全卷积神经网络(FCN)的keras实现
全卷积神经网络(FCN)的keras实现
- 前言
前一阵子写了一篇图像分割的综述,学习了包括图像预处理 、阈值图像分割、神经网络图像语义分割等一些知识,通过matlab和python进行了实现,不过一直没有时间进行分享,现在手头忙的事情基本完成,所以进行下总结与分享。FCN可以算是语义分割方向的开山之作了,也是我入坑语义 学习的第一个网络了,最开始用tenserflow写起来费劲的要死,后来改用keras很快就写好了,所以先拿来分享一下,希望以后学习的同学少走些弯路。
- 全卷积神经网络理论知识
全卷积神经网络是由Jonathan Long,Evan Shelhamer,Trevor Darrell等人于文章"Fully Convolutional Networks for Semantic Segmentation"中提出的,文章于2015年发表在计算机视觉顶会CVPR上。
文章链接:
https://openaccess.thecvf.com/content_cvpr_2015/papers/Long_Fully_Convolutional_Networks_2015_CVPR_paper.pdf
FCN是在VGG16的基础上进行改进得到的,首先我们简单回顾下VGG16的结构。

VGG-16是一个用于图像分类的卷积神经网络,上图展示了VGG的结构,图中展示了几个不的同版本,包括11层的(A,A-LRN)、13层的(B)、16层的(C,D)和19层的(E),其中流传最广的就是16层的版本(图中的D列),也就是我们常说的VGG-16。其结构主要由5个卷积池化模块和3个全连接层外加一个组成,FCN文章把VGG-16的结构绘制成了如下图像:
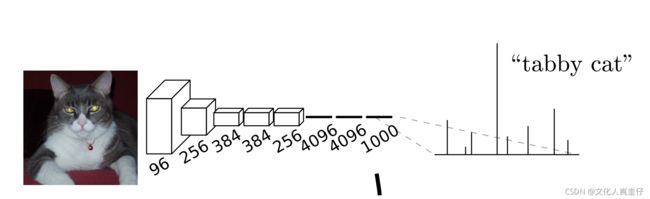
上面这个图象所展示的VGG-16就比较直观了,前面5个卷积池化模块对图像中的信息进行提取和压缩,后面三个全连接层将信息进一步传入softmax分类器中,最后通过softmax判断图像到底属于哪一类。
但是对于图像分割任务来说,图像信息已经被前面五个模块高度编码了,位置信息丢失严重,无法进行精准的定位,所以FCN提出了一种方法 :将编码信息重新解码。通过这种方法还原位置信息以进行精准的图像分割。
此外,FCN还将VGG-16最后的三个全连接层替换为1×1大小的卷积层,这一改变极大的减少了需要训练的参数数量。FCN的结构见下图:
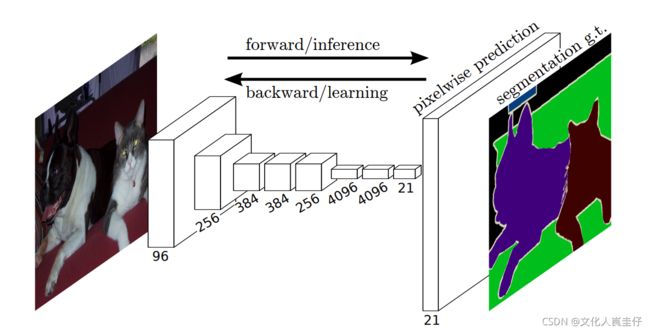
除了上述改变以外,FCN还提出了一种跳层连接结构,即对压缩的图像进行上采样(放大)后,融合对应大小的浅层图像信息,这样能更好地还原图像的原始信息,提高图像的分割精度。
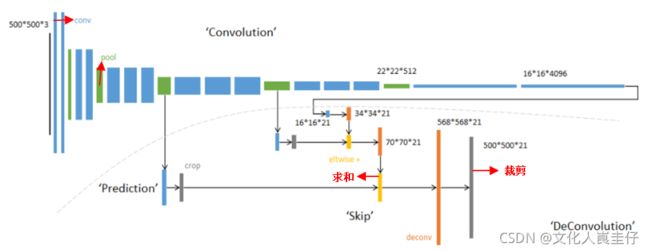
上图展示了FCN-8s的跳层连接结构,FCN-8s即在之前讲解的框架的基础上进行了名为8s的跳层连接结构,下面我老详细解释一下。在上图中,图像经过5次压缩(绿色部分)后,图像大小变为原来的1/32大小(第五个绿色块),经过后面的两层1×1卷积后(大小不变),先对图像进行一次2倍的上采样(放大),图像就变为原来的1/16大小了,然后提取前面池化层1/16大小的图像信息(第4个绿色块),将两部分的信息进行融合(求和),并再一次进行2倍的上采样,此时图像变为原来的1/8大小,再次提取前面池化层1/8大小的图像信息(第3个绿色块)并进行求和,这样得到的信息还是原来的1/8大小,最后直接对这个信息(张量)进行8倍的上采样,就得到了与原来图像大小相同的图像信息了,对此信息的每个像素点进行分类就可以得到与原图大小相同的分割图像了。之所以叫8s,应该是最后一次进行了8倍的上采样。
通过以上的三点改变,用于图像分类的VGG-16网络就被改编成了用于图像分割工作的网络了。
- FCN的keras实现
FCN的keras库代码如下:
from keras.applications import vgg16
from keras.models import Model, Sequential
from keras.layers import Conv2D, Conv2DTranspose, Input, MaxPooling2D, add, Dropout, core, Activation
from keras import optimizers
#nClasses为分类数目, input_height和input_width为输入图像的高度和宽度的像素数量, nChannels为输入图像的通道数
def FCN_8S(nClasses, input_height, input_width, nChannels):
inputs = Input((input_height, input_width, nChannels))
###编码器部分
conv1 = Conv2D(filters=32, input_shape=(input_height, input_width, 1),
kernel_size=(3, 3), padding='same', activation='relu',
name='block1_conv1')(inputs)
conv1 = Conv2D(filters=32, kernel_size=(3, 3), padding='same', activation='relu',
name='block1_conv2')(conv1)
pool1 = MaxPooling2D(pool_size=(2, 2), name='block1_pool')(conv1)
