python - 啃书 第七章 模块、包和库 (一)
概述
在Python中,一个模块(Module)是一个以.py结尾的Python文件,包含了Python对象和语句。
在python中,一切皆对象。数字、字符串、元组、列表、字典、函数、方法、类、模块等等都是对象,包括你的代码。
使用模块有很多好处:
(1)方便组织代码
(2)提高代码的可维护性
(3)增加代码的重用性
(4)避免函数名和变量名冲突
为了对同一类型的模块进行有效的管理,Python引入了包(Package)来组织模块,包是Python模块文件所在的目录,并且在该目录下必须有一个名为__init__.py的文件;否则,Python就将该目录作为普通目录,而不是一个包。__init__.py可以是空文件,也可以包含Python代码。
包里面既可以有包,也可以有模块,组成多级层次的包-模块结构
具有相关功能的包和模块集合则形成了库,如Python标准库、NumPy库等。按照库的来源,Python中的库可分为三类:标准库(Python自带)、第三方库(由第三方机构发布、具有特定功能)和自定义库(用户创建)
常用标准库模块
标准库是Python自带的,不需要另外安装,在程序中调用其中的模块时使用关键字import导入
Python标准库包含200个以上各种功能的模块:
Turtle:绘制线、圆及其他形状(包括文本)图形的模块
Random:生成随机数
Time:格式化日期和时间
Datetime:日期和时间处理
Os:提供使用操作系统功能和访问文件系统简便方法
Sys:提供对Python解释器相关操作
Timeit:性能度量
Zlib:数据打包和压缩
Math:数学函数
Re:正则表达式
Urllib.request:处理从urls接受数据
Unittest:代码测试
Turtle模块(海龟)(线条)(绘图)
Turtle是Python内钱的绘制线、圆及其他形状(包括文本)的图形模块
Turtle模块可以创建一个画笔,在一个横轴为x、纵轴为y的坐标系原点位置开始,根据一组函数指令的控制,在这个平面坐标系中移动绘制图形
1、画布(Canvas)
画布是Turtle模块展开用于绘图的区域,默认有一个坐标原点为画布中心的坐标轴,可以使用函数turtle.screensize()和turtle.setup设置他的大小和初始位置
(1)turtle.screensize()设置画布
turtle.screensize(width,height,bg)
宽、高、背景颜色
(2)turtle.setup(width,height,startx,starty)
宽、高、画布左上角顶点在窗口的位置坐标
2、画笔
(1)画笔状态。
Turtle模块绘图使用位置方向描述画笔的状态
(2)画笔属性
颜色、宽度、移动速度等
turtle.pensize(width):宽度
turtle.pencolor(color):"red"或RGB格式
turtle.speed(speed):范围为[0,10]的整数
(3)绘图命令:操纵Turtle模块绘图有许多命令,通过相应函数完成。
通常分为三类:画笔运动命令、画笔控制命令、全局控制命令
①画笔运动命令
turtle.penup():提起画笔,在另一个地方绘制时使用,移动时不会绘制图形
turtle.pendown():放下画笔,移动时绘制图形,默认为绘制模式
turtle.forward(dis):向当前画笔方向移动制定长度dis(display?)ward(区域)
turtle.backward(dis):向与当前画笔相反的方向移动制定长度dis
turtle.right(degree):顺时针旋转制定角度degree(度)
turtle.left(degree):逆时针旋转制定角度degree
turtle.home():回到原点,并朝向默认初始位置
turtle.goto(x,y):将画笔移动到指定的绝对坐标位置(x,y)
setx(x):将当前x轴移动到指定位置x(将坐标原点x=0变为x=x)
sety(y):将当前y轴移动到指定位置y
turtle.circle®:半径r为正/负,表示圆心在画笔的左边/右边画圆
②画笔控制命令
turtle.color(color1,color2):设置画笔颜色为(color1),填充颜色为(color2)
turtle.fillcolor(color):设置填充颜色color
turtle.begin_fill():开始填充
turtle.end_fill():结束填充
turtle.hideturtle():隐藏turtle箭头
turtle.showturtle():现实turtle箭头
③全局控制命令
turtle.clear():清楚窗口中的所有内容
turtle.reset():将状态和位置复位为初始值
turtle.done():使turtle窗口不会自动消失
turtle.undo():取消最后一个图形操作
turtle.write(s[,font=(“font-name”,font_size,“font_type”)]):在画布上写文本,s为文本内容,font为字体参数(字体名称、大小、类型)可选
例·绘图
import turtle
for i in range(4):
turtle.forward(100)
turtle.left(90)
turtle.done()
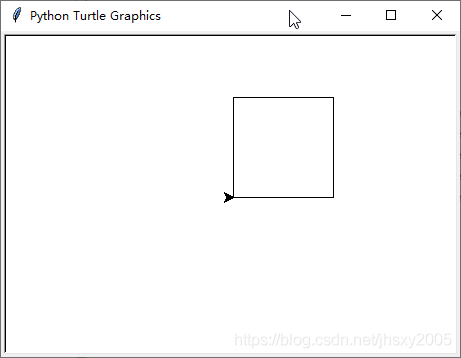
生成一个专门的绘图窗口,在其上绘图!而具体用途,暂且未知,可以复制图形到临时文件吗?
import turtle
turtle.penup()
turtle.goto(-150,0)
turtle.pendown()
turtle.pencolor('blue')
turtle.begin_fill()
turtle.fillcolor('yellow')
for i in range(4):
turtle.forward(100)
turtle.left(90)
turtle.end_fill()
#画圆
turtle.penup()
turtle.goto(100,0)
turtle.pendown()
turtle.color('red')
turtle.pensize(3)
turtle.circle(50)
turtle.done()
例·写字
import turtle
t=turtle.Turtle() # 创建turtle对象
t.hideturtle()
t.penup()
t.goto(-80,20)
t.write("望庐山瀑布",align='center',font=("微软雅黑",14,"normal")) # 设置字体、大小、加粗
t.sety(-10) # 画笔向下移动到-10
t.write("日照香炉生紫烟",align='center',font=("微软雅黑",14,"normal")) # 设置字体、大小、加粗
t.sety(-40)
t.write("遥看瀑布挂前川",align='center',font=("微软雅黑",14,"normal")) # 设置字体、大小、加粗
t.sety(-70)
t.write("飞流直下三千尺",align='center',font=("微软雅黑",14,"normal")) # 设置字体、大小、加粗
t.sety(-100)
t.write("疑似银河落九天",align='center',font=("微软雅黑",14,"normal")) # 设置字体、大小、加粗
turtle.done()

就这些!?但是我用这个在ipython和jupyter,大几率卡住,这样的话,整个进程都废了,在.py中几次倒是没卡过
Random模块
Random模块用于生成随机数
1、random.random():生成[0,1)之间的随机浮点数
import random
for i in range(5):
print(random.random())
#
0.04352014105020674
0.9951365024350252
0.6443871643005861
0.491210384384823
0.23034170867116366
2、random.uniform(a,b):生成[a,b]之间的随机浮点数 if a>b else a,b=b,a
uniform:制服、统一
import random
print(random.uniform(3,6))
print(random.uniform(6,8))
print(random.uniform(1,-1))
#
3.106841298507868
7.777306754163939
0.22118302858268857
3、random.randint(a,b):生成[a,b]间的整数,if a
rand:产生随机数
import random
list1=[]
for i in range(5):
list1.append(random.randint(1,100))
print(list1)
#
[33, 15, 17, 81, 38]
4、random.randrange([start],stop[,step]):在指定区域产生指定步进的随机整数,抑或解释为在start<=n<=stop,n-start%step==0的数字范围中产生随机中数
import random
l=[]
for i in range(10):
l.append(random.randrange(0,100,3))
print(l)
#
[60, 69, 87, 87, 0, 72, 96, 18, 90, 60]
5、random.choice(sequence):从序列对象中获取一个随即元素
choice:选择
random.choice("jsakdojklas")
#
's'
6、random.shuffle(sequence[,random]):将一个序列对象中的元素打乱
shuffle:洗牌
其中可选项仍未可知,默认是random.random(),文档中的解释是:
可选参数 random 是一个 0 参数函数,在 [0.0, 1.0) 中返回随机浮点数;默认情况下,这是函数random() 。
这个方法是原地返回的,所以操作对象必须支持可修改,元组和字符串就无法操作!
