pytorch+LSTM分类MINIST数据集
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision.datasets as dsets
from torch.autograd import Variable
from torch.nn import Parameter
from torch import Tensor
import torch.nn.functional as F
import math
cuda = True # 用cuda计算
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# 如果启用cuda运算,Tensor就用cuda.FloatTensor否则就用torch.FloatTensor
torch.manual_seed(123) # 设置一个随机数的种子,torch.rand(1)可以生成[0,1)之间的随机数
print(torch.cuda.is_available())
if torch.cuda.is_available():
torch.cuda.manual_seed_all(123) # 在所有GPU上设置随机数
"""
加载MNIST数据集
"""
train_data = dsets.MNIST(
root=r'D:\python\minist', # 存储路径
train=True,
transform=transforms.ToTensor(), # 把下载的数据改成Tensor形式
# 把(0-255)转换成(0-1)
download=False # 如果没下载就确认下载
)
test_data = dsets.MNIST(
root=r'D:\python\minist', # 存储路径
train=False,
transform=transforms.ToTensor(), # 把下载的数据改成Tensor形式
# 把(0-255)转换成(0-1)
download=False # 如果没下载就确认下载
)
print(train_data)
print(test_data)
"""
超参数的设定
"""
batch_size = 100 # 一批数据100个
num_epochs = 100 # 对全部数据训练的次数
"""
把数据做成迭代器,批处理数据
"""
train_loader = torch.utils.data.DataLoader(dataset=train_data,batch_size=batch_size,shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_data,batch_size=batch_size,shuffle=True)
"""
一个LSTM单元
"""
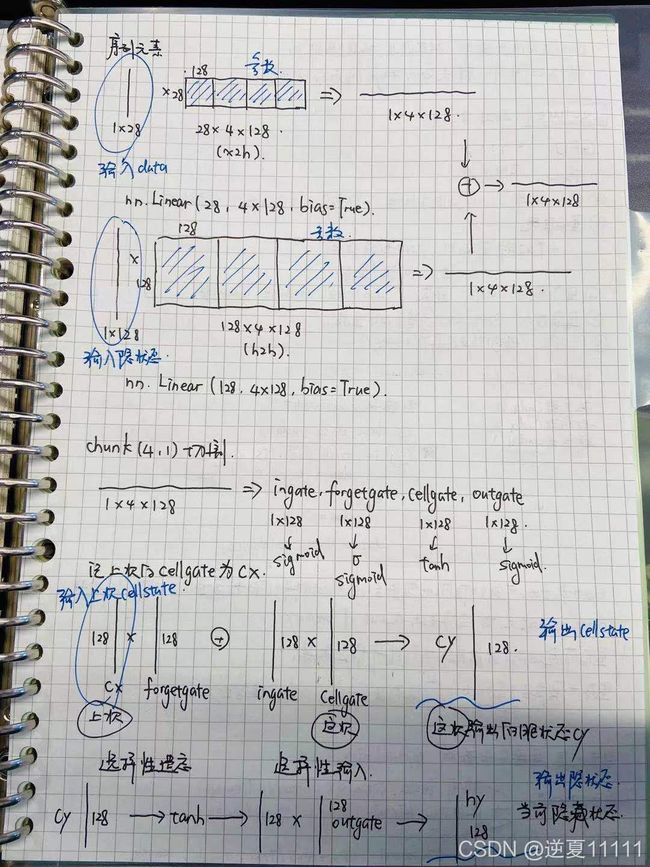
class LSTMCell(nn.Module):
def __init__(self,input_size,hidden_size):
super(LSTMCell,self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.x2h = nn.Linear(input_size,4*hidden_size,bias=True) # 28,4*128 这是对输入x进行运算的参数矩阵
# 4表示4个不同的w,U,遗忘门输出门各一个,输入门有两个
self.h2h = nn.Linear(hidden_size,4*hidden_size,bias=True) # 128,4*128 这是对h进行运算的参数矩阵
def forward(self, x,hx,cx):
# x:100,28
# hx:100,128
# cx:100,128
# x,hx,cx分别为 这一时刻的数据,上一时刻的隐状态,细胞状态
gates = self.x2h(x)+self.h2h(hx)
# 得到三个门的状态和细胞状态
# 切分成四个部分
ingate,forgetgate,cellgate,outgate = gates.chunk(4,1)
ingate = F.sigmoid(ingate) # 输入们用sigmoid对输入进行运算
forgetgate = F.sigmoid(forgetgate) # 遗忘门作sigmoid运算
outgate = F.sigmoid(outgate) # 输出门做sigmoid运算
cellgate = F.tanh(cellgate) # 细胞状态做一个tanh的运算
# 输出这一时刻的隐状态和细胞状态
cy = torch.mul(cx,forgetgate)+torch.mul(ingate,cellgate)
hy = torch.mul(outgate,F.tanh(cy))
return hy,cy
chunk的作用是对tensor进行分块处理
假设有这样一个tensor类型的数
data = torch.from_numpy(np.random.rand(3, 5))
print(str(data))
>>
tensor([[0.6742, 0.5700, 0.3519, 0.4603, 0.9590],
[0.9705, 0.8673, 0.8854, 0.9029, 0.5473],
[0.0199, 0.4729, 0.4001, 0.7581, 0.5045]], dtype=torch.float64)
横向分块
for i, data_i in enumerate(data.chunk(5, 1)): # 沿1轴分为5块
print(str(data_i))
>>
tensor([[0.6742],
[0.9705],
[0.0199]], dtype=torch.float64)
tensor([[0.5700],
[0.8673],
[0.4729]], dtype=torch.float64)
tensor([[0.3519],
[0.8854],
[0.4001]], dtype=torch.float64)
tensor([[0.4603],
[0.9029],
[0.7581]], dtype=torch.float64)
