实例分割最全综述(入坑一载半,退坑止于此)
自21年年初从语义分割的舒适圈跳入实例分割方向至今,已经一年又半载了。
看过一些文章,跑过一些实验,至今没有产出。
思想挣扎过许多次,要不要继续,最终决定遗憾退场。
写一点东西,记一记往昔,弥补遗憾于万一。
文章目录
- 1. 实例分割简介
- 2. 二阶段实例分割
-
- 2.1 Mask R-CNN * * * * *
-
- (1) RoI Align
- (2) Mask 分支
- (3) 总结
- 2.2 Cascade Mask R-CNN * * * *
-
- (1) Motivation
- (2) Box级联
- (3) Mask级联
- (4) 总结
- 2.3 HTC * * * *
-
- (1) mask 信息流
- (2) 语义监督
- (3) 总结
- 3. 一阶段实例分割
-
- 3.1 局部mask与全局mask之争
- 3.2 YOLACT * * * * *
-
- (1) RetinaNet
- (2) 实例Mask系数
- (3) Mask特征
- (4) 实例Mask预测
- (5) 总结
- 3.2 BlendMask * * *
-
- (1) BlendMask vs YOLACT
- (2) 总结
- 3.3 EmbedMask * * *
-
- (1) 卷积 vs 聚类
- (2) 可学习实例聚类阈值
- (3) 总结
- 3.4 CondInst * * * *
-
- (1) Motivation
- (2) 模型结构
- (3) 总结
- 3.5 SOLOv2 * * * *
-
- (1) 网格正负样本分配策略
- (2) classification分支和mask分支
- (3) SOLOv2 动态卷积
- (4) 总结
- 4. Boundary Refinement
-
- 4.1 Pointrend * * * *
-
- (1) 测试阶段
- (2) 训练阶段
- (3) 总结
- 4.2 Refinemask \* \* \*
-
- (1) SFM(Semantic Fusion Module)
- (2) BAR(Boundary-Aware Refinement)
- (3) 总结
- 5. Contour-based实例分割
-
- 5.1 PolarMask * * * *
-
- (1) Polar Centerness
- (2) Polar IoU Loss
- (3) 总结
- 6. Query-Based实例分割
-
- 6.1 QueryInst * * * *
-
- (1) Box Head & Mask Head
- (2) 动态卷积
- (3) 总结
- 6.2 SOLQ * * *
-
- (1) Mask Resolution
- (2) Mask压缩算法
- (3) 总结
- 6.3 Mask2former * * * *
-
- (1) Pixel decoder
- (2) Transformer Decoder
-
- <1> masked attention
- <2> 调换self-attention和cross-attention的顺序
- (3) 采样点损失函数
- (4) 总结
- 5. 这一载半
- 6. 参考
1. 实例分割简介
实例分割是结合目标检测和语义分割的一个更高层级的任务。
- 目标检测:区分出不同实例,用box进行目标定位;
- 语义分割:区分出不同类别,用mask进行标记;
- 实例分割:区分出不同实例,用mask进行标记;
因此:
- 实例分割需要在目标检测的基础上用更精细的mask进行定位,而非bbox;
- 实例分割需要在语义分割的基础上区分开同类别不同实例的mask;
纵观实例分割的算法发展也是遵循这两条路线:
- 一类是基于目标检测的自上而下的方案:首先通过目标检测定位出每个实例所在的box,进而对box内部进行语义分割得到每个实例的mask;
- 另一类是基于语义分割的自下而上的方案:首先通过语义分割进行逐像素分类,进而通过聚类或其他度量学习手段区分开同类的不同实例;
考虑到基于语义分割的的自下而上的实例分割算法(如Semantic Instance Segmentation with a Discriminative Loss Function,Deep Watershed Transform for Instance Segmentation)通常后处理步骤繁琐,且效果较差,本文主要探讨的是基于目标检测的自上而下的实例分割算法。
本文按照所采用的目标检测网络将实例分割算法划分为二阶段实例分割,一阶段实例分割,Query-based 实例分割三大类进行介绍。除此之外,按照对实例分割mask的表征方式的不同,介绍 Contour-based 和 Boundary Refinement 实例分割。
除此之外,一些方法(如:FCIS,TensorMask,deepmask,AdaptIS,MEInst)也都是非常经典的工作,本文由于篇幅原因,并未涉及。
2. 二阶段实例分割
2.1 Mask R-CNN * * * * *

Mask R-CNN是典型的自上而下的实例分割算法,其扩展自目标检测网络Faster R-CNN,在其基础上新增了mask预测分支。
- Faster RCNN包含两个阶段, 第一个阶段, 是RPN结构, 用于生成RoI集合。第二个阶段利用RoI pooling从RoI中提出固定尺寸的特征, 然后进行class分类任务和box offset回归任务。
- Mask RCNN使用了相同的two-stage结构, 第一阶段使用了相同的RPN网络。第二阶段, 利用RoI Align从RoI中提出固定尺寸的特征, 在执行class分类和box offset 回归任务的同时,MaskRCNN还会给每个RoI生成对应的二值mask;
因此,Mask R-CNN的主要工作集中在RoI Align和mask分支的设计,以下分别进行介绍:
(1) RoI Align
由于RPN阶段得到的proposals box的大小是不一样的,而为了进行后续的class分类,box回归和mask分割任务,必须有一种操作将不同尺寸的box特征图归化到相同的空间尺寸以方便进行batch运算,RoI Pooling和RoI Align的作用就是如此。
RoI Pooling存在两次量化过程:
- 将box量化为整数坐标值;
- 将量化后的box区域分割成 k × k k\times k k×k个bins, 并对每一个bins的边界量化为整数;
RoI Pooling这种粗糙的量化方式对于Mask R-CNN新增的mask分支会产生很大的量化误差,因此,提出了RoI Align方法,取消RoI Pooling中涉及的两次量化操作, 使用双线性插值的方法获得坐标为浮点数的像素点上的图像数值,其具体流程如下:
- 遍历每一个候选区域, 保持浮点数边界不做量化;
- 将候选区域分割成 k × k k\times k k×k个bins, 每个bins的边界也不做量化;
- 在每个bins中sample四个point,使用双线性插值的方法计算出这四个位置的值, 然后取最大值;
(2) Mask 分支

由于mask分支需要对目标进行精细的mask预测,因此,mask分支采用比分类和回归分支更高的特征分辨率。具体来讲,将经过RPN阶段筛选出来的RoI经过RoI Align层将其尺寸统一为 14 × 14 14 \times 14 14×14,然后使用4层全卷积层和一层反卷积层以及最终的分类层为每个RoI预测一个 28 × 28 28 \times 28 28×28的mask。
(3) 总结
- Mask R-CNN提出一种极简的思路来进行实例分割,借助目标检测领域的成熟发展,可以通过简单的替换Mask R-CNN的Faster R-CNN为更优的检测器便可以稳定提升实例分割的指标。
- 但是,RoI Align为了将不同尺寸的RoI统一到相同的 28 × 28 28 \times 28 28×28尺寸进行batch运算,会导致大目标的空间特征出现信息损失,特别是在边缘部分,导致大目标特别是轮廓复杂的大目标的边缘预测效果较差。

2.2 Cascade Mask R-CNN * * * *
Cascade Mask R-CNN 也是探讨如何在检测器Cascade R-CNN基础上设计mask分支。
(1) Motivation
Cascade R-CNN主要针对 Faster R-CNN 中 R-CNN 部分采用单一 IoU 阈值进行正负样本选取会产生训练和测试过程中的不匹配的问题。 具体来讲:
- training阶段,RPN网络提出了2000左右的proposals,这些proposals在送入R-CNN结构前,需要首先计算每个Proposals和GT之间的IoU,并通过一个IoU阈值(如0.5)把这些Proposals分为正样本和负样本,并对这些正负样本按一定比例采样,进而送入R-CNN进行class分类和box回归。
- inference阶段,RPN网络提出了300左右的proposals,这些proposals被送直接入到R-CNN结构中,因为没有GT用于采样。
因此,此处所描述的不匹配问题就在于:
- training阶段的输入proposals质量更高(被采样过,IoU>threshold)
- inference阶段的输入proposals质量相对较差(没有被采样过,可能包括很多IoU
通常threshold取0.5时,mismatch问题还不会很严重。而为了得到更精准的box,最直接的办法就是提高正样本的IoU阈值,那此时的mismatch问题就会更加严重。同时,提高IoU阈值会导致满足阈值条件的proposals比之前少了许多,极容易产生过拟合。
(2) Box级联
上述的实验表明,由于采用单一的IoU阈值会产生mismatch的问题,因此,无法通过一味提升IoU阈值来获取更精准的box预测。本文提出一种级联结构,并在不同层逐渐增大IoU阈值,来缓解mismatch问题并产生更精确的box预测。
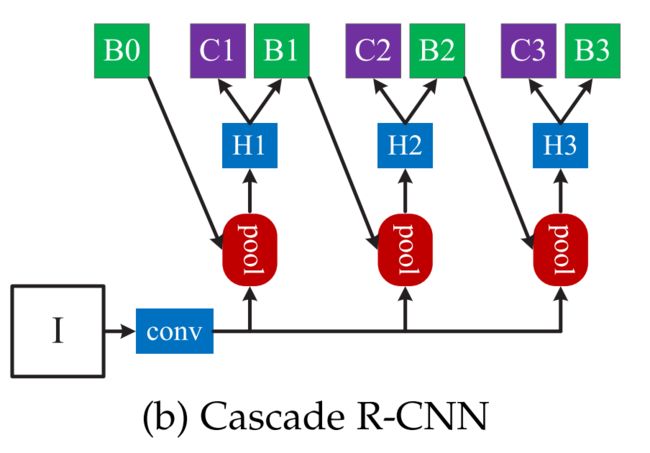
Cascade R-CNN的结构如上图所示,首先在不同的stage采用不同的IoU阈值,同时不同stage也采用不同的H(H表示R-CNN Head)。
(1) 递增IoU阈值
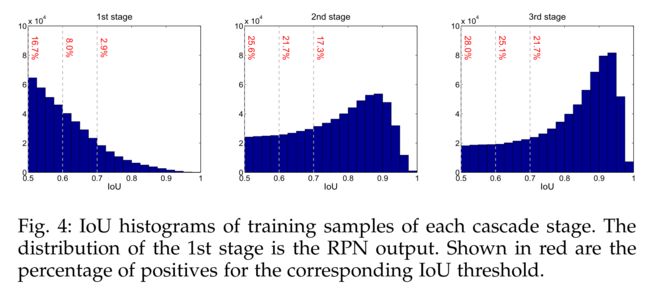
下图中,横轴 Input IoU 表示 RPN 输出的 proposal 与 gt bbox 的 IoU,纵轴 Output IoU 是经过 R-CNN 的 box 分支回归输出后与gt bbox 的 IoU,不同线条代表不同阈值训练出来的 detector。可以发现,Input IoU 在 0.55-0.6 范围内 proposal 阈值设置为 0.5 时 detector 性能最好,在 0.6~0.75 阈值为 0.6 的 detector 性能最佳,而到了 0.75 之后就是阈值为 0.7 的 detector 性能最好了。只有输入 proposal 自身的 IoU 分布和 detector 训练用的阈值 IoU 较为接近的时候,detector 性能才最好。