conv2 = Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu',
name='block2_conv1')(pool1)
conv2 = Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu',
name='block2_conv2')(conv2)
pool2 = MaxPooling2D(pool_size=(2, 2), name='block2_pool')(conv2)
conv3 = Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu',
name='block3_conv1')(pool2)
conv3 = Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu',
name='block3_conv2')(conv3)
conv3 = Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu',
name='block3_conv3')(conv3)
pool3 = MaxPooling2D(pool_size=(2, 2), name='block3_pool')(conv3)
score_pool3 = Conv2D(filters=nClasses, kernel_size=(3, 3), padding='same',
activation='relu', name='score_pool3')(pool3)#此行代码为后面的跳层连接做准备
conv4 = Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu',
name='block4_conv1')(pool3)
conv4 = Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu',
name='block4_conv2')(conv4)
conv4 = Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu',
name='block4_conv3')(conv4)
pool4 = MaxPooling2D(pool_size=(2, 2), name='block4_pool')(conv4)
score_pool4 = Conv2D(filters=nClasses, kernel_size=(3, 3), padding='same',
activation='relu', name='score_pool4')(pool4)#此行代码为后面的跳层连接做准备
conv5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu',
name='block5_conv1')(pool4)
conv5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu',
name='block5_conv2')(conv5)
conv5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu',
name='block5_conv3')(conv5)
pool5 = MaxPooling2D(pool_size=(2, 2), name='block5_pool')(conv5)
###1×1卷积部分,加入了Dropout层以免过拟合
fc6 = Conv2D(filters=1024, kernel_size=(1, 1), padding='same', activation='relu',
name='fc6')(pool5)
fc6 = Dropout(0.3, name='dropout_1')(fc6)
fc7 = Conv2D(filters=1024, kernel_size=(1, 1), padding='same', activation='relu',
name='fc7')(fc6)
fc7 = Dropout(0.3, name='dropour_2')(fc7)
###下面的代码为跳层连接结构
score_fr = Conv2D(filters=nClasses, kernel_size=(1, 1), padding='same',
activation='relu', name='score_fr')(fc7)
score2 = Conv2DTranspose(filters=nClasses, kernel_size=(2, 2), strides=(2, 2),
padding="valid", activation=None,
name="score2")(score_fr)
add1 = add(inputs=[score2, score_pool4], name="add_1")
score4 = Conv2DTranspose(filters=nClasses, kernel_size=(2, 2), strides=(2, 2),
padding="valid", activation=None,
name="score4")(add1)
add2 = add(inputs=[score4, score_pool3], name="add_2")
UpSample = Conv2DTranspose(filters=nClasses, kernel_size=(8, 8), strides=(8, 8),