tensor([[0.9590],
[0.5473],
[0.5045]], dtype=torch.float64)
纵向分块
for i, data_i in enumerate(data.chunk(3, 0)): # 沿0轴分为3块
print(str(data_i))
>>
tensor([[0.6742, 0.5700, 0.3519, 0.4603, 0.9590]], dtype=torch.float64)
tensor([[0.9705, 0.8673, 0.8854, 0.9029, 0.5473]], dtype=torch.float64)
tensor([[0.0199, 0.4729, 0.4001, 0.7581, 0.5045]], dtype=torch.float64)
除不尽的情况
for i, data_i in enumerate(data.chunk(3, 1)): # 沿1轴分为3块,除不尽
print(str(data_i))
>>
tensor([[0.6742, 0.5700],
[0.9705, 0.8673],
[0.0199, 0.4729]], dtype=torch.float64)
tensor([[0.3519, 0.4603],
[0.8854, 0.9029],
[0.4001, 0.7581]], dtype=torch.float64)
tensor([[0.9590],
[0.5473],
[0.5045]], dtype=torch.float64)
"""
对定义好的单元进行循环
"""
class LSTMModel(nn.Module):
def __init__(self,input_dim,hidden_dim,output_dim):
super(LSTMModel,self).__init__()
self.hidden_dim = hidden_dim
self.lstm = LSTMCell(input_dim,hidden_dim)
self.fc = nn.Linear(hidden_dim,output_dim)# 手写数字识别是一个分类任务,需要连接一个分类的全连接层
def forward(self,x):
# 初始化hidden state
if torch.cuda.is_available(): # 如果cuda可用初始化之后需要加载到GPU里面去
h0 = Variable(torch.zeros(x.size(0), self.hidden_dim).cuda())
else:
h0 = Variable(torch.zeros(x.size(0),self.hidden_dim))
# 初始化cell state
if torch.cuda.is_available():
c0 = Variable(torch.zeros(x.size(0),self.hidden_dim).cuda())
else:
c0 = Variable(torch.zeros(x.size(0),self.hidden_dim))
outs = []
cn = c0 # 100,128
hn = h0 # 100,128
#X:100, 28, 28
for seq in range(x.size(1)): # 对序列长度进行遍历,每次循环一次lstm单元
hn,cn = self.lstm(x[:,seq,:],hn,cn)
outs.append(hn)
# 取最后的输出
out = outs[-1].squeeze()
# 经过全连接层
out = self.fc(out)
return out
"""
初始化模型
"""
# 每张图片按照28*28的序列数据输入
seq_dim = 28
input_dim = 28
hidden_dim = 128
output_dim = 10
model = LSTMModel(input_dim, hidden_dim, output_dim)
if torch.cuda.is_available():
model.cuda()
# 损失器
criterion = nn.CrossEntropyLoss()
# 优化器
learning_rate = 0.3
optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate)
"""
模型训练部分
"""
loss_list = []
iter = 0
for epoch in range(num_epochs):
for i, (images,labels) in enumerate(train_loader):
#批次化提取数据
if torch.cuda.is_available():
images = Variable(images.view(-1,seq_dim,input_dim).cuda())
labels = Variable(labels.cuda())
else:
images = Variable(images.view(-1,seq_dim,input_dim))
labels = Variable(labels)
# 清空梯度
optimizer.zero_grad()
# 计算损失
outputs = model(images)
loss = criterion(outputs, labels)
if torch.cuda.is_available():
loss.cuda()
# 梯度反向传播
loss.backward()
# 梯度更新
optimizer.step()
# 记录每一步的损失
loss_list.append(loss.item())
iter += 1
# 每轮有60000张图片,每次训练100张,就是需要600个iter
# 那100轮就是60000个iter,每500个iter打印一次,打印120次结果
# 每500次打印一次loss
if iter %500 == 0:
# 计算准确率
correct = 0
total = 0
for images,labels in test_loader:
if torch.cuda.is_available():
images = Variable(images.view(-1,seq_dim,input_dim).cuda())