下图显示逐stage增大IoU后,正样本不仅没有减少,而且稍稍有增加。这是因为经过前一个stage的refinement,后一个stage的输出box变得更精确了,即与GT的IoU提升了。因此,Cascade R-CNN级联多个 R-CNN 模块,并且不断提高 IoU 阈值,不仅不会出现mismatch和过拟合,反而可以逐阶段修正box预测。
(2) 差异化R-CNN Head
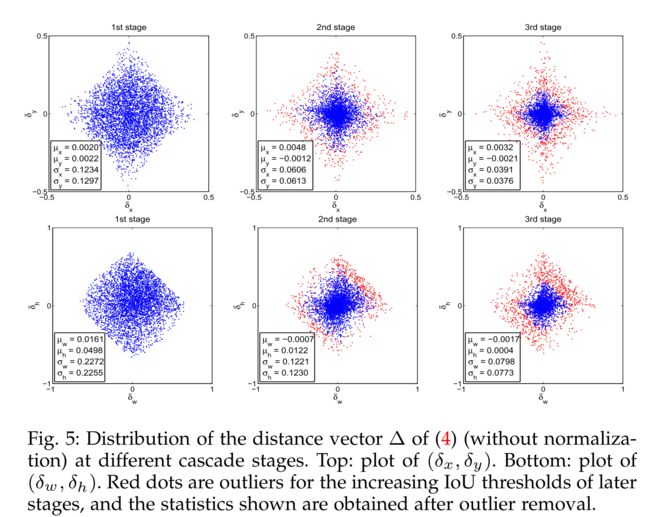
下图显示经过每个stage的R-CNN Head后,输入到R-CNN Head的样本分布会发生变化,因此,采用共享的R-CNN Head无法有效适配变化的样本分布问题。因此,Cascade R-CNN在每个stage都采用独立参数的R-CNN Head。
(3) Mask级联
为了将Cascade R-CNN目标检测器推广到实例分割,作者提出了(b)(c)(d)三种策略来新增mask分支。在测试时:
- (b)(c)(d)三种结构都只采用最后一个阶段输出的检测框裁剪RoI进行分割;
- 不同之处在于,(d)结构中,最后一个stage输出的RoI会送入三个mask分支分别进行预测,然后取均值进行ensemble。 (d)结构在文中的消融实验中也是性能最好的。

(4) 总结
- Cascade R-CNN通过级联box head 来进行逐阶段的box refinement;
- Cascade Mask R-CNN在其基础上添加级联mask head并在测试阶段对三个stage的mask预测概率进行均值集成。
- 然而,Cascade Mask R-CNN的三个stage的mask head之间没有类似box head的逐stage的refinement的过程,而是各自独立预测,最终进行集成,这也是后续HTC模型改进的关键点。
- 此外,Cascade Mask R-CNN仍然存在类似Mask R-CNN的大目标边缘预测粗糙的问题,这也是二阶段实例分割算法的通病。
2.3 HTC * * * *
HTC的主要创新点有两个:
- 设计mask分支的级联,以便将前一个stage的mask信息流传递到下一个stage;
- 添加语义分支和语义分割监督来增强特征的上下文语义特征;
下图中展示了在Cascade R-CNN的基础上添加mask分支的四种依次递进的设计:
- (a)图是标准的Cascade Mask R-CNN,当前 stage 会接受 RPN 或者 上一个 stage 回归过的框作为输入,并行预测box和mask;
- (b)图中在每个stage是将refine后的box输入到mask分支;
- (c)图在(b)图的基础上添加了mask分支之间的信息流,每次将前一个stage的mask特征输入到当前stage进行sum融合;
- (d)图进一步引入了语义分割监督,来增强mask分支的特征语义上下文信息;
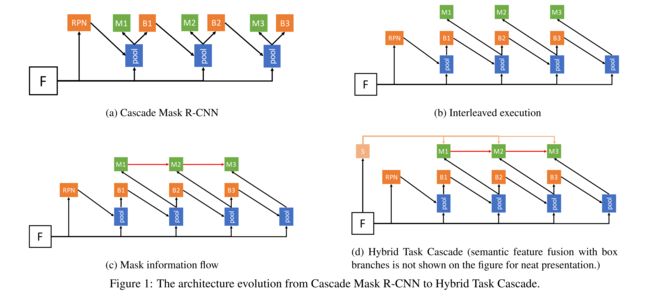
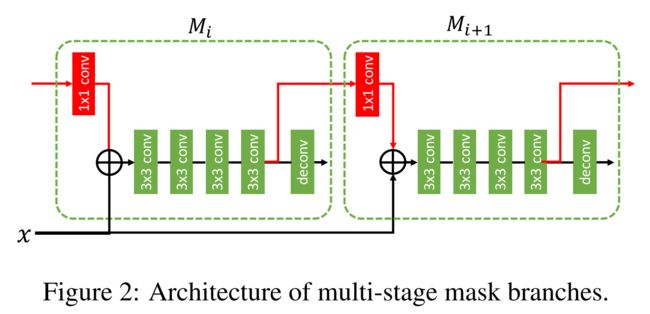
(1) mask 信息流
为了在不同stage的mask分支之间添加信息流,作者将前一个stage的特征 M i − 1 M_{i-1} Mi−1 ( 14 × 14 × 256 14\times14\times256 14×14×256)经过一个 1 × 1 1\times1 1×1卷积之后与当前stage RoI Align之后的特征 M i M_{i} Mi进行sum融合并输入到当前mask分支。
在实际训练时,前一个stage的RoI和当前stage的RoI并不一致,那么如果直接将前一个stage的特征拿过来与当前stage特征sum融合便会遇到空间不对齐的问题。因此,在实际训练过程中,需要用当前stage的RoI重新执行一遍前一个mask分支,这样就解决了mask特征不对齐的问题。测试时,与Cascade Mask R-CNN一致,只采用了最后一个stage的RoI输出,也不会遇到mask特征不对齐的问题。
(2) 语义监督
为更好的区分前背景,进一步将语义分割引入到实例分割框架中,以获得更好的 spatial context。具体来讲:
- 将FPN输出的不同level的特征图分别经过 1 × 1 1\times1 1×1后插值到同一分辨率并sum融合;
- 紧接着通过4层全卷积后,分别预测语义分割特征以及语义分割预测结果;
- 语义分割特征通过RoIAlign及element-wise sum与box、mask特征进行融合;
- 语义分割预测结果需要添加语义分割损失对该语义分支进行监督;

(3) 总结
- HTC算是二阶段实例分割的终结了,一直在COCO霸榜直至22年6月上旬被Mask DINO以微弱的优势超越;
- 二阶段实例分割采用RoI Align的通病就不再赘述;
- 本文所提出采用mask信息流级联与语义监督虽然都不是特别新颖的创新点,但是都可以作为实例分割算法的稳定提点策略;
3. 一阶段实例分割
3.1 局部mask与全局mask之争
在介绍一阶段实例分割前,我们引入局部mask和全局mask的概念,这也是二阶段实例分割与一阶段实例分割的本质差别。如果这一块看的时候有点懵逼,就先跳过,等看完一阶段部分再回来看也行。