import random
b=[87, 0, 72, 96, 18, 90, 60]
random.shuffle(b)
print(b)
#
[87, 60, 96, 90, 18, 0, 72]
7、random.sample(sequence,k):从指定序列对象中随机获取指定长度的片段
sample:样本
这个接上文shuffle,shuffle是无法操作不可写对象的,所以就可以利用文档中提到的sample(x,len(x))的方法获取不可些对象的随机序列
import random
s="asjdkasjkld"
r=random.sample("asjdkasjkld",len(s))
print(r)
#
['k', 'd', 'k', 'd', 's', 'j', 's', 'a', 'l', 'a', 'j']
补充
以上是书中介绍的7中random方法。从文档中补充些!
伪随机数
虽然看似随机,但是其方法和结果是可确定、可再现的,所以不建议用于安全和加密
2、他的方法有很多,于是有很多玩法,详见文档和help
薄记功能
random(), seed(), getstate(), setstate(), getrandbits(k)
整数
randrange(stop):[0,stop)之间的整数
randrange(start,stop[,step]):[start,stop)之间的整数,可选步进从start+x*step的序列间随机选择整数
randint(a,b):[a,b],等同于randrange(a,b+1)
序列
choice(seq):从非空序列seq返回一个随机元素
choices(population,weights=None,*,cum_weights=None,k=1)
Python choices()函数详解、random模块下的常用函数
import random
a = [1,2,3,4,5]
print(random.choices(a,k=5)) #从a中随机一个元素,执行五次
print(random.choices(a,weights=[0,0,1,0,0],k=5)) #设置相对权重,这里元素3是唯一数
print(random.choices(a,weights=[1,1,1,1,1],k=5)) #这里五个元素的权重是一样的
print(random.choices(a,cum_weights=[1,2,3,4,5],k=5)) #这个是累加权重,不是很好理解
choice vs choices:3.14 µs vs 1.96 µs
累加权重猜想
weights=[1,2,3,4,5]:cum_weights=[1,3,6,10,15]
weights=[1,0,0,0,0]:cum_weights=[1,1,1,1,1]
weights=[1,1,1,1,1]:cum_weights=[1,2,3,4,5]
那问题来了,如果cum_weights中,后面的元素小于前面的元素会怎样
cum_weights=[1,2,3,4,3]:weight=[1,1,1,1,-1]?:实际效果:weight=[1,1,1,0,0]
cum_weights=[1,2,3,4,2]:实际效果:weight=[1,1,0,0,0]
cum_weights=[1,2,3,1,5]:实际效果:weight=[1,1,1,0,2]?
于是,设i为c:=cum_weights的索引值,当c[i]
cum_weights=[1,1,2,1,1,3]:实际效果:weight=[1,0,1,0,0,1]
无论是五个元素还是六个元素,累加权重第三个位置,它的数值会影响前面的显示
1,2,3,…,x : 1,1,1,…,x-3
1,2,2,… : 1,1,0,…
1,2,1,… : 1,0,0,…
1,2,0,… : 0,0,0,…
扩展到9个元素,貌似更加明了
[1,2,3,4,0,1,2,1,3] : [0,0,0,0,0,1,1,0,1]
[1,2,3,4,1,2,2,1,3] : [1,0,0,0,0,1,0,0,1]
[1,9,0,3,1,2,0,0,3] : [0,0,0,1,0,0,0,0,2]
[1,9,0,3,1,2,2,0,3] : [0,0,0,1,0,1,0,0,1]
[1,3,5,0,1,2,2,0,3] : [1,0,0,0,0,1,0,0,1]
大概看明白了,忽略数字0,倒着看就以最后一行分析,
c[-1]=3 : 累加权重总数是3 c[-1]向前边喊大喊,我给你们3个名额
c[-3]=2 : c[-3]向前边喊,我给你们2个名额,但是c[-3]并没有资格那名额,所以名额就留给c[-1]既w[-1]=1
于是轮到前边的c[-4],留住一个名额
发现这里是.。。。。。。。。。。。。。。。我放弃了,于是翻代码吧!
cum_weights = list(_accumulate(weights))
accumulate:累加
我觉得我又行了!
貌似成了!仍然是倒着看,但是这里过滤掉无效的,例如上例
[1,2,3,4,0,1,2,1,3] : [1,2,3,4,-,1,2,-,3] : [0,0,0,0,0,1,1,0,1]
[1,2,3,4,1,2,2,1,3] : [1,2,3,4,-,2,-,-,3] : [1,0,0,0,0,1,0,0,1]
但[1,0,1,0,1,0,1,0,3]如何去解释结果是[0,0,1,0,0,0,0,0,2]
莫非第一个0是有效的,看不到代码就是瞎猜
从后接桥看首位,0的个数足够的话,可以停止对前面的探究!但一般很少会用这么特殊的写法的吧!
