一图胜千言: don't waste my time, show me the image
为什么「以文搜图」如此重要?以文本的方式发出问题,再以图片的方式返回答案,这种信息获取范式,连我奶奶都说好。电商平台淘东西,找喜欢的宠物,租心仪的房子,学菜谱,找喜欢的短视频……不论是哪一类强交互的应用,图文的跨模态理解都是大幅提升用户体验的利器。
嗯,问题挺重要。但如果用传统技术做文本和图像的语义理解,在实际应用中还是稍微差了那么一点意思,所以直接硬刚去解决问题还是挺有挑战的。落地靠谱的解决方案多少都会迂回一下,并不尝试直接理解数据语义,而是通过协同过滤的方式,依赖大规模的用户浏览行为串起数据间的语义关联。这听起来有点先有鸡还是现有蛋的味道——对数据理解不到位,就很难建立用户粘性,但要理解到位,又要依赖大量的用户数据???
现实情况也确实如此,大规模图文的跨模态应用一直都是头部大厂的地盘,小一点的项目想玩转这套技术,启动都很困难。直到去年,OpenAI 丢了个 CLIP 模型到平静湖面,并告诉所有人,“我们搞了一套 4 亿规模的文本-图片对,大力出奇迹了一把,现在有了 CLIP,文本和图片之间的语义桥已经搭好了。”
关于本篇: 我们从哪里来,要到哪里去
「以文搜图」系列文章会从零到一地介绍如何应用 CLIP 构建大规模以文搜图服务,包括:
- 了解 搜索、CLIP,以及以文搜图
- 5 分钟完成以文搜图的原型
- 进阶 1:部署向量数据库,进行大规模向量召回
- 进阶 2:部署推理服务,让你的推理请求处理超过 1000 QPS
- 进阶 3:向量数据压缩
本篇是这个系列的开篇,会覆盖第一个主题。接下来,我们需要先积累一些基础知识,快速地建立对以下内容的基础理解,包括:搜索、CLIP、以文搜图的基础组件,一起来吧!
来点儿基础知识-1:搜索与语义相似
但凡讲到搜索,不论是传统的还是新派的,或是单一模态、跨模态的,都离不开一样东西:语义相似的度量,或者说,两样东西的语义距离。这听起来好像有点抽象,我们举几个例子。
让我们从一维的整数空间开始,这是从小学就刻在大家 DNA 里面的知识。给定 5 个正整数 { 1, 5, 6, 8, 10 },问,和 5 最接近的是哪个数字?(不用抢答 6,毕竟大家都是成年人......)

当年,老师会说,“ 5 和 6 之间的距离是 1,是所有数中和 5 距离最近的。” 这里提到的“距离 1 ”,就是 5 和 6 这两个东西的语义距离。
这好像有点小儿科,让我们甩开腿,再往前迈一步,看一看传统的文本搜索是怎么做的。如果你和搞文本搜索的朋友同学聊,那大概率会听到 TF-IDF 这么个词。这里面 TF 指的是 term frequency,也就是词频。想象有一个高维空间,这个空间的维度和字典中的词一样多。我们统计每篇文章中相同词语出现的次数,并将这个次数设为这个空间相应维度上的值。这样,我们可以将任何一篇文章描述为一个这个词向量空间上的稀疏向量(之所以稀疏,是因为通常每篇文章只能覆盖字典上很少的一部分词)。
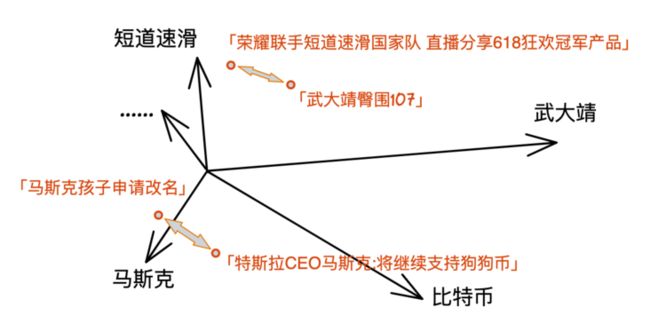
这是个非常朴素且实用的思路。如上图所示,如果两篇文章的领域或内容相近,那么在词向量空间中,这两篇文章对应的向量应该离得不远,如果两篇文章完全相同,那他们的词向量之间的距离为 0。在文本搜索中,我们将第一个例子的一维正整数空间扩展到了高维词向量空间,但搜索技术背后的套路是基本一致的:定义一个能用来描述数据语义的空间,再确定数据语义间的距离。
走到这一步,拍拍聪明的脑袋瓜,思路来了:我们甩开腿再往前迈一步,再泛化一下。既然文本搞定了,我们把图片的语义也投到词向量空间,这样不就能文本-图像跨模态了么?
思路没毛病,但是少了点东西。不用特别仔细看,我们就能发现图片和文本不一样,文本有“词”这个天生白送的自然语义基本单元,我们在这个基础上可以很容易搞上面说的词袋模型。但图片不一样,首先,像素明显不会像词那样一套就 work 了,其次,我们如果尝试提取图像中的图元,成本会很高,另外图片的结构化信息提取也很难做到全面、精准。
“没有自然语义单元,怎么向量化?” 在以前,这不仅仅是图片搜索的特有问题,而是非结构化数据应用的普遍问题,因为绝大多数数据类型(想想图片、视频、音频、点云这些数据)都不会天生存在自然的语义单元。这个问题直到数据、算力变得便宜,神经网络技术得到普及才得以有效解决。我们来看看通过神经网络是怎么解决这个问题的。