(1) 局部mask
如上图所示,第二章介绍的二阶段实例分割采用的就是局部mask,将box内部的区域全部裁剪出来并通过RoI Align统一到相同的尺寸;
其优点是:
- mask分支简单易学:裁剪后的mask特征构成简单,只包含实例的前景和少量的背景,因此,mask分支设计简单,仅仅通过4层全卷积就可以得到mask;
- 小目标效果较好:Mask R-CNN输出的mask分辨率为 28 × 28 28\times28 28×28,COCO的小目标定义是 s i z e < 32 × 32 size<32\times32 size<32×32,换算到1/4特征图就是 8 × 8 8\times8 8×8,所以小目标特征在经过RoI Align后会被放大,细节特征就可以较好的保留。此外,由于目标撑满整个mask,小目标的mask在监督时不会遇到正负样本严重不均衡的状况。
其缺点是:
- 大目标效果差:RoI Align后的尺寸较小,会导致大目标特别是轮廓复杂的大目标边缘分割较为粗糙;
- box偏差:当box预测存在偏差时,仅仅对box内部进行实例mask预测无法预测box外的mask区域;
(2) 全局mask
全局mask不需要经过裁剪和RoI Align的过程,而是直接从整个特征图中预测某个实例。
其优点是:
- 大目标效果好:大目标的特征不会经过RoI Align操作导致细节特征严重丢失;而且大目标的损失函数优化时,正负样本还是相对均衡的。
其缺点是:
- 小目标效果差:为了减少计算量,全局mask通常在1/4或1/8特征图进行,小目标在此分辨率下边缘预测不佳;且交叉熵损失函数优化时会遇到背景负样本占据大多数的情况,优化效果不佳,需搭配Dice Loss这一类的损失函数进行优化;
- 加大了模型学习难度:局部mask分支获取到的特征是已经用box剔除了大部分背景的实例特征,是有box这个强先验加持的;而全局mask拿到的是全局特征,那么全局mask分支就还需要具备定位能力,分别解析出不同的实例。
3.2 YOLACT * * * * *
之所以这篇文章给了五星,是因为在我看来,YOLACT算是后来的BlendMask,EmbedMask,Condinst这一系列文章的雏形。这一系列方法都是通过预测一组实例特定的参数与共享的1/4或者1/8的全局特征通过某种操作(通道加权求和,卷积或者聚类等)来预测一组实例的mask。
如果上面这句话理解有点困难的话,再拿Mask R-CNN举个例子:
- 问 “Mask R-CNN是如何预测一组实例的mask的呢?” 答 “(1) 每个实例的特征都不一样;(2) 但所有实例共享相同的卷积参数;”
- 那我们扩展一下,问 “如果所有实例共享相同的特征的情况下如何预测一组实例mask呢?” 答 “那就要处理每个实例的卷积的卷积核参数不一样。”
- 继续扩展,问 “那每个实例的特征和卷积参数可不可以都不一样呢?”。答 “当然可以,这就是下文即将要介绍的文章BlendMask和QueryInst算法的思路。”
- 总结来讲,每个实例具有不同的mask区域,那么用于合成该实例的实例特征或者卷积操作的卷积核参数总有一个要是实例特定的,即随着实例的不同而变化的。当然了,这里的操作并不一定非得是卷积。
接下来详细看一下YOLACT是怎么用共享的全局特征来进行实例分割的。YOLACT是在目标检测网络RetinaNet的基础上进行改造的。
(1) RetinaNet
RetinaNet本质上是由ResNet+FPN+两个FCN子网络(分类和回归)组成:
- Backbone选择ResNet来作为特征提取网络;
- FPN用来产生更强的包含多尺度目标区域信息的feature map,包含 P 3 到 P 7 P_3到P_7 P3到P7;
- 最后在FPN的多个feature map上分别使用两个结构相同但是不共享参数的FCN子网络,从而完成目标框类别分类和bbox位置回归任务;
RetinaNet同时也是一个Anchor-based的模型:
- 不同分辨率上anchor的尺寸anchor-size: [ 32 , 64 , 128 , 256 , 512 ] [32,64,128,256,512] [32,64,128,256,512];
- 每个anchor-size对应着三种放缩系数scale: [ 2 0 , 2 1 / 3 , 2 2 / 3 ] [2^{0}, 2^{1/3}, 2^{2/3}] [20,21/3,22/3];
- 每个anchor-size对应着三种长宽比ratio: [ 0.5 , 1 , 2 ] [0.5, 1, 2] [0.5,1,2];
也就是说,在 P 3 到 P 7 P_3到P_7 P3到P7的每个特征图的每个像素网格上都会预设9个anchor:
- 每个anchor都会预测一个长度为c的类别向量(如下图分类分支预测的 W × H × c a W \times H \times ca W×H×ca, c 就 是 类 别 数 , a = 9 , 是 a n c h o r 数 c就是类别数,a=9,是anchor数 c就是类别数,a=9,是anchor数);
- 和一个长度为4的bbox回归向量(如下图回归分支预测的 W × H × 4 a W \times H \times 4a W×H×4a, 4 就 是 b o x 四 个 回 归 量 , a = 9 , 是 a n c h o r 数 4 就是box四个回归量,a=9,是anchor数 4就是box四个回归量,a=9,是anchor数)。
训练时的anchor正负样本分配策略如下:
- 当anchor与ground-truth的IoU大于等于0.5时,这一类anchor就是正样本;
- 若IoU在[0,0.4)这个区间内,这一类anchor就是负样本,也就是背景。
- IoU在[0.4,0.5)这个区间内的anchor在训练时是不计损失的。
(2) 实例Mask系数
实例mask系数就是在RetinaNet分类和回归分支的基础上,并行添加一个mask系数预测分支,也就是如上图所示,预测为 W × H × k a W \times H \times ka W×H×ka 的分支,即接下来的采用通道加权操作合成实例mask的通道加权的系数, k k k就是通道的数目。实际操作会对预测出来的系数采用 t a n h tanh tanh进行非线性变换。
(3) Mask特征
Mask特征直接在FPN P 3 P_3 P3特征图上接一个全卷积网络,将分辨率上采样至1/4并将通道映射为 k k k,最终的shape为 H × W × k H \times W \times k H×W×k。
(4) 实例Mask预测
最终的实例mask的预测就采用下图所示的公式合成:

- P就是(3)中预测的Mask特征,shape为 H × W × k H \times W \times k H×W×k;
- C为正样本的实例mask系数矩阵,shape为 n × k n \times k n×k;
- σ σ σ为sigmoid激活函数;
这个矩阵乘法背后的含义就是对预测的mask特征的每个通道采用对应的mask系数进行加权求和,其本质就是一个 1 × 1 × k × 1 1 \times 1 \times k \times 1 1×1×k×1 的卷积操作,卷积核为 1 1 1,输入通道为 k k k,输出通道也为 1 1 1。
(5) 总结
- YOLACT通过预测一组实例特定的mask加权系数与共享的全局mask特征来生成实例mask,省去了RoI Align生成局部特征图的过程,网络简洁,速度实时;
- 由于YOLACT采用的RetinaNet检测网络的性能本身较差,YOLACT的整体指标与二阶段Mask R-CNN相比还是差了许多的, 29.8 29.8 29.8 vs 35.7 35.7 35.7。
3.2 BlendMask * * *
BlendMask与YOLACT整体来讲是很像的,给检测head部分新增一个实例相关的参数(Boxes Attens)预测分支,在1/4特征图上生成mask特征(Bases)。接下来照旧挨个模块简介一下:
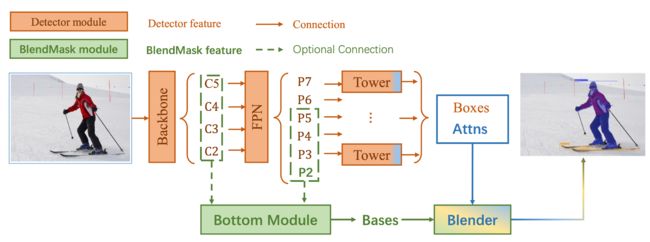
(1) BlendMask vs YOLACT
- 目标检测网络由RetinaNet替换为FCOS;
- mask特征(Bases)的生成由YOLACT的几层简单的卷积替换为DeepLab V3+的decoder模块,也就是ASPP模块,能够产生更强的上下文语义特征。shape为 H × W × K H \times W \times K H×W×K。论文最终采用的 K = 4 K=4 K=4,这是一个令人惊讶的通道数字,难以想象这么少的通道可以支撑最终的实例mask预测效果;
- mask系数(Boxes Attens)也由原本简单的每个通道一个的加权系数变成每个像素每个通道一个加权系数,粒度更细,即Boxes Attens已经学习出了实例空间位置分布信息。shape为 n × ( M × M × K ) n \times (M \times M \times K) n×(M×M×K), n n n 是正样本实例的数目;
- mask合成这一块比YOLACT要复杂一些,将 H × W × K H \times W \times K H×W×K的mask特征用RoI Align裁剪并缩放为 R × R × K R \times R \times K R×R×K,R最终设置为 56 × 56 56 \times 56 56×56,Boxes Attens本身的shape为 n × ( M × M × K ) n \times (M \times M \times K) n×(M×M×K), M比R要小,这里设置为14,这主要是为了减少Boxes Attens预测分支的计算量和预测难度,所以这里需要先将Boxes Attens插值为 n × ( R × R × K ) n \times (R \times R \times K) n×(R×R×K),最终便可以如下图所示合成实例mask n × R × R n \times R \times R n×R×R。