padding="valid", activation=None,
name="UpSample")(add2)
outputs = Conv2D(1, 1, activation='sigmoid')(UpSample)
#因softmax的特性,跳层连接部分的卷积层都有nClasses个卷积核,以保证softmax的运行
model = Model(inputs=inputs, outputs=outputs)
model.summary()
return model
训练代码如下:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1"
from model import FCN_8S
from keras.callbacks import ModelCheckpoint, TensorBoard
from data import trainGenerator
import tensorflow as tf
from keras.optimizers import Adam
config = tf.compat.v1.ConfigProto()
config.gpu_options.allow_growth = True
tf.compat.v1.keras.backend.set_session(tf.compat.v1.Session(config=config))
#以上三行代码为TF2.0解决GPU缓存问题的代码,TF1.0与此代码不同
nClasses = 2
input_height = 512
input_width = 512
nChannels = 1
train_batch_size = 2
epochs = 500
mymodel = FCN_8S(nClasses, input_height, input_width, nChannels)
#导入模型
mymodel.compile(optimizer=Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy'])
#设定数据增强参数
data_gen_args = dict(rotation_range=0.2, #整数。随机旋转的度数范围。 width_shift_range=0.05, #浮点数、一维数组或整数
height_shift_range=0.05, #浮点数。剪切强度(以弧度逆时针方向剪切角度)。shear_range=0.05,
zoom_range=0.05, #浮点数 或 [lower, upper]。随机缩放范围horizontal_flip=True,
fill_mode='nearest')
# 建立测试集,样本和标签分别放在同一个目录下的两个文件夹中,文件夹名字为:'image','label'
myGene = trainGenerator(train_batch_size,'./data/train','image','label',data_gen_args,save_to_dir = None)
#得到一个生成器,以batch=1的速率无限生成增强后的数据
model_checkpoint = ModelCheckpoint('fcn-500.hdf5', monitor='loss',verbose=1, save_best_only=True)
#设定储存Check point的参数
mymodel.fit_generator(generator=myGene,steps_per_epoch=90,epochs=epochs, callbacks=[model_checkpoint])
#对模型进行训练
测试代码如下:
from model import FCN_8S
from data import *
import tensorflow as tf
physical_devices = tf.config.experimental.list_physical_devices('GPU')
assert len(physical_devices) > 0, "Not enough GPU hardware devices available"
tf.config.experimental.set_memory_growth(physical_devices[0], True)
# 输入测试数据集,
testGene = testGenerator("data/moni", num_image=10, target_size=(512, 512))
# 导入模型
mymodel = FCN_8S(2,512, 512, 1) # model
# 导入训练好的模型
mymodel.load_weights("fcn-T4-500.hdf5")
# 预测数据
results = mymodel.predict_generator(testGene, 10, verbose=1) # keras
saveResult("data/pre", results) #保存预测图片
print("over")
我用512×512像素的灰度图像对模型进行了训练,效果还不错,就是图像边缘的锯齿感比较严重。

最左边是待分割的图像,中间是人工手动分割的图像,右边是FCN-8s的分割结果,可以看到相对于人工的分割,FCN分割结果的锯齿很严重,所以我对代码进行了改进,多进行了两次的跳层连接,按照FCN文章中的命名规则应该叫FCN-2s,经过这次变动后,模型的分割效果就很好了

虽然还是有小的目标分割不出来,不过精度已经很高了,MIoU能达到98%。
以上内容希望能帮助到各位初学者。