Convolutional Neural Network Layers and Architectures
深度神经网络,很大的一个特点就是“够深”。观察上图,左边输入是一张 224 x 224 的图片,右边输出是一个 4096 维的向量。从左到右,一张图片会经过很多的神经网络层,每往右一步,神经网络就会将原图片像素上的空间信息逐步压缩成语义信息。在这个过程中,可以看到空间维度越来越窄,语义维度越来越长(这个说法严格上讲不是特别准确,但是我没有找到更合适的表达)。本质上,这个过程就是一个将图片语义映射到一个具有 4096 维的实向量空间的过程。和前面讲的技术相比,通过深度神经网络对数据语义进行向量化编码,有几点明显优势:
- 不要求原始数据具备自然的,可直接分割的基础语义单元,例如 “词”。
- 对于“数据相似”的定义十分灵活,由模型的训练数据以及目标函数确定,可以面向应用特性定制。
- 数据向量化的过程即模型的推理过程,这个过程中的运算主要是矩阵运算,可以充分利用现代 GPU 的加速能力。
最后,我们来看一下 CLIP 在文本-图片跨模态这个领域做了哪些事。首先,在数据方面,OpenAI 搞了一套文本-图片跨模态的大规模数据集 WIT (WebImageText)。模型训练则采用了对比学习的方法,预测图片和文本是否配对。整个模型的设计还是非常简洁的。用通俗的话讲,这个模型包含三步,
1)文本和图片两路分别进行特征编码;
2)将文本、图片的特征从各自的单模态特征空间投射到一个多模态的特征空间;
3)在多模态的特征空间中,原本成对的图像文本(正样本)的特征向量之间的距离应该越近越好,互相不成对的图像文本(负样本)的特征向量之间的距离应该越远越好。

Learning Transferable Visual Models From Natural Language Supervision[1]
这里比较关键的是 2),通过投射层,将来自文本、图片的单模态特征投射到一个多模态的特征空间。从搜索的角度看,这意味着我们可以将图片和文本的语义映射到同一个高维空间。这个语义空间就是 CLIP 为文本-图片跨模态搜索准备的那座桥。现在,我们可以将一段描述性文本编码为一个向量,在通过这个向量找到附近具有近似语义的图片向量,再通过这些图片的向量找到我们想要的原始图片!
有点绕,我们总结一下。整体上看,还是经典套路,向量空间 + 语义相似的度量。重点在于,CLIP 帮我们搞了一个统一文本与图像语义的高维空间,在这个空间中,文本和图像的语义越接近,对应向量的距离越小。
到这里,我们所需的 CLIP 基础知识基本够用了。如果你觉得 CLIP 很酷,想来一个 CLIP 的 deep dive,墙裂建议观看李沐老师的论文精读系列[2]。
来点儿基础知识-2:以文搜图服务需要的基础组件
「以文搜图」顾名思义,所需要的基础组件涉及「文」「搜」「图」三部分。
先来看看「图」。「图」构成的是底库的部分,主要包含三套东西,一个是原始图片库,另一个是与原始图片相对应的向量库。中间是负责对原始图片进行语义向量化编码的模型推理服务。
「文」对应的是请求侧的内容。请求侧主要需要的是对文本进行语义向量化编码的模型推理服务。
「搜」对应的是连接请求、向量库、图片库的搜索过程。一条请求的文本,经过模型编码后,我们可以获得与请求对应的向量。我们拿这个向量到向量数据库进行近似搜索,获得 topK 个最近的图片向量。最后,通过向量-图片的ID关联,从图片库获得对应的原始图片(或图片url),组织请求的返回结果。

好了,本篇打基础的内容到这里就差不多结束了。在接下来的文章中,我们会结合本篇讲到的基础知识进行一次动手实践:5 分钟搭建以文搜图的原型。感谢观众老爷的观看学习!
更多项目更新及详细内容请关注我们的项目:https://github.com/towhee-io/...,您的关注是我们用爱发电的强大动力,欢迎 star, fork, slack 三连 :)
参考文献
[1] https://arxiv.org/pdf/2103.00...
[2] https://www.bilibili.com/vide...
Zilliz 以重新定义数据科学为愿景,致力于打造一家全球领先的开源技术创新公司,并通过开源和云原生解决方案为企业解锁非结构化数据的隐藏价值。
Zilliz 构建了 Milvus 向量数据库,以加快下一代数据平台的发展。Milvus 数据库是 LF AI & Data 基金会的毕业项目,能够管理大量非结构化数据集,在新药发现、推荐系统、聊天机器人等方面具有广泛的应用。