else:
images = Variable(images.view(-1,seq_dim,input_dim))
with torch.no_grad():
outputs = model(images)
# 取最大值所在下标为预测标签
_,predicted = torch.max(outputs.data,1)
total += labels.size(0)
if torch.cuda.is_available():
correct += ((predicted == labels.cuda()).sum())
else:
correct += ((predicted == labels).sum())
accuracy = 100*correct/total
print("Iteration:{}. Loss: {}. Accuracy: {}%".format(iter,loss.item(),accuracy))
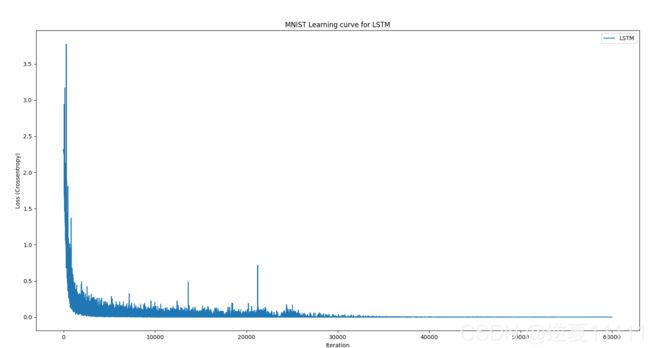
画图
import matplotlib.pyplot as plt
plt.xlabel("Iteration")
plt.ylabel("Loss (Crossentropy)")
plt.title("MNIST Learning curve for LSTM")
plt.plot(loss_list,label="LSTM")
plt.legend()
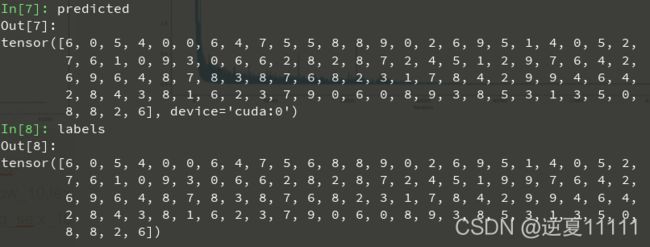
测试数据的最后一个batch的分类结果,非常正确!
完整
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision.datasets as dsets
from torch.autograd import Variable
from torch.nn import Parameter
from torch import Tensor
import torch.nn.functional as F
import math
cuda = True # 用cuda计算
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# 如果启用cuda运算,Tensor就用cuda.FloatTensor否则就用torch.FloatTensor
torch.manual_seed(123) # 设置一个随机数的种子,torch.rand(1)可以生成[0,1)之间的随机数
print(torch.cuda.is_available())
if torch.cuda.is_available():
torch.cuda.manual_seed_all(123) # 在所有GPU上设置随机数
"""
加载MNIST数据集
"""
train_data = dsets.MNIST(
root=r'D:\python\minist', # 存储路径
train=True,
transform=transforms.ToTensor(), # 把下载的数据改成Tensor形式
# 把(0-255)转换成(0-1)
download=False # 如果没下载就确认下载
)
test_data = dsets.MNIST(
root=r'D:\python\minist', # 存储路径
train=False,
transform=transforms.ToTensor(), # 把下载的数据改成Tensor形式
# 把(0-255)转换成(0-1)
download=False # 如果没下载就确认下载
)
print(train_data)
print(test_data)
"""
超参数的设定
"""
batch_size = 100 # 一批数据100个
num_epochs = 100 # 对全部数据训练的次数
"""
把数据做成迭代器,批处理数据
"""
train_loader = torch.utils.data.DataLoader(dataset=train_data,batch_size=batch_size,shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_data,batch_size=batch_size,shuffle=True)
"""
一个LSTM单元里面的运算
"""
class LSTMCell(nn.Module):
def __init__(self,input_size,hidden_size):
super(LSTMCell,self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.x2h = nn.Linear(input_size,4*hidden_size,bias=True) # 28,4*128 这是对输入x进行运算的参数矩阵
# 4表示4个不同的w,U,遗忘门输出门各一个,输入门有两个
self.h2h = nn.Linear(hidden_size,4*hidden_size,bias=True) # 128,4*128 这是对h进行运算的参数矩阵
def forward(self, x,hx,cx):
# x:100,28
# hx:100,128
# cx:100,128
# x,hx,cx分别为 这一时刻的输入数据,上一时刻的隐状态,细胞状态
gates = self.x2h(x)+self.h2h(hx)
# 得到三个门的状态和细胞状态
# 切分成四个部分
ingate,forgetgate,cellgate,outgate = gates.chunk(4,1)
ingate = F.sigmoid(ingate) # 输入们用sigmoid对输入进行运算
forgetgate = F.sigmoid(forgetgate) # 遗忘门作sigmoid运算
outgate = F.sigmoid(outgate) # 输出门做sigmoid运算
cellgate = F.tanh(cellgate) # 细胞状态做一个tanh的运算
# 输出这一时刻的隐状态和细胞状态
cy = torch.mul(cx,forgetgate)+torch.mul(ingate,cellgate)