(2) 总结
- BlendMask不知道该说他是大杂烩还是集大成者,既有YOLACT似的实例mask系数预测,也存在Mask R-CNN似的RoI Align与局部mask;
- 虽然BlendMask采用了RoI Align,但是其采用的尺寸是 56 56 56, 比Mask R-CNN这一类方法采用 28 28 28还是要精细一些的;
3.3 EmbedMask * * *
EmbedMask与YOLACT同样很相似,不同之处在于:
- YOLACT采用共享全局特征与实例mask系数通过通道加权组合得到实例mask。之前讲过,这个通道加权相当于一个 1 × 1 1 \times 1 1×1 卷积;
- EmbedMask也是要预测一组实例特定的参数与全局共享特征图通过某种操作来得到实例mask,不过此处的操作不是卷积,而是聚类操作。具体来讲,给每个实例学习一组向量(相当于类心向量),然后计算实例向量与每个像素的向量之间的欧式距离,当距离小于给定阈值时则认为当前像素属于当前实例。
(1) 卷积 vs 聚类
EmbedMask的详细网络结构如下,基于FCOS目标检测网络进行实例分割设计,蓝色的部分是新添加的模块,主要包含实例Embedding预测模块(Proposal Embedding),全局特征图生成模块(Pixel Embedding),以及可学习实例聚类阈值预测模块(Proposal Margin)三个模块。

- 全局特征图生成模块(Pixel Embedding):采用 P 3 P_3 P3作为输入,后接4层 3 × 3 3 \times 3 3×3 卷积层得到,最终的shape为 H × W × D H \times W \times D H×W×D;
- Embedding预测模块(Proposal Embedding):在FCOS原有检测head(classification+box regression+centerness)的基础上新增一个分支,给每个像素(FCOS每个像素视为一个anchor,可以预测一个实例)预测一个实例embedding,那么正样本(FCOS正样本选取方式请移步FCOS原文)的实例embedding就构成了一个 n × D n \times D n×D的矩阵;
- 实例mask合成:有了实例embedding和pixel embedding,那么最直接的做法就是采用下列的公式来合成实例的mask。具体的逻辑就是聚类那一套,只不过这里我把类心也给你了,不用像kmeans一样反复优化类心了。当某个像素embedding与某个实例embedding的距离小于给定阈值时,就可以将该像素归属于该实例,这样就可以得到每个实例的mask。

(2) 可学习实例聚类阈值
(1)中介绍的是一种固定阈值聚类方案,那么,如下图所示(虚线圆半径代表聚类阈值),大目标应该用大的阈值,小目标应该用小的阈值。阈值取得大了,小目标就会和其他目标混淆被分割出来,阈值取得小了,大目标只能分割出一部分来。那么,可学习的阈值就应运上马了。

可学习实例聚类阈值(Proposal Margin)是由Box Regression经过1x1的卷积后得到。为了让阈值可学习,需要将阈值作为参数整合入损失函数并且是一个可导的过程。 EmbedMask参考了Instance segmentation by jointly optimiz- ing spatial embeddings and clustering bandwidth这篇文章的做法,采用高斯分布对像素embedding p i p_i pi,实例embedding Q k Q_k Qk以及可学习实例阈值 Σ k Σ_k Σk建模出 φ ( x i , S k ) φ(x_i, S_k) φ(xi,Sk),代表像素 x i x_i xi 属于实例 S k S_k Sk 的概率,某个像素的embedding与实例embedding距离越近,属于该实例的概率就越大。

这里关于 φ ( x i , S k ) φ(x_i, S_k) φ(xi,Sk)还有一些细节,上述的公式里面的实例embedding Q k Q_k Qk 并非某个位置(每个像素作为anchor预测一个实例)处预测出来的实例embedding,这是因为FCOS会给每个GT匹配到多个正样本位置,每个位置都会预测出一个实例embedding,按理他们应该一致的,但是这些属于同一目标的正样本预测出来embedding很难保证一致,那么如果同一个实例目标采用多个实例embedding与pixel embedding计算距离,那pixel embedding到底该与哪个位置预测的实例embedding学习的更接近呢,that’s a problem! 因此这里的 Q k Q_k Qk 和 Σ k Σ_k Σk实际上是属于某个实例GT的所有正样本预测的实例embedding和实例阈值的平均值,如下图所示。

- N k N_k Nk 就是属于当前实例 S k S_k Sk 的正样本的数目;
- q j q_j qj就是某个位置预测的实例embedding;
- σ j σ_j σj就是某个位置预测的实例阈值;
最终的mask分支的损失函数如下:
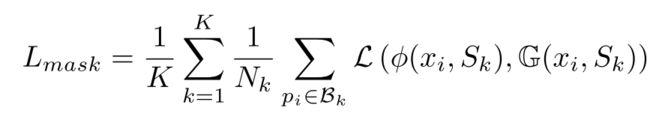
- G ( x i , S k ) G(x_i, S_k) G(xi,Sk) 就是像素点 x i x_i xi属于实例 S k S_k Sk的真值;
此外,由于在训练期间的 Q k Q_k Qk、 Σ k Σ_k Σk与测试期间的 Q k Q_k Qk、 Σ k Σ_k Σk是不一致的,测试期间就直接是当前位置预测的实例embedding q j q_j qj 和实例阈值 σ j σ_j σj,因此,在训练期间还要加一个损失函数来约束所有正样本预测的实例embedding q j q_j qj 和实例阈值 σ j σ_j σj尽可能的接近均值,公式如下:

(3) 总结
- EmbedMask采用预YOLACT系列文章相似的做法,只不过合成实例mask的方式变成了聚类,想法新颖,也确实可行。这也为其他方法探索除了卷积和聚类之外的其他动态操作提供了可能,如动态BN(AdadpIS),动态ReLU,特征图共享,BN和ReLU的参数是依据实例预测的;
- 但是,聚类操作的类心embedding和pixel embedding都是给定的,那就是要求mask特征图已经能够准确将不同实例区分开了。这在一些实例与背景差异比较大的情况下可行,但是当不同实例,特别是同类别实例挨得比较近的情况下,特征边界往往很难明显划分。
- 而且,聚类操作嵌入到模型中,相比于卷积操作来讲不够自然,需要进行更多的后处理操作,如本文的高斯概率映射。
3.4 CondInst * * * *
(1) Motivation
当两个属于同一类别的目标同时出现时,要想将两者进行实例层面的区分,上述已经介绍的方法的解决思路如下:
- 二阶段的方法通过RoI Cropping将目标区分开来,这样相当于显式引入了实例的box位置先验信息;
- YOLACT这一类的一阶段方法并没有实例位置先验信息,所以只能强行让不同实例的语义特征学习的足够差异化;
那么,也给YOLACT这一类的一阶段方法引入位置先验信息,就可以减缓同类目标语义特征学习的足够差异化的压力,也就是说,两个同类目标虽然语义特征相似,但是位置特征是不同的,那这样也可以将两者在实例层面区分开来。
(2) 模型结构
- CondInst同样采用FCOS作为目标检测网络;
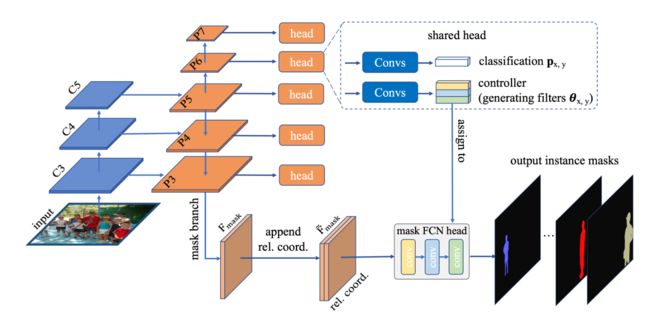
- CondInst的全局特征图同时包含语义特征和位置特征:
- YOLACT只采用了P3的语义特征;
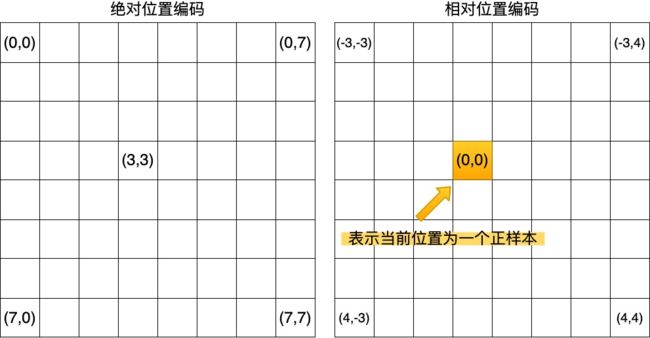
- CondInst在此基础上引入了相对位置特征。效果如下, ( 0 , 0 ) (0,0) (0,0)点就是某个正样本box的中心,那么特征图上同样一个位置在两个不同的正样本下计算出来的相对位置坐标是不一样。
- 那么此处的相对位置特征相当于一种隐式的位置编码,而且只利用了box的 c e n t e r x center_x centerx和 c e n t e r y center_y centery信息,并没有利用box的w和h信息。也就是说,此处的相对位置特征相当于告诉实例模型,距离当前实例box中心点越近的像素越有可能属于当前实例,但是模型并不清楚,到底离实例box中心点远到什么程度的像素点就肯定不属于当前实例了, w w w和 h h h信息显然可以解决这个问题,感兴趣的朋友可以尝试一下。
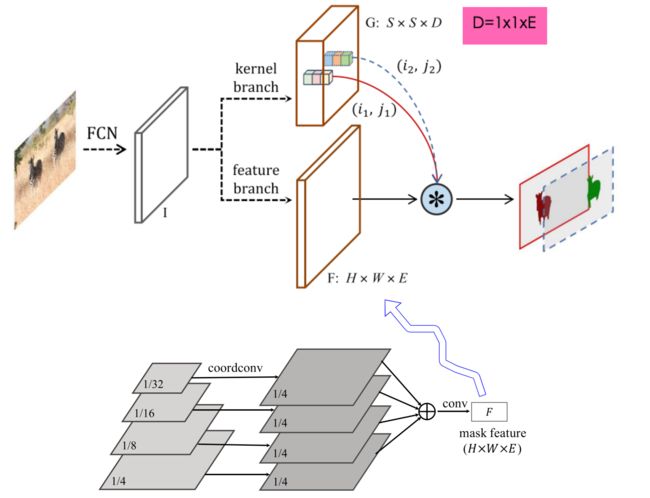
- Controller Head:CondInst类似YOLACT在检测head部分添加了一个并行的分支用来学习每个实例特定的动态卷积参数。此处的动态卷积与YOLACT中的mask系数是相似的操作:
- 虽然YOLACT的mask系数相当于 1 × 1 × k × 1 1 \times 1 \times k \times1 1×1×k×1 的卷积,但是YOLACT当时可能并没想那么深入;
- CondInst明确了在此处使用动态卷积的方案,直接学习了三层 1 × 1 1 \times 1 1×1 所需的weights和biases共计 169 169 169 个参数,具体构成如下:(8是指语义特征channel为8,相对位置特征channel为2);