random.shuffle(x[, random]):random的用法仍未可知
random.sample(population, k):0<=k<=len(pop),isinstance(k,int):True
choice结果的元素是可重复出现的,但sample的结果最多出现一次
实值分布
random() : 0<=r<1,r:float
uniform(a,b) : r:float a<=r<=b [a,b] or b<=r<=a [b,a]
triangular(low,high,mode) : triangular 三者之间的
r:float low<=r<=high 依据mode对照分布
import random
z=[]
for i in range(20):
z.append(random.triangular(-1,1,0.5))
z.sort()
#
[-0.92150025261175,
-0.44302306743731723,
-0.24827191900800383,
-0.17728557766577757,
-0.1456508343793148,
-0.06908688986403366,
0.03848134244307788,
0.06426182211976084,
0.06699038359957621,
0.08737113087100035,
0.10891675548327129,
0.26853665812127914,
0.31729592948600227,
0.3892217278760537,
0.40431765715601786,
0.4393880063215492,
0.5224489312344693,
0.5383455679419284,
0.7305717016455016,
0.762723384027757]
从现在开始的random方法都涉及了分布,这个以后学完整绘图,回头画画!
betavariate(alpha,beta):Beta分布 alpha>0,beta>0,r介于0和1之间
variate:随机变量
random.betavariate(10,9)
#
0.559110825336943
expovariate(lambd):指数分布 lambd是1.0除以所需的平均值,他应该是非零的,该参数本应命名为lambda,但这是保留字,如果lambda为正,r的范围为0到正无穷大;如果lambd为负,则r从负无穷大到0。
expo:博览
random.expovariate(0.01)
#
350.19194200231084
# 0.1
36.190495588849316
j=0
for i in range(10000):
jj=random.expovariate(-0.1)
if jj<j:
j=jj
print(i,j)
#
0 -6.1328265519350005
2 -18.737487172843494
5 -34.10632715057859
32 -36.047288665223206
61 -36.31141714764642
127 -36.93102927852477
138 -38.1157488978079
174 -43.331913822209316
214 -46.29847248458721
264 -48.6480845545143
326 -51.14194629497917
405 -52.371343863610434
842 -58.5213576242122
1037 -60.89071817252162
2113 -85.74399520875836
3274 -97.16115602273655
# -0.5
0 -1.7824925453576488
1 -3.457178415406453
2 -5.921818124617473
3 -7.372790971697268
41 -11.322757184998379
532 -13.17741978892413
904 -14.852618036203788
3182 -15.289189614396713
6389 -16.195497772379266
6609 -16.207032500083987
8523 -16.682632796215348
r的范围=±|10/lambda|
和uniform(a,b)像,但是取值范围属于(0,10/lambda)或(10/lambda,0),是开方区间
gammavariate(alpha,bate):Gamma分布,不是gamma函数,alpha>0,bate>0
x ** (alpha - 1) * math.exp(-x / beta) / (math.gamma(alpha) * beta ** alpha)
gauss(mu, sigma):高斯分布
lognormvariate(mu, sigma):对数正态分布
normalvariate(mu, sigma):正态分布
vonmisesvariate(mu, kappa):冯·米塞斯(von Mises)分布
paretovariate(alpha):帕累托分布
weibullvariate(alpha, beta):威布尔分布
这么多懒得式了,总之知道有这些功能就行,用的时候在学这些是什么东西
class random.Random([seed ])
。该类实现了random 模块所用的默认伪随机数生成器。
class random.SystemRandom([seed ])
使用os.urandom() 函数的类,用从操作系统提供的源生成随机数。这并非适用于所有系统。也不依赖于软件状态,序列不可重现。因此,seed() 方法没有效果而被忽略。getstate()和setstate() 方法如果被调用则引发NotImplementedError。
Time模块和Datetime模块
1、Time模块用于时间访问和转换
time():返回时间戳(字1970-1-1 0:00:00 至今所经历的浮点秒数)
1970年1月1日那天,发生了什么?
unix元年、千年虫、2023虫
import time
print(time.time())
1602053894.0794766
小数点前面是秒,后面是0.0000001秒(100ns),有时6位,有时7位啊。
假设将其换算成天,每天246060=86400,这是第18543天,1970年,闰年,若仅当做365天算,为50年293天,若将闰年穿插进去,1972年为闰年,今年也是闰年而且过去了,那么去除7天,286天,闰年的第286天,10月11日?可分明是10月7日。哪里算错了!写一下算法了!脑子不够使的!
import time
t=time.time()
d=t//(24*60*60)+1
ds=t%(24*60*60)
hs=ds//(60*60)
ms=ds%(60*60)//60
ss=ds%60
y=(d-(d//365+1)//4)//365+1970
yd=(d-(d//365+1)//4)%365
if y/4%1==0:
m=[31,29,31,30,31,30,31,31,30,31,30,31]
else:m=[31,28,31,30,31,30,31,31,30,31,30,31]
for i in range(12):
if yd<m[i]:break
else:yd=yd-m[i]
print("%d-%2d-%02d %02d:%02d:%02d"%(int(y),i+1,int(yd),hs,ms,ss))
#
2020-10-07 07:52:30
4.15 µs
又出现一个问题,现在时间分明是15:52,为何是7?东八区?
如果是因为东八区的话,为什么他是7?
然后在时间设置里面,发现一个叫做协调世界时的东西
国际日期变更线:从东向西越过这条界线时,日期要加一天,从西向东越过这条界线时,日期要减去一天。
也就是说,东八区比东零区更早迎来日出,同一时间,比东零区时钟上大了8个小时,而东零区或者说是零区时间就是世界时!
世界时UT即格林尼治平太阳时间,是指格林尼治所在地的标准时间(伦敦御园)
asctime([t]):将一个tuple或struct_time形式的时间转换为一个表示当前本地时间的字符串
struct:结构
ctime([secs]):将一个秒数时间戳表示的时间转换为一个表示当前本地时间的字符串
就是上面码的功能
import time
time.ctime(time.time())
#
'Wed Oct 7 16:11:46 2020' # 2020-10-07 星期三 16:11:46
1.59 µs
去除第一句,就1.46 µs
localtime([secs]):返回以指定时间戳对应的本地时间struct_time对象
time.struct_time(tm_year=2020, tm_mon=10, tm_mday=7, tm_hour=16, tm_min=17, tm_sec=5, tm_wday=2, tm_yday=281, tm_isdst=0)
2020-10-07 16:17:05 一周的第2天(0~6)一年的第281天 冬令时
tuple(localtime([secs])):(2020, 10, 7, 16, 29, 11, 2, 281, 0)
tm_isdst 只是传入的时间是否是 DST(夏令时),我当初查字典,以为是不是休息日呢,啊嘞,试不出来,来个365的循环,还都是0,于是bing了一下!
strftime(s,t):strftime(format[, tuple])
strftime("%a, %d %b %Y %H:%M:%S +0000", gmtime())
这个类似于字符串的格式化
time.altzone:返回与utc时间的时间差,以秒为单位(西区该值为正,东区该值为负)
alt:最高,参照
-32400
以上是时间模块中有关时间戳的相关方法,但只是模块中的一小部分,另外还有很多线程功能、sleep、ns等
但文档和实际效果又不一样,实际说没有某某某模块,这么说上面占了不少比例了,于是这次参照help抄文档吧!