hy = torch.mul(outgate,F.tanh(cy))
return cy,hy
"""
对定义好的单元进行循环
"""
class LSTMModel(nn.Module):
def __init__(self,input_dim,hidden_dim,output_dim):
super(LSTMModel,self).__init__()
self.hidden_dim = hidden_dim
self.lstm = LSTMCell(input_dim,hidden_dim)
self.fc = nn.Linear(hidden_dim,output_dim)# 手写数字识别是一个分类任务,需要连接一个分类的全连接层
def forward(self,x):
# 初始化hidden state
if torch.cuda.is_available(): # 如果cuda可用初始化之后需要加载到GPU里面去
h0 = Variable(torch.zeros(x.size(0), self.hidden_dim).cuda())
else:
h0 = Variable(torch.zeros(x.size(0),self.hidden_dim))
# 初始化cell state
if torch.cuda.is_available():
c0 = Variable(torch.zeros(x.size(0),self.hidden_dim).cuda())
else:
c0 = Variable(torch.zeros(x.size(0),self.hidden_dim))
outs = []
cn = c0 # 100,128
hn = h0 # 100,128
#X:100, 28, 28
for seq in range(x.size(1)): # 对序列长度进行遍历,每次循环一次lstm单元
hn,cn = self.lstm(x[:,seq,:],hn,cn)
outs.append(hn)
# 取最后的输出
out = outs[-1].squeeze()
# 经过全连接层
out = self.fc(out)
return out
"""
初始化模型
"""
# 每张图片按照28*28的序列数据输入
seq_dim = 28
input_dim = 28
hidden_dim = 128
output_dim = 10
model = LSTMModel(input_dim, hidden_dim, output_dim)
if torch.cuda.is_available():
model.cuda()
# 损失器
criterion = nn.CrossEntropyLoss()
# 优化器
learning_rate = 0.3
optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate)
"""
模型训练部分
"""
loss_list = []
iter = 0
for epoch in range(num_epochs):
for i, (images,labels) in enumerate(train_loader):
#批次化提取数据
if torch.cuda.is_available():
images = Variable(images.view(-1,seq_dim,input_dim).cuda())
labels = Variable(labels.cuda())
else:
images = Variable(images.view(-1,seq_dim,input_dim))
labels = Variable(labels)
# 清空梯度
optimizer.zero_grad()
# 计算损失
outputs = model(images)
loss = criterion(outputs, labels)
if torch.cuda.is_available():
loss.cuda()
# 梯度反向传播
loss.backward()
# 梯度更新
optimizer.step()
# 记录每一步的损失
loss_list.append(loss.item())
iter += 1
# 每轮有60000张图片,每次训练100张,就是需要600个iter
# 那100轮就是60000个iter,每500个iter打印一次,打印120次结果
# 每500次打印一次loss
if iter %500 == 0:
# 计算准确率
correct = 0
total = 0
for images,labels in test_loader:
if torch.cuda.is_available():
images = Variable(images.view(-1,seq_dim,input_dim).cuda())
else:
images = Variable(images.view(-1,seq_dim,input_dim))
with torch.no_grad():
outputs = model(images)
# 取最大值所在下标为预测标签
_,predicted = torch.max(outputs.data,1)
total += labels.size(0)
if torch.cuda.is_available():
correct += ((predicted == labels.cuda()).sum())
else:
correct += ((predicted == labels).sum())
accuracy = 100*correct/total
print("Iteration:{}. Loss: {}. Accuracy: {}%".format(iter,loss.item(),accuracy))
import matplotlib.pyplot as plt
plt.xlabel("Iteration")
plt.ylabel("Loss (Crossentropy)")
plt.title("MNIST Learning curve for LSTM")
plt.plot(loss_list,label="LSTM")
plt.legend()