(3) 总结
- CondInst兼具YOLACT的简洁结构与实用性能(超过Mask R-CNN);
- CondInst最终采用的特征图channel数为8,这并不是为了彰显模型的强大(能够在少量的通道情况下得到不错的效果),更多的原因是CondInst在实现过程中涉及到repeat操作,需要将特征图复制正样本的数目那么多份,如果通道数太多,肯定行不通的。
- 至于为什么要repeat,主要是因为YOLACT,CondInst都是只将正样本输入到mask head,但是不同图片输出的正样本数目不一致,那就的需要在batch维度加一个for循环(时间成本增加),或者直接将特征图repeat多份(内存增加)。下图整理了几种全局mask具体生成实例mask的方案。
- YOLACT可以采用for循环或者repeat两种方案;
- CondInst只能采用repeat的方案,这主要是因为其采用了多层卷积,实现层面必须用组卷积来实现,也就必须要进行repeat;
- Mask2former还没介绍,这里简单提一下,该算法在每张图设置固定的proposal数目,每次将所有proposal输入到mask head,并且采用类似YOLACT的mask组合系数( 1 × 1 × k × 1 1 \times 1 \times k \times1 1×1×k×1),所以并不涉及for循环或者repeat。
- 这实际上是一个balanced的过程:
- CondInst的卷积层更多,由于实现限制只能采用较少的特征图通道;
- Mask2former直接一步bmm,所以通道可以保持正常的256;
- 通道肯定多点好啦,特别是对于颜色复杂的大目标,具体合成实例mask的卷积操作也是一样啦,卷积层越多,能够对特征的变化和拟合就越强,如果能找到一种实现方式,同时采用多层卷积操作和大channel就最好啦。

3.5 SOLOv2 * * * *
SOLO共出了两个版本,v1跟本章前面的几篇文章相关性都不大,v2在v1的基础上引入了动态卷积的方案。那就先介绍一下v1:
SOLOv1在网格上进行实例分割的方案有点类似YOLO,都是在网格上进行实例目标的检出,SOLOv1是做实例分割,YOLO是进行目标检测。但是SOLOv1并不像CondInst这一类方法,其并没有保留目标检测网络的bbox分支,而是只有分类分支和mask分支。 接下来分别从SOLOv1的网格正负样本分配和classification分支及mask分支的设计两个方面展开。
(1) 网格正负样本分配策略
具体来讲,SOLO会首先将FPN不同层的特征图等分为 S × S S \times S S×S 个格子。正负样本的分配涉及到两个方面:
- 一是FPN同一层正负样本分配的策略;
- 二是FPN不同层正负样本分配的策略;
FPN同一层:
对于给定gt mask的质心、宽度w和高度h,设置比例因子,如0.2。被缩小后的box覆盖住的几个格子就是正样本,每一个gt平均有3个正样本。
FPN不同层:
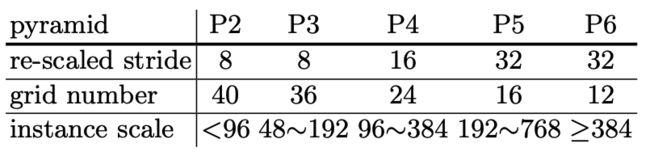
但是,如果两个目标同时覆盖某个网格呢,为了处理这种情况,作者首先做了个统计:在验证集中,绝大多数(约98.9%)的实例要么中心位置不同,要么大小不同。 因此,如果两个目标中心位置接近,那就通过尺度将其分配到FPN的不同层去,这样就能解决掉98.9%的冲突。
论文设置scale_ranges=((1, 96), (48, 192), (96, 384), (192, 768), (384, 2048)),分别对应不同FPN的输出层。当实例的尺度落入某一个区间,则该FPN分支负责该实例的预测。由于不同区间存在重叠的情况,因此会存在不同FPN层预测相同的目标,这样同样会增加正样本的数量。
(2) classification分支和mask分支
- classification分支通过(7+1)层全卷积给每个网格预测一个C维向量,最终classification分支的输出为 S × S × C S \times S \times C S×S×C;
- mask分支同样采用(7+1)层全卷积,不过输入特征图叠加了两个channel的位置特征,最终输出的shape为 H × W × S 2 H \times W \times S^2 H×W×S2,也就是说像语义分割的思想,语义分割是预测每个像素属于每个类别的概率,这里是预测每个像素属于每个网格实例的概率;
- 可以看出缩小后的飞机的box落入的两个网格对应的mask预测的通道就会预测出整个飞机的mask,在测试阶段需要采用NMS对重复预测进行消除;
那么这里问题也是比较明显的,如下图所示,mask 分支在P2特征图上需要预测了 40 × 40 = 1600 40 \times 40 = 1600 40×40=1600 个channels,这个计算量和显存占用也太大了。
因此,作者提出了Decoupled head,不直接预测 S 2 S^2 S2 个channels了,只预测 2 S 2S 2S 个channels。那么处于 ( i , j ) (i, j) (i,j) 位置的网格对应的mask预测就由Y分支的第 i i i 个通道和X分支的第 j j j个 通道预测的mask进行element-wise乘即可。

(3) SOLOv2 动态卷积
SOLOv2采用类似CondInst的动态卷积方式,给每个网格代表的实例预测一组卷积参数,将其FPN各个分辨率融合后的特征图进行动态卷积来得到实例mask。
(4) 总结

SOLOv2的mAP刚刚与Mask R-CNN齐平,但是在小目标和大目标的性能上出现了明显的反差
- 对于小目标效果差,我认为这是由于SOLOv2始终没有放弃网格的方案导致的,网格稀疏的情况下会导致小目标的召回率较低,网格过密计算代价就高了;
- 大目标效果好,我认为有三方面原因:
- 一方面是由于采用全局mask,会比Mask R-CNN好是自然的;
- 另一方面是预测实例mask的特征是FPN融合后的,比仅使用1/4特征图语义信息更丰富;
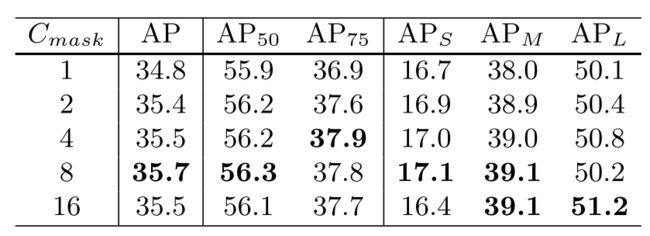
- 最后是与同为全局mask的condinst相比的,SOLOv2的特征图通道为256,这能够编码更丰富的信息相比于CondInst的8个通道。下图是CondInst中关于通道数的一个超参实验,当通道数为16时, A P L AP_L APL能产生一个点的提升相比于通道数为8时;
4. Boundary Refinement
二阶段的实例分割算法最终输出的mask分辨率皆为 28 × 28 28 \times 28 28×28,这会导致一些目标的边缘预测不佳。因此,存在一系列方法对此进行修复,本文介绍此方向两篇经典且有效的工作:Pointrend和Refinemask,他们的基本思路都是进行crose to fine的refinement,既然 28 × 28 28 \times 28 28×28分辨率太低,那就往大的搞, 112 × 112 112 \times 112 112×112总可以了吧,不行就 224 × 224 224 \times 224 224×224。
4.1 Pointrend * * * *
Pointrend将图像分割视作渲染问题,我们直接透过故事包装看其实质做法。
(1) 测试阶段
Pointrend在测试阶段的步骤可以分为以下几步:
- 直接上采样:Pointrend迭代地将实例mask进行二倍双线性插值上采样(从 7 × 7 7 \times 7 7×7 到 224 × 224 224 \times 224 224×224共计上采样 5 5 5 次);
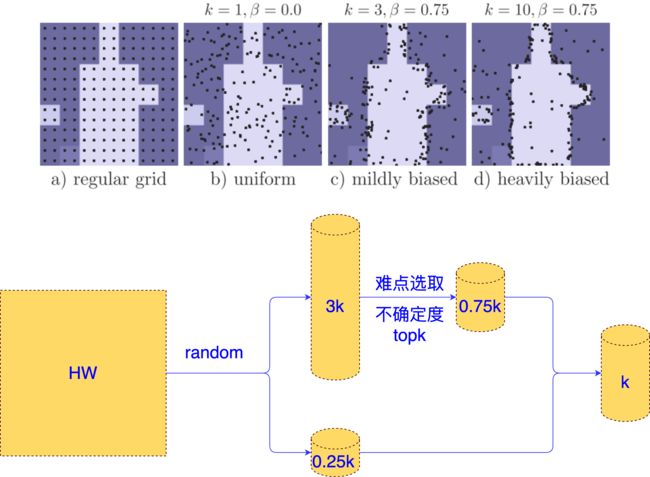
- 难点选取:每次上采样后,挑选出 N 个“难点”,即预测置信度在0.5附近的点,这些点处于摇摆不定的状态,不确定到底是前景还是背景,从下面的可视化来看,这些点通常处于物体边缘。
- 难点特征构造:对于每个难点,其特征由两个部分组成:
- fine-grained features:从1/4高分辨率特征图插值得到;
- coarse prediction:由上一个低分辨率层预测得到的mask logits插值得到;
- 难点再预测:使用 MLP 对难点特征进行重新预测,并更新直接上采样后的特征图。