time文档别有天地
Python中time模块使用手册
time有两种时间模式
1、时间戳
以UTC为基准时间,在unix上以1970-1-1 0:0:0为起始的秒数,可以是浮点数
2、以9个元素组成的元组的局部时间
元组元素:
year : 2020
month : 1-12
hours : 0-23
minutes : 0~59
seconds : 0-59
weekday : 0-6 星期一是0
Julian day : 一年的第几天 1-366
DST (Daylight Savings Time) : 夏令时 (-1,0,1) (mktime()给出依据,冬令时,夏令时)
struct_time(iterable=(),/)
tm_gmtoff : 时间戳
tm_hour : [0,23]
tm_isdst : 1夏令时 0 冬令时 -1 未知
tm_mday : 一个月中的第几天 [1,31]
tm_min : [0,59]
tm_mon : [1,12]
tm_sec : [0,61])? 这个应该是[0,60)因为他是浮点数,所以理论上说可以是无理数的,但实际精度应该有极限
tm_wday : [0,6] 星期一是0
tm_year : [1,366]
tm_zone : 时区缩写
支持四则运算、比较运算、包含、索引
[0,2**63 - 1]
asctime(...)
asctime([tuple]) -> string
转换元组时间至字符串模式,默认当前时间
ctime(...)
ctime(seconds) -> string
转换时间戳至字符串模式,默认当前时间
get_clock_info(...)
get_clock_info(name: str) -> dict
???
gmtime(...)
gmtime([seconds]) -> (tm_year, tm_mon, tm_mday, tm_hour, tm_min,
tm_sec, tm_wday, tm_yday, tm_isdst)
转换时间戳至结构模式(UTC),默认当前时间
localtime(...)
localtime([seconds]) -> (tm_year,tm_mon,tm_mday,tm_hour,tm_min,
tm_sec,tm_wday,tm_yday,tm_isdst)
转换时间至结构模式(本地时区),默认当前时间
mktime(...)
mktime(tuple) -> floating point number
转换元组模式至时间戳模式
tuple(struct_time)就是元组模式
(2020, 10, 7, 20, 47, 48, 2, 281, 0)
monotonic(...)
monotonic() -> float
貌似是当前小时内的第几秒
返回性能计数器的值(以小数秒为单位)
monotonic_ns(...)
monotonic_ns() -> int
同上,单位ns
perf_counter(…)
perf_counter() -> float
Performance counter for benchmarking.
perf_counter_ns(...)
perf_counter_ns() -> int
???这个起始时间不懂
process_time(...)
process_time() -> float
返回当前进程的系统和用户 CPU 时间总和的值
process_time_ns(...)
process_time() -> int
同上
sleep(...)
sleep(seconds)
暂停进程几秒
strftime(...)
strftime(format[, tuple]) -> string
Commonly used format codes:
%Y Year with century as a decimal number.
%m Month as a decimal number [01,12].
%d Day of the month as a decimal number [01,31].
%H Hour (24-hour clock) as a decimal number [00,23].
%M Minute as a decimal number [00,59].
%S Second as a decimal number [00,61].
%z Time zone offset from UTC.
%a Locale's abbreviated weekday name.
%A Locale's full weekday name.
%b Locale's abbreviated month name.
%B Locale's full month name.
%c Locale's appropriate date and time representation.
%I Hour (12-hour clock) as a decimal number [01,12].
%p Locale's equivalent of either AM or PM.
将时间格式化输出成字符串格式
strftime("%a, %d %b %Y %H:%M:%S +0000", gmtime())
time.strftime("%Y %m %d %H %M %S %z %a %A %b %B %c %I %p",time.localtime())
‘2020 10 09 11 17 14 +0800 Fri Friday Oct October Fri Oct 9 11:17:14 2020 11 AM’
strptime(...)
strptime(string, format) -> struct_time
Parse a string to a time tuple according to a format specification.
See the library reference manual for formatting codes (same as
strftime()).
Commonly used format codes:
%Y Year with century as a decimal number.
%m Month as a decimal number [01,12].
%d Day of the month as a decimal number [01,31].
%H Hour (24-hour clock) as a decimal number [00,23].
%M Minute as a decimal number [00,59].
%S Second as a decimal number [00,61].
%z Time zone offset from UTC. 时区
%a Locale's abbreviated weekday name. 简写星期
%A Locale's full weekday name. 完整星期
%b Locale's abbreviated month name.
%B Locale's full month name.
%c Locale's appropriate date and time representation. 合适的显示
%I Hour (12-hour clock) as a decimal number [01,12]. 12小时显示
%p Locale's equivalent of either AM or PM. 上午下午
Other codes may be available on your platform. See documentation for
the C library strftime function.
将时间格式化输出成结构模式
time.strptime(“30 Nov 00”, “%d %b %y”)
thread_time(...)
thread_time() -> float
进程时间
thread_time_ns(...)
thread_time() -> int
同上
time(...)
time() -> floating point number
时间戳
time_ns(...)
