最优的调节参数。
中系数不为0的个数。这样我们就可以选出最优的调节参数。
3.一个例子
为了了解和预测人体吸入氧气的效率,收集了31名中年男性的健康状况调查资料,共调查了7项指标:吸氧效率(Y)、年龄(x1,单位:岁)、体重(x2,单位:千克)、跑1.5千米所需要时间(x3,单位:分钟)、休息时的心率(x4,次/分钟)、跑步时的心率(x5,次/分钟)和最高心率(x6,次/分钟),数据见附录,在该资料中吸氧效率Y作为响应变量,其他六个变量作为协变量,建立多元回归模型并统计分析。
把数据用文件data.csv保存,放在R语言的工作目录下,读数据并建立多元线性回归模型,用函数lm()计算,summary()提取信息[6],输出结果如下:

(1)经验回归方程为:
![]()
(2)回归系数的显著性检验:从各个回归系数的p值看出,变量x1,x3,x5和x6的p值小于显著性水平,可以认为它们是线性回归显著的,而变量x2和x4的p值大于显著性水平,认为它们是不显著的变量。进一步可以使用lasso方法压缩变量。
lasso变量选择
用程序包glmnet中的函数对上述数据进行lasso回归分析,输出的结果如下:
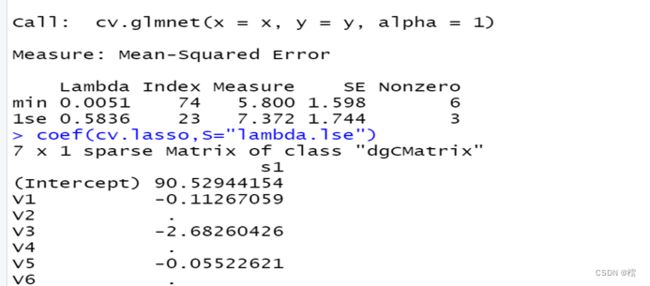
从上面的结果可以看出,采用“一个标准差”准则的![]() 时,可以产生稀疏解,使得x2,x4和x6 的系数为0,使得模型更为简单,不易导致过拟合。
时,可以产生稀疏解,使得x2,x4和x6 的系数为0,使得模型更为简单,不易导致过拟合。
自适应lasso变量选择
用程序包msgps中的函数对上述数据进行lasso回归分析,输出的结果如下:
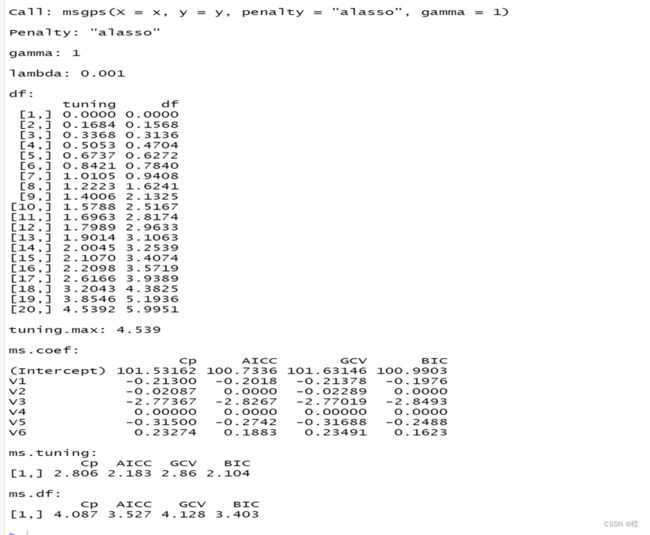
从上面结果可以看出,当采用BIC方法选取调节参数时,把x2和x4变量的系数被压缩成0, 使得模型更为简单,不易导致过拟合。
R中实现代码:
library(glmnet)
library(MASS)
library(Matrix)
library(latex2exp)
library(msgps)
W=read.csv('C:/Users/ASUS/Desktop/data.csv')
lm.reg=lm(W$Y~W$X1+W$X2+W$X3+W$X4+W$X5+W$X6)
summary(lm.reg)
x=cbind(W$X1,W$X2,W$X3,W$X4,W$X5,W$X6)
y=c(W$Y)
fit_lasso=glmnet(x,y,alpha=1,nlambda=100)
lam=fit_lasso$lambda
cv.lasso=cv.glmnet(x,y,alpha=1)
coef(cv.lasso,S="lambda.lse")
alasso_fit=msgps(x,y,penalty="alasso",gamma=1)
summary(alasso_fit)
数据
| Y |
X1 |
X2 |
X3 |
X4 |
X5 |
X6 |
| 44.609 |
44 |
89.47 |
11.37 |
62 |
178 |
182 |
| 45.313 |
40 |
75.05 |
10.07 |
62 |
185 |
185 |
| 54.297 |
44 |
85.84 |
8.65 |
45 |
156 |
168 |
| 59.571 |
42 |
68.15 |
8.17 |
40 |
166 |
172 |
| 49.874 |
38 |
89.02 |
9.22 |
55 |
178 |
180 |
| 44.811 |
47 |
77.45 |
11.63 |
58 |
176 |
176 |
| 45.681 |
40 |
75.98 |
11.95 |
70 |
176 |
180 |
| 49.091 |
43 |
81.19 |
10.85 |
64 |
162 |
170 |
| 39.442 |
44 |
81.42 |
13.08 |
63 |
174 |
176 |
| 60.055 |
38 |
81.87 |
8.63 |
48 |
170 |
186 |
| 50.541 |
44 |
73.03 |
10.13 |
45 |
168 |
168 |
| 37.388 |
45 |
87.66 |
14.03 |
56 |
186 |
192 |
| 44.754 |
45 |
66.45 |
11.12 |
51 |
176 |
176 |
| 47.273 |
47 |
79.15 |
10.6 |
47 |
162 |
164 |
| 51.855 |
54 |
83.12 |
10.33 |
50 |
166 |
170 |
| 49.156 |
49 |
81.42 |
8.95 |
44 |
180 |
185 |
| 40.836 |
51 |
69.63 |
10.95 |
57 |
168 |
172 |
| 46.672 |
51 |
77.91 |
10 |
48 |
162 |
168 |
| 46.774 |
48 |
91.63 |
10.25 |
48 |
162 |
164 |
| 50.388 |
49 |
73.57 |
10.08 |
67 |
168 |
168 |
| 39.407 |
57 |
73.37 |
12.63 |
58 |
174 |
176 |
| 46.08 |
54 |
79.38 |
11.17 |
62 |
156 |
165 |
| 45.441 |
56 |
76.32 |
9.63 |
48 |
164 |
166 |
| 54.625 |
50 |
70.87 |
8.92 |
48 |
146 |
155 |
| 45.118 |
51 |
67.25 |
11.08 |
48 |
172 |
172 |
| 39.203 |
54 |
91.63 |
12.88 |
44 |
168 |
172 |
| 45.79 |
51 |
73.71 |
10.47 |
59 |
186 |
188 |
| 50.545 |
57 |
59.08 |
9.93 |
49 |
148 |
155 |
| 48.673 |
49 |
76.32 |
9.4 |
56 |
186 |
188 |
| 47.92 |
48 |
61.24 |
11.5 |
52 |
170 |
176 |
| 47.467 |
52 |
82.78 |
10.5 |
53 |
170 |
172 |