(2) 训练阶段
Pointrend的核心思想体现在测试阶段,即迭代地对直接双线性插值后的mask上的不确定点以二次预测的方式进行修复,以得到良好的物体边缘。换句话说,相当于在coarse to fine refinement的过程中加入了cascade hard example mining。
考虑到测试期间每次迭代的MLP网络都是共享的,训练期间并没有采用迭代修复的过程,只是在单个分辨率( 7 × 7 7 \times 7 7×7)选取一批难点,并构造难点特征输入到一个MLP网络进行难点再预测。
- 训练难点选取:训练期间每次选取75%的难点搭配25%的背景点。75%的难点是从图像中选取不确定度 Top 75 % k 75\%k 75%k 的点,为了降低计算量,实际是先随机抽取的 3 k 3k 3k 个点计算不确定度,再从中抽取Top 75 % k 75\%k 75%k 的点。
- MLP:四层全连接层,监督方面直接从GT mask中插值出 k k k 个点的真值对预测进行监督。
(3) 总结
- 本质而言,Pointrend就是在coarse to fine refinement的过程中加入了cascade hard example mining。
- 这种仅对难点进行优化的方式相比于直接输出高分辨率mask,内存占用更少且计算速度更快。
4.2 Refinemask * * *
RefineMask网络结构如下,其也是考虑到Mask R-CNN输出的mask分辨率太低,进行了以下改进:
- 通过级联上采样的方式从 14 × 14 14 \times 14 14×14 的初始mask分辨率恢复出 112 × 112 112 \times 112 112×112 的mask;
- 增加了semantic head,用于提取整张输入图像的语义信息,并辅助 mask head 进行分割;
- 使用SFM(Semantic Fusion Module)融合 mask head 和 semantic head 的特征进行预测;
- 使用 BAR(Boundary-Aware Refinement)提高网络对mask边界细节的预测能力;
(1) SFM(Semantic Fusion Module)
SFM包含4个输入:(1)instance feature,(2)instance mask,(3)semantic feature,(4)semantic mask,其均是通过RoI Align得到的。
SFM模块具体操作是将四个部分的输入concat到一起然后通过三路并行的扩张卷积(输出通道254),用于提取不同感受野的特征,最终将instance mask和semantic mask再次concat输出(最终输出通道256)。
(2) BAR(Boundary-Aware Refinement)
在训练期间,RefineMask共计会输出 14 × 14 14 \times 14 14×14, 28 × 28 28 \times 28 28×28, 56 × 56 56 \times 56 56×56, 112 × 112 112 \times 112 112×112 四个分辨率的预测,其中, 14 × 14 14 \times 14 14×14 和 28 × 28 28 \times 28 28×28的instance mask监督与Mask R-CNN一致,但是 56 × 56 56 \times 56 56×56 和 112 × 112 112 \times 112 112×112 预测的instance mask仅包含边界区域,其真值范围是边界线两侧n个像素宽的区域。
在测试期间,考虑到低分辨率特征预测的内部信息更加连续,高分辨率特征预测的边缘信息更加准确,因此,融合 28 × 28 28 \times 28 28×28 的mask预测的内部区域与 56 × 56 56 \times 56 56×56 的mask预测的边界区域来获取得到 56 × 56 56 \times 56 56×56 的mask,同理可以得到最终的 112 × 112 112 \times 112 112×112 的maks。
(3) 总结
- RefineMask与Pointrend实际上是殊途同归,都是通过crose to fine的级联上采样来优化Mask R-CNN输出的maks边缘。区别之处在于:
- Pointrend是通过选取高不确定度的点来关注目标边缘;
- RefineMask是通过显式的边界区域监督来关注目标边缘 。
- RefineMask在全程都是在feature map层面进行操作,相比于point层面的Pointrend来讲,需要耗费更多的显存和计算量。
5. Contour-based实例分割
之前介绍的无论是二阶段还是一阶段实例分割都是从mask(局部mask or 全局mask)的层面来表征一个实例,在实例分割领域里,还有一类方法是从轮廓的角度来表征实例mask,这也更贴近人工用labelme进行分割标注的过程。本章仅介绍该方向思想最简洁且有效的算法PolarMask,还有一些方法,比如Curve-GCN和Deep Snakes,这些方法通常需要繁杂的算法流程(首先给定一个initial contour,网络对图片提取feature map,然后在contour上的每个节点提取一个feature,也就得到了定义在contour上的一组feature,紧接着通过GCN或者卷积给每个节点预测一个offset来变形contour)",在本章不做介绍。
5.1 PolarMask * * * *
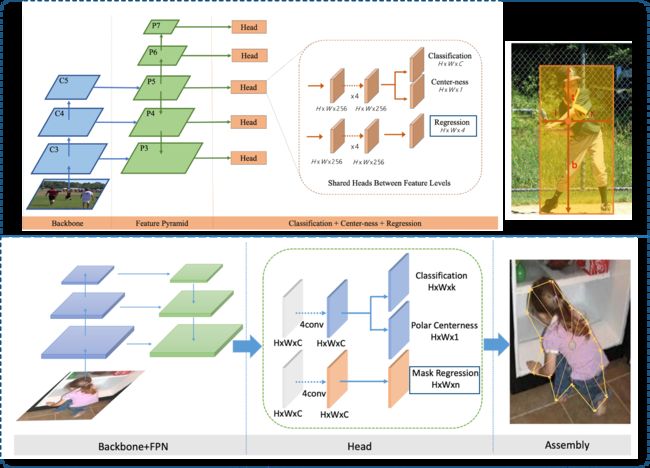
PolarMask对目标检测网络FCOS进行了简单的扩展实现了目标检测和实例分割架构的统一。如下图所示:
- FCOS是预测从目标中心出发到box边界的四条射线(90度为间隔)的距离;
- PolarMask是预测从目标中心出发到mask轮廓的36条射线(10度为间隔)的距离;
因此,两者的网络结构的改动很小,即将FCOS的回归分支的回归量从 H × W × 4 H \times W \times 4 H×W×4 变为 H × W × n H \times W \times n H×W×n, n n n 代表的是回归实例轮廓的射线的条数。
除此之外,PolarMask和FCOS还有以下几点不同:
- 中心点不同:FCOS采用box中心,而PolarMask采用mask重心,因为除了一些凹形或者环形物体外,重心相比于box的中心,有更大概率落在物体内部;
- centerness不同:将FCOS采用四条射线长度构造centerness泛化为采用 n n n 条射线长度构造用于实例分割的centerness;
- IoU loss不同:将FCOS计算box之间的IoU loss泛化为计算Polar mask 之间的IoU loss;
(1) Polar Centerness
Polar centerness可以抑制(通过与classification score相乘)左下角的图中间所示的红色射线的这种射线出发点严重偏离实例中心点的情况。因为这种例子往往难以优化并且会产生低质量的mask。
(2) Polar IoU Loss
对于Polar Mask 回归分支最常用的loss就是smooth-l1和IoU loss。 然而,smooth-l1损失忽略了同一目标36条射线之间的相关性,从而导致定位精度较低。 IoU损失能够将36条射线当做一个整体来优化,并且可以直接优化IoU指标(mAP内部依赖IoU进行mask排序)。 本文针对Polar Mask提出了一个Polar IoU Loss,如下图所示:
(3) 总结
- PolarMask将实例分割问题转换为估计一个实例的质心以及从质心出发的多条射线的长度,实现了目标检测和实例分割架构的统一,算法创新性和简洁度不言而喻。
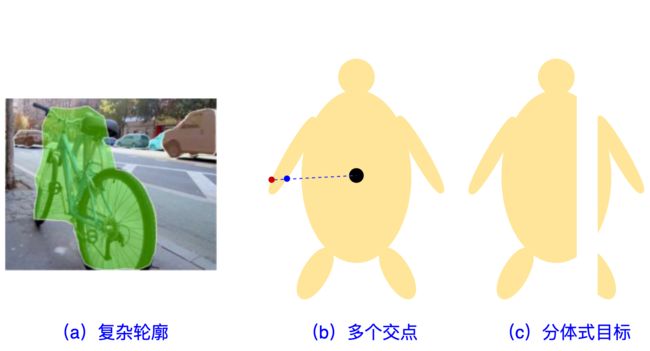
- 但是,用这种极坐标或者说多边形的方式对于可能出现的各种复杂mask要不边缘拟合效果不佳(a),要不无能为力(b, c)。
6. Query-Based实例分割
Query-based方法均是起源于目标检测网络DETR(参考以前写的一篇文章https://niecongchong.blog.csdn.net/article/details/118611442)),其通过初始化一组(如100个)可学习的query,并采用Transformer结构对query特征进行迭代更新,进而对每个query进行回归和分类,这样就可以对每张图输出固定数目的检测结果,最终,通过与GT之间的匈牙利匹配来实现label assignment。由于DETR收敛时间极慢(500epoch),在DETR之后有一系列方法针对其进行改进,Sparse RCNN,Deformable DETR,Adamixer,DINO是其中比较经典的工作。