time_ns() -> int
同上
DATA
altzone = -32400
daylight = 0
timezone = -28800
tzname = (‘中国标准时间’, ‘中国夏令时’)

Datetime模块
Datetime模块为日期和时间处理同时提供简单、复杂的方法
Datetime模块中的常用类:日期类(date类)、时间类(time类)、日期时间类(datetime类)、时间差类(timedelta类)
delta:希腊字母第四个字 Δ,因为是三角形,通常自己用的时候也有相关意思,这里应该指第三方
(1)date类
date类
创建一个date对象的一般格式:d=datetime.date(year,month,day)
若创建一个临时名来代替datetime.date,a=datetime.date
a就是date类,type:type
d是date类带默认值ymd的一个对象,type:datetime.date
a=datetime.date.today() , type:datetime.date
b=a.ctime() , type(b):str
以上是因为,today()或者(year.month.day)是类创建对象的方法,而ctime是处理问题的方法
支持的方法:
'__add__','__class__','__delattr__','__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__ne__', '__new__', '__radd__', '__reduce__', '__reduce_ex__', '__repr__', '__rsub__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__'
定义的方法:
'ctime', 'isocalendar', 'isoformat', 'isoweekday', 'replace', 'strftime', 'timetuple', 'toordinal', 'weekday', ]
类方法(创建对象的方法):
'fromisocalendar', 'fromisoformat', 'fromordinal', 'fromtimestamp', 'today'
数据描述:
'day', 'month', 'year'
属性:
'max', 'min', 'resolution'
| max = datetime.date(9999, 12, 31) 限定结果最大值
|
| min = datetime.date(1, 1, 1) 限定结果最小值
|
| resolution = datetime.timedelta(days=1) 限定时间单位
from datetime import date
d=date.today()
print("当前本地日期:",d)
print("日期:%d年%d月%d日"%(d.year,d.month,d.day))
print("今天是周%d"%d.isoweekday())
当前本地日期: 2020-10-09
日期:2020年10月9日
今天是周5
a=datetime.date.today()
a:datetime.date(2020, 10, 9)
b=datetime.date(2011, 1, 1)
# 这里很像是l=[1,2,3]与l=list((1,2,3)),但前提是他能够接受手动赋值的数据
a.ctime():'Fri Oct 9 00:00:00 2020'
# 因为date并没有时分秒的显示,于是ctime的时分秒都是0
a.isocalendar():(2020, 41, 5) #国际历法周 year[1,9999] week number[1,52] weekday[1,7]
a.isoformat(): '2020-10-09'
a.isoweekday(): 5 #星期五 [1,7]
a.replace([year=%d][day=%d][month=%d]): 返回一个值,如果未设定新的值,返回原值,若设定,返回对应的值
b=a.replace(year=1999): b: datetime.date(1999, 10, 9) a:不会变的
a.strftime("%y %m %d"): '20 10 09'
a.timetuple(): time.struct_time(tm_year=2020, tm_mon=10, tm_mday=9, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=4, tm_yday=283, tm_isdst=-1)
a.toordinal(): 737707 #从国际历法0001.01.01开始的第几天
a.weekday(): 4 #从星期一到星期日,[0,6]
a.fromisocalendar(2011,52,7): datetime.date(2012, 1, 1) #这里只是检查数字是否合法,而不会否定结果是否是下一年,但是结果不能越界过9999, 12, 31
a.fromisocalendar(9999,52,5): datetime.date(9999, 12, 31)
a.fromordinal(737707): datetime.date(2020, 10, 9) # ordinal 顺序的
a.fromtimestamp(1212312213): datetime.date(2008, 6, 1) # timestamp 时间戳
a.max: datetime.date(9999, 12, 31)
a.min: datetime.date(1, 1, 1)
a.resolution: datetime.timedelta(days=1) #resolu 分辨率 solu 解析
time类
Time类为时间类,创建一个time对象的格式
t=time([hour[, minute[, second[, microsecond[, tzinfo]]]]])
from datetime import time
print("时间最大值",time.max)
print("时间最小值",time.min)
t=time(20,30,50,8888)
print("时间:%d时%d分%d秒%d微秒"%(t.hour,t.minute,t.second,t.microsecond))
'isoformat'
datetime.time.isoformat(datetime.time((t1:=[int(i) for i in (time.strftime("%H,%M,%S",time.localtime())).split(",")])[0],t1[1],t1[2]))
# '11:35:09' # 让datetime.time对象以国际格式显示 目前并没有读取现在时间的方法,这个类中貌似只能手动赋值
'replace': 返回新值,可修改数据
'strftime': 自定义字符串显示
datetime.time(1,1,1).strftime("%H:%M:%S"): '01:01:01'
'fromisoformat': t.fromisoformat("11:11:11") : datetime.time(11, 11, 11)
数据:
'fold':[0,1] 与夏令时有关,解释复杂
'hour'
'minute'
'second'
'microsecond'
'max': datetime.time(23, 59, 59, 999999)
'min': datetime.time(0, 0)
'resolution': datetime.timedelta(microseconds=1)
以下四个是关于时区的参数 timezone
‘dst’
‘tzname’
‘utcoffset’
‘tzinfo’
作为 tzinfo 参数被传给time 构造器的对象,如果没有传入值则为 None。
Python中时间的处理之——tzinfo篇
from datetime import datetime, tzinfo,timedelta
"""
tzinfo是关于时区信息的类
tzinfo是一个抽象类,所以不能直接被实例化
"""
class UTC(tzinfo):
"""UTC"""
def __init__(self,offset = 0):
self._offset = offset
def utcoffset(self, dt):
return timedelta(hours=self._offset)
def tzname(self, dt):
return "UTC +%s" % self._offset
def dst(self, dt):
return timedelta(hours=self._offset)
#北京时间
beijing = datetime(2011,11,11,0,0,0,tzinfo = UTC(8))
#曼谷时间
bangkok = datetime(2011,11,11,0,0,0,tzinfo = UTC(7))
#北京时间转成曼谷时间
beijing.astimezone(UTC(7))
#计算时间差时也会考虑时区的问题
timespan = beijing - bangkok
datetime类
Datetime类为日期时间类
dt=datetime(year,month,day[,hour[,minute[,second[,microsecond[,tzinfo]]]]])
from datetime import datetime
dt=datetime.now() #datetime.datetime(2020, 10, 9, 14, 37, 43, 898172)
print("当前日期:",dt.date())
print("当前时间:",dt.time())
print("当前年份:%d,当前月份:%d,当前日期:%d"%(dt.year,dt.month,dt.day))
print("时间:",datetime(2018,9,16,12,20,36))
#
当前日期: 2020-10-09
当前时间: 14:37:25.052528
当前年份:2020,当前月份:10,当前日期:9
时间: 2018-09-16 12:20:36
import datetime
dt=datetime.datetime(2020, 10, 9, 14, 55, 46, 669989)
dt.astimezone(): datetime.datetime(2020, 10, 9, 14, 55, 46, 669989, tzinfo=datetime.timezone(datetime.timedelta(seconds=28800), '中国标准时间'))
# 增加时区信息
dt.ctime(): 'Fri Oct 9 14:55:46 2020'
dt.date(): datetime.date(2020, 1, 1)
dt.dst()
dt.isoformat(): '2020-10-09T14:55:46.669989+08:00'
