机器学习(3):聚类算法之K均值算法、层次聚类和密度聚类
最近自己会把自己个人博客中的文章陆陆续续的复制到CSDN上来,欢迎大家关注我的个人博客 zuzhiang.cn,以及我的github。
本文主要讲解有关聚类的相关算法,包括K均值聚类、层次聚类以及密度聚类等,除此之外,还会讲解聚类算法中的一些基本概念,以及聚类算法效果评判的一个标准——轮廓系数。
本文主要是依据李航老师的《统计学习方法》和邹博老师的机器学习教学视频总结编写的。文中所用到的有关机器学习的基本概念和方法可以参考本人博客中该系列之前的文章,或者直接上网搜索相关的内容。以下文章所列出的公式以及公式的推导读者们最好是在草稿本上自己推导一遍。由于本人水平所限,文章中难免有错误和不当之处,欢迎大家多多批评指正!
一、聚类定义
聚类就是对大量未标注的数据,按照数据内在的相似性,将其划分为多个类别,从而使类别内的数据相似度较大,而类别之间的数据相似度较小。它与分类算法的不同之处简单来说就是,分类是有监督学习 ,而聚类是无监督学习。聚类算法的基本思想是:对于给定的类别数K,首先对样本随机给出K个初始划分,并通过不断的迭代来更新每个样本所属的类别,从而使得每一次迭代后的划分结果要比前一次好。当迭代次数达到某个阈值,或者类别中心的变化小于某个阈值时,算法停止。
二、相似度/距离
聚类算法通常会根据两个样本点之间的相似性来进行分类,而描述两个样本点之间的相似程度的方式主要有以下几种:
1.样本间相似度
(1)).欧氏距离
两个点X和Y之间的欧氏距离可以由以下公式表示,其中和是两点在不同维度的坐标值,无疑两点之间的欧式距离越小,两点相似度越高。
(2).余弦相似度
两个向量a、b之间的余弦相似度公式如下,其中是两个向量之间的夹角(小于180°),余弦相似度的取值范围是[-1,1],其值越趋近于1,则两个向量越相似。
(3).相关系数
两个随机变量之间的相关系数公式如下,其中cov(X,Y)是两者的协方差,和是两者的标准差。相关系数的绝对值越趋近于1两者越相似,越趋近于0越不相似。
(4).杰卡德(Jaccard)系数
两个集合之间的杰卡德系数公式如下,分子分母分别为两个集合的交集和并集。
除了以上提到的之外,还有曼哈顿距离、相对熵和Hellinger距离等,就不在一一介绍了。
2.类别间距离
类和类之间的距离D(p,q),也称作连接,类与类之间的距离有以下几种:
(1).最短距离(单连接):定义两个类中样本的最短距离为类间距离。
(2).最长距离(完全连接):定义两个类中样本的最长距离为类间距离。
(3).中心距离:定义两个类的类别中心之间的距离为类间距离。
(4).平均距离:定义两个类中所有样本之间的平均值为类间距离。
三、K均值算法
K均值算法又称K-means算法,它的主要思想是事先选定k个类别中心,计算每个样本点距离类别中心的距离,并将其归类为距离最近的类别。然后重新计算类别中心(样本的均值),并重新对所有样本点进行分类,重复该过程直到样本中心的变化幅度小于某个阈值。值得注意的是,该算法中的K值是需要事先给定的。算法示意图如下:
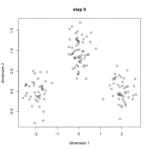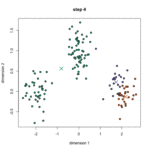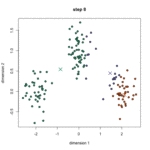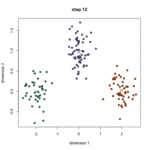
算法流程如下:
(1) 选择初试的K个类别中心 。类别中心就是就是同一类别中所有样本的均值;
(2) 对于每个样本,标记其所属的类别为距离他最近的类别中心所代表的类别,即:
(3) 更新每个类别的类别中心,将每个类别中心更新为隶属于该类别的所有样本的均值,即,其中为第j个类别(或者说簇);
(4) 重复(2)、(3)两步,直到类别中心的变化小于某阈值时结束算法,此时每个样本所属的类别就是最终它所在的分类。
在K均值算法中,通常采用欧氏距离的平方作为样本之间的距离,即:
而把样本距其所属类别中心之间的距离之和为损失函数,即:
公式中为第l个类别中心,表示所属类别为第l个类的样本对应的下标是i。因为每次迭代要求最优的类别中心,所以上式对求导为:
其中,是第l个类别所包含的样本个数。从梯度下降的角度看,上式是每次迭代类别中心应该进行的更新,而从算法流程的角度看,当上式中分子是1时,正好是更新后的类别中心计算公式,即类别中心=样本的均值。
四、层次聚类
层次聚类分为聚合的层次聚类和分裂的层次聚类两种。聚合的层次聚类采用一种自下而上的方式,先将每个样本各自分为一个类,之后将距离最近的两个类合并,建立一个新的类,重复以上操作直至满足停止条件。而分裂的层次聚类采用一种自上而下的方式,先将所有样本看作一个类,然后把已有类不断进行划分,形成新的类别,重复以上过程直到满足停止条件,这种方式不常用。聚合的层次聚类示意图如下:

五、密度聚类
密度聚类的指导思想是:只要样本点中的密度大于某个阈值,则将该样本添加到最近的簇中。这种聚类算法克服了在使用k-means等基于距离的算法时,只能发现“类圆形”的聚类的缺点,可以发现任意形状的聚类,并且对噪声数据不敏感。
DBSCAN是一种典型的密度聚类算法。DBSCAN是具有噪声的基于密度的聚类算法的缩写(不是数据库扫描的意思),他将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可以在有噪声(即分类结束后不包含在任何簇中的样本)的数据汇总发现任意形状的聚类。算法示意图如下:
1.DBSCAN算法中的若干概念
(1)样本的-邻域:以给定样本点为中心,以为半径的圆形区域;
(2)核心对象:如果一个对象的-邻域的密度超过某个临界值,即对象的-邻域内包含的样本点数量超过某个数值m,则称该对象为核心对象;
(3)直接密度可达:给定一个对象集合D,如果样本p是在样本q的-邻域内,而样本q是一个核心对象,则称对象p是从对象q出发直接密度可达的;
(4)密度可达:对于给定的半径和阈值m,如果一个对象经过多次直接密度可达,其中, 则称对象是从对象关于和m密度可达的;
(5)密度相连:对于给定的半径和阈值m,如果存在三个对象p、q和r,满足p和q都是从O关于和m密度可达的,那么对象p和q是关于和m密度相连的。
2.DBSCAN算法的流程
(1)通过计算每个样本点在-邻域内的密度,找出所有的核心对象,并把核心对象所在的-邻域标记为一个簇;
(2)合并所有的核心对象可以密度相连的簇;
(3)没有新点可以更新簇时,算法结束。
六、轮廓系数
评判一个聚类效果好坏的标准有很多,比较常用的是轮廓系数(silhouette)。
首先记第i个样本到同簇内其他样本的平均距离为,而到其他第j个簇内样本的平均距离为,,即b(i)为第i个样本到其他簇的平均距离的最小值。则第i个样本的轮廓系数为:
其中a(i)可以看作是凝聚度,而b(i)可以看作是分离度。