本章所介绍的三篇文章中,QueryInst是Sparse RCNN的基础上的工作,SOLQ是Deformable DETR基础上的工作,Mask2former则是自成一家,且类似SOLO阉割掉了检测分支。
6.1 QueryInst * * * *
QueryInst之于Sparse RCNN的角色极其类似于Mask R-CNN之于Faster R-CNN,也就是说,QueryInst是结合Sparse RCNN和局部mask(RoI Align)的产物。
下图呈现了QueryInst的模型整体结构:
- Backbone:ResNet50+FPN输出P2-P5四个分辨率的特征;
- Query Embedding Init:采用nn.Embedding初始化N个object Proposal 的queries bbox和queries features;
- box head: 更新Query 并 进行 bbox & cls预测。
- mask head:正样本实例mask 预测
- multi-stage:QueryInst采用类似Cascade Mask R-CNN 的 多阶段 box head 和 mask head 的结构,每一阶段更新后的query features和重新预测的box会作为下一个stage的Proposal feature和Proposal box的初始化;
下面具体来讲一下box head和mask head的结构。
(1) Box Head & Mask Head
对于Box Head,在每个stage,给定初始化的Proposal boxes ( B , N , 4 ) (B, N, 4) (B,N,4)和Proposal Features ( B , N , 256 ) (B, N, 256) (B,N,256) 以及 FPN P 2 − P 5 P2-P5 P2−P5的特征图:
- (1)首先通过ROI Align操作从FPN特征图提取bbox feature ( B , N , 256 , 7 , 7 ) (B, N, 256, 7, 7) (B,N,256,7,7),这里与二阶段方法类似,依据box的大小映射到特定特征图进行RoI Croppig和RoI Align;
- (2)随后,利用multi-head self-attention计算transformed object query;
- (3)随后利用transformed object query和bbox feature之间的动态卷积得到更新后的object query;
- (4)紧接着在object query基础上进行bbox预测和cls预测。
对于Mask Head,将batch中每张图片的所有正样本对应的 Proposal boxes 和 Proposal Features 拼接起来,得到 ( P , 4 ) (P, 4) (P,4)和 ( P , 256 ) (P, 256) (P,256) 作为输入:
- (1)首先通过ROI Align操作从FPN特征图提取mask feature ( P , 256 , 14 , 14 ) (P, 256, 14, 14) (P,256,14,14),此处保持与Mask R-CNN尺寸一致;
- (2)随后,transformed object query与Box Head保持共享;
- (3)随后,利用transformed object query和mask feature之间的动态卷积得到更新后的mask feature;
- (4)最后,对mask feature进行上采样并预测实例 mask。
(2) 动态卷积
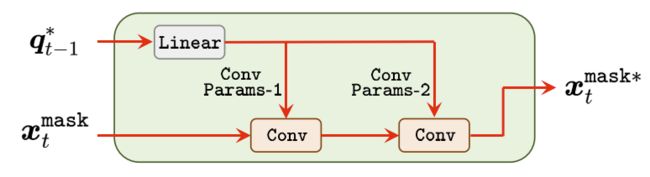
这里是 D y n C o n v m a s k DynConv^{mask} DynConvmask的示意图,对于 D y n C o n v m a s k DynConv^{mask} DynConvmask和 D y n C o n v b o x DynConv^{box} DynConvbox的区别,后者是输入样本量是 ( B , N ) (B, N) (B,N),前者仅包含正样本,样本量为 ( P ) (P) (P),从实现层面,只需要将 ( B , N ) (B, N) (B,N) reshape为 ( B × N ) (B \times N) (B×N),两者的shape便会保持一致了。
具体来讲,给定transformed object query with shape ( B , N , 256 ) (B, N, 256) (B,N,256)和ROI Align得到的bbox feature ( B , N , 256 , 7 , 7 ) (B, N, 256, 7, 7) (B,N,256,7,7),首先利用一个全连接层对 object query 进行映射得到两组1*1卷积参数 ( B , N , 256 ∗ 64 ) (B, N, 256*64) (B,N,256∗64) 和 ( B , N , 64 ∗ 256 ) (B, N, 64*256) (B,N,64∗256) ,进而使用这两组卷积参数对bbox feature进行卷积得到输出 ( B , N , 256 , 7 , 7 ) (B, N, 256, 7, 7) (B,N,256,7,7),如果是 D y n C o n v m a s k DynConv^{mask} DynConvmask,到这里就输出了,但是对于 D y n C o n v b o x DynConv^{box} DynConvbox,还需要将其reshape为 ( B , N , 256 ∗ 7 ∗ 7 ) (B, N, 256*7*7) (B,N,256∗7∗7)再进行通道降维得到输出后的object query ( B , N , 256 ) (B, N, 256) (B,N,256)。
(3) 总结
- 一方面,与Mask R-CNN类似,QueryInst 在目标检测网络Sparse R-CNN的基础上添加了一个局部mask分支;
- 另一方面,局部mask分支的实例mask预测的过程又引入了类似CondInst的动态卷积操作;
- 总的来说,QueryInst依旧没有跳出目前局部mask和全局mask的范畴,主要改进仍然是目标检测网络层面的改变;
6.2 SOLQ * * *
SOLQ 在Deformable DETR基础上提出直接预测实例mask压缩编码来实现端到端的实例分割。
如下图所示,DETR的框架是利用query直接同时预测出 cls 和 box,本文新增了一个并行分支来预测mask的压缩编码。
- 一方面,避免了类似CondInst这类方法中的动态卷积参数预测分支与mask feature的动态卷积操作;
- 另一方面,避免了直接预测flatten后的mask,这会导致预测通道较大,且预测难度较高;
- 在训练阶段,将 mask label 通过可逆压缩编码算法先转化维mask vector label,对mask vector pred进行监督。
- 在推理阶段,将预测的mask vector pred通过解压缩映射回二维的mask。
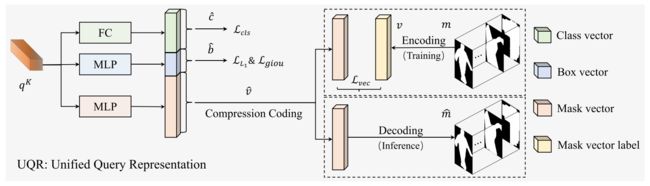
(1) Mask Resolution
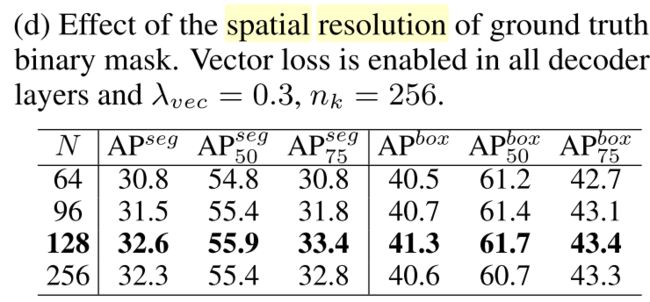
SOLQ采用的是局部mask即输入到可逆压缩编码算法的mask label是经过RoI Cropping和RoI Align的局部mask,不过这里的输出尺寸并不是 28 × 28 28 \times 28 28×28,文中采用的RoI Align输出分辨率是 128 × 128 128 \times 128 128×128,能够一定程度解决Mask R-CNN边缘预测粗糙的问题。
(2) Mask压缩算法
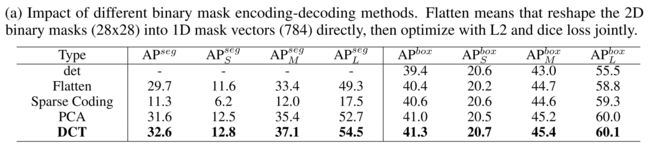
SOLQ探索了Sparse Coding、PCA和DCT三种方式进行压缩编码。文章最终采用DCT进行压缩编码:
- 一方面,DCT的压缩损失最小;
- 另一方面,Sparse Coding 和 PCA需要对整个训练集离线获取“主成分”或“压缩字典”,而DCT可以在线对每张图像进行压缩;
- 从最终实验结果来看,DCT的效果也是最佳的;
DCT压缩的原理参考:http://zhaoxuhui.top/blog/2018/05/26/DCTforImageDenoising.html
(3) 总结
- SOLQ给出了一个非常巧妙的办法,其优雅程度与PolarMask相当,都是将Dense的Mask映射为一组稀疏的表征向量;
- 然而,采用压缩编码一方面会存在压缩和解压缩中的信息损失;
- 另一方面,相比于直接采用动态卷积在特征图上进行mask预测,直接用query feature预测出mask压缩编码的难度也更大;