dt.replace(year=1999): datetime.datetime(1999, 10, 9, 14, 55, 46, 669989)
dt.time(): datetime.time(14, 55, 46, 669989)
dt.timestamp(): 1602226546.669989
dt.timetuple(): time.struct_time(tm_year=2020, tm_mon=10, tm_mday=9, tm_hour=14, tm_min=55, tm_sec=46, tm_wday=4, tm_yday=283, tm_isdst=-1) 返回本地时间结构
dt.timetz(): datetime.time(14, 55, 46, 669989) 返回时间部分
dt.tzname(): '中国标准时间' 返回时区名称,如果有的话
dt.utcoffset: datetime.timedelta(seconds=28800) or None
dt.utctimetuple(): time.struct_time(tm_year=2020, tm_mon=10, tm_mday=9, tm_hour=6, tm_min=55, tm_sec=46, tm_wday=4, tm_yday=283, tm_isdst=0) 返回utc的时间结构
创建方法:
dt.combine(datetime.date(2020,10,9),datetime.time(14, 55, 46, 669989))
dt.fromisoformat('2020-10-09T14:55:46.669989+08:00')
dt.fromtimestamp(1602226546.669989)
dt.now(tz=None): 生成当前时间,若没有指定时区,就用本地时区
dt.now(tz=datetime.timezone(datetime.timedelta(seconds=28800)))
dt.strptime('2020 10 1 15 3 0',"%Y %m %d %H %M %S"): datetime.datetime(2020, 10, 1, 15, 3)
dt.utcfromtimestamp(1602229233.1910603): datetime.datetime(2020, 10, 9, 7, 40, 33, 191060)
dt.utcnow(): datetime.datetime(2020, 10, 9, 7, 41, 31, 594095)
| Data descriptors defined here:
| fold
| hour
| microsecond
| minute
| second
| tzinfo
| Data and other attributes defined here:
| max = datetime.datetime(9999, 12, 31, 23, 59, 59, 999999)
| min = datetime.datetime(1, 1, 1, 0, 0)
| resolution = datetime.timedelta(microseconds=1)
Methods inherited from date: 方法继承于date
dt.__format__("%Y %y"): 2020 20 这里y是分大小写的
dt.isocalendar(): (2020, 41, 5) # 年序 周序 日序
dt.isoweekday(): 5 # 星期五
dt.strftime("%Y %y"): 同上__format__
dt.toordinal(): 737707 # 天序
dt.weekday(): 4 #星期五
Class methods inherited from date:类方法继承与date,类方法通常是创建对象的方法
dt.fromisocalendar(2020,20,2): datetime.datetime(2020, 5, 12, 0, 0) 因为是继承自date,所以仅能传递date的三个参数
dt.fromordinal(100000): datetime.datetime(274, 10, 16, 0, 0)
dt.today(): datetime.datetime(2020, 10, 9, 15, 55, 36, 674104) 很走运的这个可以全部显示
self.__class__.fromtimestamp(time.time()),因为self是date或datetime,所以他们实现的内容不同
timedelta类
timedelta对象表示两个不同时间之间的差值,差值的单位可以是周、天、消失、分钟、秒、微秒、毫秒等
td=datetime.timedelta(days,seconds,microseconds,milliseconds,hours,weeks)
均为可选参数,int or float + or -
from datetime import datetime,timedelta
print("1周包含的总秒数:",timedelta(days=7).total_seconds())
d=datetime.now()
print("当前本地系统时间:",d)
print("1天后:",d+timedelta(days=1))
print("1天前:",d-timedelta(days=1))
#
1周包含的总秒数: 604800.0
当前本地系统时间: 2020-10-09 16:06:46.823144
1天后: 2020-10-10 16:06:46.823144
1天前: 2020-10-08 16:06:46.823144
嗯~ 原来他们的加减运算是这样的啊
datetime(2020,1,1)-datetime(2020,10,1)
# datetime.timedelta(days=-274)
import datetime
dtd=datetime.timedelta() # datetime.timedelta(0)
| Data descriptors defined here:
| days
| Number of days.
| microseconds
| Number of microseconds (>= 0 and less than 1 second).
| seconds
| Number of seconds (>= 0 and less than 1 day).
| Data and other attributes defined here:
| max = datetime.timedelta(days=999999999, seconds=86399, microseconds=9...
| min = datetime.timedelta(days=-999999999)
| resolution = datetime.timedelta(microseconds=1)
没啥多说的,作为量程单位支持四则运算,相比时间点单位,只支持加减
Os模块
Os模块是一个用于访问操作系统功能的模块。
通过Os模块中提供的借口,可以实现如下功能:
(1)获取平台信息
(2)目录、文件操作
(3)调用系统命令
PS: 模块中有着众多的信息,这次真的只是一小部分了
获取平台信息
os.getcwd(): 'F:\\2019\\Documents\\python' # 获取当前工作目录
cwd: current working directory 当前工作目录
os.sep: '\\' # 路径分隔符
os.linesep: '\r\n' # 行 分隔符/终结符
os.pathsep: ';' # 路径 分隔符
os.name: 'nt' # 当前系统平台??? 这个和想要看到的不一样啊 网上查了下,还有个模块如下
platform.uname(): uname_result(system='Windows', node='DESKTOP-OG8E5AJ', release='10', version='10.0.17763', machine='AMD64', processor='Intel64 Family 6 Model 60 Stepping 3, GenuineIntel') #很遗憾这边显示的只是cpuid的数据,并没有显示具体型号,想知道更详细的信息,需要例如第三方模块wmi,而单独的去查,网上并没有提供这种信息搜索的方法
os.environ: 一大串environ标记的字典,
os.environ.get("Path"): 只显示Path这一项,775 ns
os.getenv("Path"):同上,913 ns
目录、文件操作
目录操作
os.mkdir(newdir) #创建新目录newdir
os.rmdir(dir) # 删除目录dir
os.listdir([path]) # 列出目录path下的所有文件
os.chdir(path) # 改变当前脚本的工作目录为path
os.remove(file) # 删除文件file
os.rename(oldname,newname) # 重命名文件oldname
获取文件属性
# os.path.abspath(path) # 返回当前目录的绝对路径
os.path.abspath("") # 'F:\\2019\\Documents\\python'
#ps.path.split(path) # 这个仅仅是简单的分割,返回上级目录和本目录或文件,如果已经是根目录:
os.path.split("F:\\") # ('F:\\', '')
os.path.exists(path) # 判断路径是否存在,绝对路径
os.path.isfile(file) # 判断是否存在文件file
os.path.isdir(dir) # 判断是否存在目录dir
os.path.getsize(file) # 返回指定文件的大小 单位B
“” ".\"当前目录
"\"当前根目录
昨晚看了下os模块的内置文档,庞大的信息量,有点懵,里面有很大一部分都是用于自定义的继承用的抽象类,好费事的样子,也理解为什么书中只是介绍寥寥几句,真的是说不完,于是决定在啃完书之前,不再细究文档,不过官方有个简易文档,简易到介绍模块的时候根本没有以上提及的内置模块,而只是告诉使用者,有个东西,他被叫做模块,用来实现什么样的功能,然后一个极为简易的例子。
所以书中反而是介绍的更多,或者说常用的,所以从时间和信息量上考虑,大家可以取舍下,例如在校又有时间的,可以在自己的空余时间去研究下模块的每个类和每个方法,若是不在校的,就根据需求、接受程度去适当的研究!
调用系统命令
(1)os.popen(cmd[,mode[,bufsize]]): 用于由一个命令打开一个管道。cmd为系统命令,mode为模式(r或w),bufsize为文件需要的缓冲大小
(2)os.system(shell): 运行shell命令
shell脚本语言与linux命令的联系与区别
import os
os.system("mkdir d:\\newDir")
os.popen(r"c:\windows\notepad.exe")
print("程序运行成功!")
Sys模块
Sys模块提供对Python解释器的相关操作
import sys
print("参数:",sys.argv)
# 这个是运行在什么之下的参数,如果是直接运行一个.py,则现实的是这个.py的路径,以下是jupyter
['c:\\users\\jhsxy2005\\appdata\\local\\programs\\python\\python38\\lib\\site-packages\\ipykernel_launcher.py',
'-f',
'C:\\Users\\jhsxy2005\\AppData\\Roaming\\jupyter\\runtime\\kernel-f7ff9d2b-1c37-426c-91d3-9f9737169a82.json']
print("Python版本:",sys.version)
#
'3.8.3 (tags/v3.8.3:6f8c832, May 13 2020, 22:37:02) [MSC v.1924 64 bit (AMD64)]'
print("操作系统:",sys.platform)
# platform 平台 plat form 小块地的形状
win32
print("最大Int值:",sys.maxsize)
# 这里的是64位有符号整数型最大值
9223372036854775807
sys.exit(0)
#退出程序 但jupyter可能是为了防止误退出,或者方便终端操作,使用了在终端ctrl+d两次的退出方式
import sys
m=sys.maxsize
c=0
m=m+1
while 1:
m=m/2
if m>=1:c+=1
else:break
print(c)
#
63
我总是转不过弯了,每次遇到这个问题,都要举例才能确认,而且这个while习惯了这个用法,反而觉得心里踏实。
7.77 µs
import sys
m=sys.maxsize
c=0
m=m+1
while m>1:
c+=1
m=m/2
7.76 µs
如果把条件放在了while后面,则需要修改数值,否则结果错误
总之无论哪种写法,都要考虑个最简案例,来确定正确性,所以逻辑上来说,都差不多。
后者书写更简单
那来个移位操作或是转换操作呢
while m>=1:
c+=1
m=m>>1
6.47 µs
len(bin(m))-2
762 ns / 299 ns 前面的耗时包括了最前面两行,看来再计算机上运算位,用计算机的思维去考虑是最迅速的,而且他明明提供了这个进制转换的函数
Timeit模块
我一直以为这是ipython的功能来着,看来是python的功能!每次码都在用的说
等等,貌似不是,且看书中例子
import timeit
def myFun():
sum=0
for i in range(1,100):
for j in range(1,100):
sum=sum+i+j
t1=timeit.timeit(stmt=myFun,number=1000)
print("t1:",t1)
t2=timeit.repeat(stmt=myFun,number=1000,repeat=6)
print("t2:",t2)
#
t1: 1.0047217999999702
t2: [1.0834287000002405, 0.8721609999997781, 0.8279990000000907, 0.7946439000002101, 0.8399140999999872, 0.8151720000000751]
这个精确到小数点后16位
计算函数的效率,这个跟PySnooper的使用方式差不多,都是针对一个函数的。
但是没有把一个完整的功能封装成一个函数的习惯的我来说,还是喜欢%%timeit
但是这个显示每次运算数的功能,很棒的样子,可以用在一些需要的地方
Zlib模块
Zlib模块支持通用的数据打包和压缩格式
(1)zlib.compress(string): 对数据string进行压缩
(2)zlib.decompress(string): 对压缩后的数据string进行解压
import zlib
str='谁敢杀我?谁敢杀我?谁敢杀我?'.encode('utf-8')
print("压缩前:%s,字符个数%d"%(str,len(str)))
str_com=zlib.compress(str)
print("压缩后:%s,字符个数%d"%(str_com,len(str_com)))
str_dec=zlib.decompress(str_com)
print("解压后:%s,字符个数%d"%(str_dec,len(str_dec)))
print("文字解码显示:%s"%str_dec.decode('utf-8'))
#
压缩前:b'\xe8\xb0\x81\xe6\x95\xa2\xe6\x9d\x80\xe6\x88\x91\xef\xbc\x9f\xe8\xb0\x81\xe6\x95\xa2\xe6\x9d\x80\xe6\x88\x91\xef\xbc\x9f\xe8\xb0\x81\xe6\x95\xa2\xe6\x9d\x80\xe6\x88\x91\xef\xbc\x9f',字符个数45
压缩后:b'x\x9c{\xb1\xa1\xf1\xd9\xd4E\xcf\xe66<\xeb\x98\xf8~\xcf\xfc\x17x\xb9\x00\xd8\x13\x1f\x87',字符个数27
解压后:b'\xe8\xb0\x81\xe6\x95\xa2\xe6\x9d\x80\xe6\x88\x91\xef\xbc\x9f\xe8\xb0\x81\xe6\x95\xa2\xe6\x9d\x80\xe6\x88\x91\xef\xbc\x9f\xe8\xb0\x81\xe6\x95\xa2\xe6\x9d\x80\xe6\x88\x91\xef\xbc\x9f',字符个数45
文字解码显示:谁敢杀我?谁敢杀我?谁敢杀我?
书中例子是str=b’What is your name?What is your name?What is your name?’,也就是说这个库处理的是二进制,所以需要将字符串转换成二进制,书中的写法只适用于ACSII,如果有以外的字符,就需要是用其他方式转换成二进制
常用第三方库
NumPy: 使用Python实现的科学计算库
Pandas: 基于NumPy的数据分析库
SciPy: 一款方便、易于使用、专为科学和工程设计的工具库
Matplotlib: 功能强大的2D绘图库
Jieba: 强大的分词库,完美支持中文分词
Pyinstaller: 将Pyrhon程序打包成应用程序的库
wxPython: 图形界面(GUI)编程库
Scrapy: 基于Python的快速、高层次的数据抓取库,用于抓取Web站点并从页面中提取结构化数据
Django: 开源Web应用框架,鼓励快速开发,遵循MVC设计,开发周期短
Scikit-learn: 基于Python语言、简单高效的机器学习库
TensorFlow: 一个深度学习框架,采用数据流图,用于高性能数值计算的开源软件库
PyGame: 基于Python的多媒体开发和游戏软件开发库
除了最后一项,其他内容都将在本书之后章节提到
NumPy库 (需要代数相关知识)
文档:https://www.numpy.org.cn/reference/
书中介绍比较简洁,这里先过一遍书,如果文档不过于复杂,再过一遍文档!
NumPy是基于Python的一种开源数值计算第三方库,他支持高维数组运算、大型矩阵处理、矢量运算、线性代数运算、随机数生成等功能。这里仅介绍最常用的数组运算与线性代数有关的操作
数组
NumPy库中的ndarray是一个多维数组对象。该对象由两部分组成:实际的数据和描述这些数据的元数据
和Python中的列表、元组一样,NumPy数组的下标也是从0开始的
(1)创建数组
在NumPy库中,创建数组的常用方法之一是使用np.array()函数,其一般格式为:
numpy.array(object,dtype=None,copy=True,order=None,subok=False,ndmin=0)
object: 数组或嵌套的数列
dtype: 数组元素的数据类型
copy: 指定对象是否需要复制???
order: 创建数组的样式,C为行方向,F为列方向,A为任意方向(默认)内存中的排列方式?