- 另外,SOLQ虽然采用了更大RoI Align输出尺寸,但是,由于压缩算法的输入和输出的等长限制,依旧无法实现对不同尺寸的目标的mask(不等长输入)的处理;
6.3 Mask2former * * * *
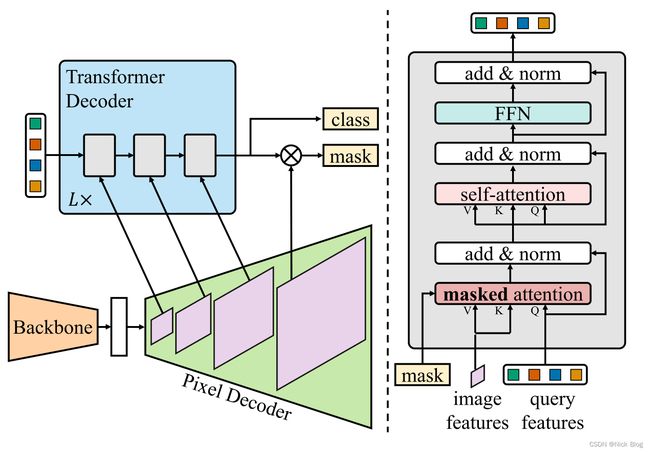
Mask2former的整体结构包含三个部分:
- Backbone:从图像中提取多尺度特征;
- Pixel decoder:类似FPN的功能,进行多尺度特征融合;
- Transformer Decoder:从pixel feature中迭代更新query feature,并利用query feature预测class,利用query feature和1/4高分辨率特征预测mask;
(1) Pixel decoder
- 输入1/32,1/16,1/8,1/4四个分辨率的特征,采用Deformable DETR提出的Deformable Transformer进行多尺度特征交互。
- 具体来讲,对于1/32,1/16,1/8三个特征图上的每一个像素,在三个特征图上各预测K个点,最终使用3K个点的特征加权来更新当前像素点的特征。
- 关于每个分辨率K个点的选取,是通过以当前像素所在的位置为参考点,预测K个(x, y)偏移量得到。
- 这样,有效避免了Transformer采用全局特征来更新单个像素特征导致的极高的计算复杂度,将计算量从 H W × H W HW \times HW HW×HW降低到了 H W × K HW \times K HW×K。
- 除此之外,最终还将1/8分辨率的特征上采样到1/4并与输入1/4特征sum融合用于作为mask预测的高分辨率特征。
(2) Transformer Decoder
Transformer Decoder部分采用与DETR相似的query方式进行目标检测,即首先初始化N*256的query feature,进而采用1/32,1/16,1/8三个分辨率的特征对query feature进行迭代更新并进行最终的class和mask预测。本文的Transformer Decoder与DETR中使用的Decoder有两个区别,分别是(1)masked attention;(2)调换self-attention和cross-attention的顺序。除此之外,与DETR的不同的是,本文采用多尺度特征更新query,避免了DETR仅仅使用1/32特征图造成的小目标的检测效果较差。
<1> masked attention
Masked attention是针对DETR transformer Decoder中的cross-attention部分的改进。有研究表明,DETR类的模型收敛速度慢的部分原因是cross-attention中的全局上下文需要经过较长的训练时间才能使得注意力每次集中在目标附近,即局部上下文。本文考虑到在cross-attention中使用局部上下文能够加速模型的收敛,设计了masked attention模块,即每次仅使用特征图的前景区域的特征更新query。
两者的对比如下:
| Cross attention | 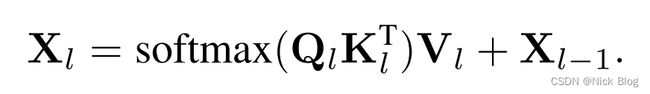 |
|---|---|
| Masked attention | 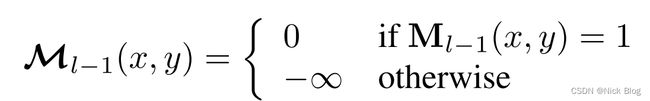  |
M l − 1 M_{l-1} Ml−1采用的是前一个transformer decoder层预测的mask,并使用阈值0.5进行截断得到的二值图。当某个像素的前一层被预测为背景,即 M l − 1 = 0 M_{l-1}=0 Ml−1=0,映射后的 M l − 1 = − ∞ \mathcal{M}_{l-1}=-\infty Ml−1=−∞,则经过softmax映射后,其该像素点的注意力便会下降为0。最终,便只有前景区域的像素点特征会影响query X l X_{l} Xl的更新。
<2> 调换self-attention和cross-attention的顺序
作者文中描述:由于query feature是zero初始化的,第一层transformer Decoder直接上来就进行self-attention不会产生任何有意义的特征,因此先使用cross attention对query feature进行更新后再执行query feature内部的self-attention反而是一种更佳的做法。
但是实际上这个是有争议的,无论是DETR还是本文的query都是随机初始化的,并没有zero初始化的情况。
(3) 采样点损失函数
不同于语义分割,其最终是预测 C l a s s ∗ H ∗ W Class*H*W Class∗H∗W的特征图,并对其进行监督。然而,maskformer则需要预测 N u m _ q u e r i e s ∗ H ∗ W Num\_queries*H*W Num_queries∗H∗W的特征图。由于query数目通常远大于类别数目,因此,这一类方法会导致巨大的训练内存占用。本文参考PointRend,在每个 H ∗ W H*W H∗W的特征图依据当前像素的不确定度选取K个采样点而不是整个特征图来计算损失函数。其中,不确定度的衡量是依据像素预测置信度得到的。
u n c e r t a i n t y = − ( t o r c h . a b s ( g t _ c l a s s _ l o g i t s ) ) uncertainty=-(torch.abs(gt\_class\_logits)) uncertainty=−(torch.abs(gt_class_logits))
除了在计算损失函数的过程中运用了采样点,本文还在matcher匈牙利匹配时才用了采样点的策略。不同之处在于,在matcher过程中,还不清楚每个query和哪个gt匹配,因此无法同样采用不确定度进行选点无法保证能够选取到gt的前景区域,因此,在matcher过程是采用随机均匀分布采样了K个点,同一个batch所有的query和gt均是采样这K个点。
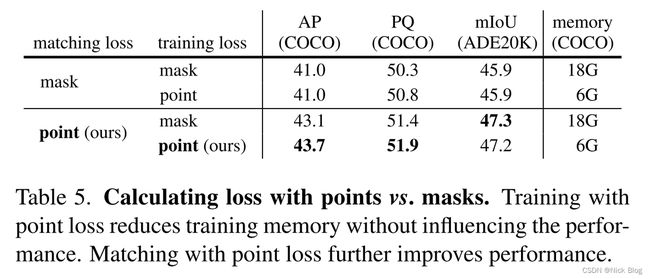
- 对于使用不确定度的采样点损失函数,其相比于mask损失函数能够将显存占用从18G降低为6G,精度还有小幅提升。
- 对于使用均匀分布随机点采样匈牙利匹配,其竟能够产生2.7个点的AP收益,文中没有对此进行详细解释。因此我进行了一下复现,与文中的数据是一致的。详细一点来讲,使用mask匹配是在1/4分辨率进行的,将gt mask采用最近邻插值进行下采样。point匹配会随机K个点(非整数位置),然后从1/4的预测mask和1/1的gt mask均采用双线性插值取值,目前暂不清楚为什么会产生如此大的差异。
(4) 总结
- 从消融实验结果来看,Mask2former的大幅提升点有:deformableAttention,mask attention,LSJ(large scale jitting);
- Benchmark对比来看,mask2former在 A P l AP_l APl 上完胜先前的实例分割网络,唯独 A P s AP_s APs 效果比QueryInst和HTC++差一点。这也是接下来的文章改进的主要方向。
5. 这一载半
本来想在结尾处介绍一下自己进半年多的探索过方向和一些结果,后来想想,都是半成品,似乎没有拿出来的必要,都是过眼云烟,idea刚探索出来时觉得无比惊艳,越做越觉得平庸随大流,然后烂尾放弃,而后换个地方填坑。
这一载半,寻寻觅觅,终止于此。
6. 参考
- Mask-RCNN
- Cascade Mask R-CNN
- HTC
- YOLACT
- YOLACT++
- TensorMask
- BlendMask
- EmbedMask
- CondInst
- SOLO
- SOLOv2
- PointRend
- RefineMask
- PolarMask
- Deep Snake
- QueryInst
- SOLQ
- MEInst
- Mask2former
- Instance Segmentation by Jointly Optimizing Spatial Embeddings and Clustering Bandwidth
- AdaptIS
- Deep Watershed Transform for Instance Segmentation
- Semantic Instance Segmentation with a Discriminative Loss Function
- 目标检测与分割之MaskRCNN代码结构流程全面梳理+总结
- MaskRCNN-ICCV2017 论文解读
- 轻松掌握 MMDetection 中常用算法(五):Cascade R-CNN
- Cascade R-CNN 详细解读
- 实例分割新思路之SOLO v1&v2深度解析
- PolarMask: 用极线表示的单阶段物体示例分割-论文解读与思考