subok: 指定默认返回一个与基类类型一致的数组
ndmin: 指定生成数组的最小维度
array: 数组
import numpy as np
np.array([1,2,3,4,5,6]) #一维数组
array([1,2,3,4,5,6])
np.array([1,2,3,4,5,6]).reshape(2,3) #二维数组
array([[1, 2, 3],
[4, 5, 6]])
np.array([1,2,3,4,5,6]).reshape(3,2)
array([[1, 2],
[3, 4],
[5, 6]])
np.array([1,3,5],dtype=complex)
array([1.+0.j,3.+0.j,5.+0.j])
np.array([2,4,6],ndmin=2) #指定最小维度 注意[] 意义?
array([[2,4,6]])
np.array([[1,2,3],[4,5,6]],ndmin=3)
array([[[1, 2, 3],
[4, 5, 6]]])
arange([start,]stop[,step],dtype=None) stop: int or float
结果是整数,几遍是float也是整数加点,类似于range
linspace(start,stop,num=50,endpoint=True,restep=False,dtype=None,axis=0)
线性等分向量
logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None, axis=0)
对数等分向量
例 创建指定数组
import numpy as np
np.arange(6)
array([0,1,2,3,4,5])
np.arange(6,dtype=float)
np.arange(6.0)
array([0., 1., 2., 3., 4., 5.])
np.arange(1,10,2)
array([1,3,5,7,9])
np.linspace(1,10,10) # 列出从1到10的10个数
array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])
np.linspace(1,10,9)
array([ 1. , 2.125, 3.25 , 4.375, 5.5 , 6.625, 7.75 , 8.875, 10. ])
np.linspace(1,10,9,0)
array([1., 2., 3., 4., 5., 6., 7., 8., 9.])
np.linspace(1,10,9,0,1)
(array([1., 2., 3., 4., 5., 6., 7., 8., 9.]), 1.0)
np.linspace(1,10,9,0,0,int)
array([1, 2, 3, 4, 5, 6, 7, 8, 9])
axis???
np.logspace(2,4,6,8,10)
array([ 100. , 251.18864315, 630.95734448, 1584.89319246,
3981.07170553, 10000. ])
np.zeros((2,2))
array([[0., 0.],
[0., 0.]])
np.ones((2,3))
array([[1., 1., 1.],
[1., 1., 1.]])
(2) 数组切片和索引
import numpy as np
a=np.arange(10)
a[5] # 5
a[1:6:2] # array([1,3,5])
b=np.array([[1,2,3],[4,5,6],[7,8,9]])
b[2,2] # 9 # 185 ns vs b[2][2] 350 ns
b[1:]
array([[4,5,6],
[7,8,9]])
(3) 数组属性
NumPy数组的常用属性如下
- ndarray.ndim: 秩, 即轴的数量或维度的数量
- ndarray.shape: 数组的维度
- ndarray.size: 数组元素的总个数
- ndarray.dtype: 数组元素类型
- ndarray.itemsize: 数组中每个元素的大小, 以字节为单位
查看数组属性
import numpy as np
a=np.arange(24).reshape(2,3,4)
a.ndim # 3 维度 索引1 索引2 索引3 才定位到某个元素
a.shape # (2,3,4)
a.size # (24)
a.dtype # dtype('int32') # '0' 'float64'
a.itemsize 4 #
(4) 数组操作
- reshape(): 在不改变数据的条件下修改形状
- flat: 数组元素迭代器
- ravel(): 返回展开数组
- np.transpose(a): 对换数组的维度. 也可以使用数组的属性ndarray.T
import numpy as np
a=np.array(8)
a.reshape(2,4)
#
array([[0, 1, 2, 3],
[4, 5, 6, 7]])
np.transpose(a.reshape(2,4))
#
array([[0, 4],
[1, 5],
[2, 6],
[3, 7]])
np.transpose(a.reshape(2,4)).ravel()
#
array([0, 4, 1, 5, 2, 6, 3, 7])
for element in a.flat: # a.flat (5) 数组运算
- +/-: 两个相同类型和形状的数组进行加法、减法运算
- *: 一个数组和1个数相乘
- np.dot(a,b): 对于两个一维的数组a、b,计算的是两个数组对应下标元素的乘积和(数学上称之为内积);对于二维数组a、b,计算的是两个数组的矩阵乘积。
4)np.vdot(a,b):返回两个数组a和b的点积
5)np.inner(a,b): 返回一维数组a、b的向量内积
6)np.matmul(a,b): 返回两个数组a、b的矩阵乘积
7)np.linalg.det(a): 计算二维数组a(相当于矩阵)的行列式
8)np.linalg.inv(a): 计算二位数组a(相当于矩阵)的逆矩阵
import numpy as np
a=np.array([[1,2],[3,4]])
a*2
#
array([[2, 4],
[6, 8]])
b=np.array([[5,6],[7,8]])
a+b
#
array([[ 6, 8],
[10, 12]])
np.dot(a,b) # 两个数组的内积
array([[19, 22],
[43, 50]])
np.matnul(a,b) # 两个数组相乘
array([[19, 22],
[43, 50]])
# 1*5+2*7=19,1*6+2*8=22,3*5+4*7=43,3*6+4*8=50
np.vdot(a,b) # 两个数组的点积
70
# 1*5+2*6+3*7+4*8=70
np.inner(a,b) # 两个数组的向量内积
array([[17, 23],
[39, 53]])
# 1*5+2*6=17,1*7+2*8=23,3*5+4*6=39,3*7+4*8=53
np.linalg.det(a) # 求矩阵行列式
-2.0000000000000004
np.linalg.inv(a) # 求逆矩阵
array([[-2. , 1. ],
[ 1.5, -0.5]])
这是嘛?这怎么算出来的?这干嘛用的?
numpy 矩阵积(点积)
矩阵
在NumPy中,通常使用mat()函数或matrix()函数创建矩阵,也可以通过矩阵的转置、逆矩阵等方法来创建矩阵
import numpy as np
A=np.mat("3 4;5 6") # 创建矩阵
matrix([[3, 4],
[5, 6]])
A.T # 转置矩阵
matrix([[3, 5],
[4, 6]])
A.I # 逆矩阵
matrix([[-3. , 2. ],
[ 2.5, -1.5]])
np.mat(np.arange(9).reshape(3,3)) # 由数据创建矩阵
matrix([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
矩阵运算和数组运算相似
import numpy as np
A=np.mat('1,2;3,4')
A*2 # 矩阵*数
matrix([[2, 4],
[6, 8]])
B=np.mat('5,6;7,8')
A+B # 矩阵相加
matrix([[ 6, 8],
[10, 12]])
A.dot(B) # 矩阵点积
matrix([[19, 22],
[43, 50]])
np.matmul(A,B) # 矩阵相乘
matrix([[19, 22],
[43, 50]])
np.inner(A,B) # 矩阵内积
matrix([[17, 23],
[39, 53]])
np.linalg.inv(A) # 逆矩阵
matrix([[-2. , 1. ],
[ 1.5, -0.5]])
np.linalg.det(A) # 行列式
2.0000000000000004
见下篇
内容太多,重新开篇