【阅读笔记】联邦学习实战——联邦个性化推荐案例
联邦学习实战——联邦个性化推荐案例
- 前言
- 1. 引言
- 2. 传统的集中式个性化推荐
-
- 2.1 矩阵分解
- 2.2 因子分解机
- 3. 联邦矩阵分解
-
- 3.1 算法详解
- 3.2 详细实现
- 4 联邦因子分解机
-
- 4.1 算法详解
- 4.2 详细实现
- 5. 其他联邦推荐算法
- 阅读总结
前言
FATE是微众银行开发的联邦学习平台,是全球首个工业级的联邦学习开源框架,在github上拥有4000stars,可谓是相当有名气的,该平台为联邦学习提供了完整的生态和社区支持,为联邦学习初学者提供了很好的环境,否则利用python从零开发,那将会是一件非常痛苦的事情。本篇博客内容涉及《联邦学习实战》第九章内容,使用的fate版本为1.6.0,fate的安装已经在这篇博客中介绍,有需要的朋友可以点击查阅。下面就让我们开始吧。
1. 引言
个性化推荐已经广泛应用于人们生活的方方面面,比如短视频推荐、新闻推荐、商品推荐等,如何准确推荐、精准营销成了推荐算法的关键。为了更好推荐,推荐系统一般会收集海量的用户数据,这样才能对用户和推荐内容了解更全面和深入。
但是收集数据就涉及到了用户数据的隐私安全问题,随着用户的重视和相关法律法规的完善,如何在合法的前提下,使用割裂的数据持续优化模型,是推荐系统亟待解决的任务。本章从实际出发,列举几种常见的推荐算法及其实现。
2. 传统的集中式个性化推荐
集中式推荐算法流程都是收集用户的行为数据,统一上传到服务端,然后利用常见的推荐算法进行集中训练,最后将训练结果模型部署到线上。流程如下:
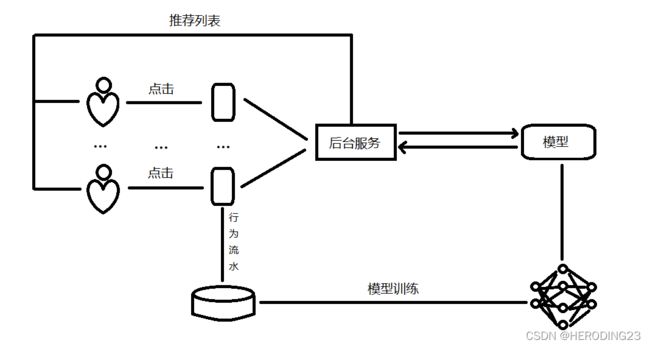
2.1 矩阵分解
简称MF,是最常使用的推荐算法之一。用户与物品之间交互方式多样,评分、点击、购买、收藏都体现人与物之间的交互,把用户对物品的反馈用一个矩阵r表示,这个矩阵也称为评分矩阵。通常这个矩阵由于用户关注的商品少,所以也是稀疏矩阵,即大部分元素都是0,这也导致了矩阵分解不能很好进行,如SVD分解。
为了应对稀疏性问题,基于隐向量的矩阵分解方法应运而生。如下图所示:
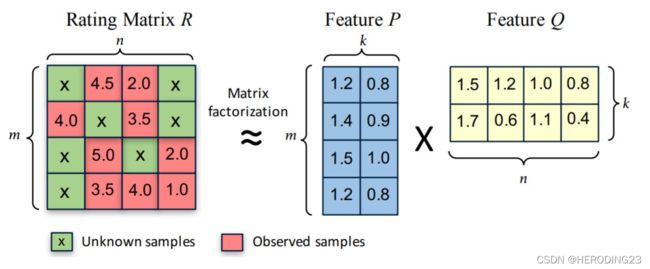
设矩阵R的维度为m×n,矩阵P的维度为m×k,矩阵Q的维度为k×n,k表示隐向量的长度,通常比较小的数,m是用户数量,n是物品的数量,通过矩阵分解,将评分矩阵压缩成两个小矩阵,分别称为用户隐向量矩阵和物品隐向量矩阵。
MF算法的核心是通过优化下式来填充和预测缺失的评分值:
m i n p , q ∑ ( i , j ) ( r i , j − < p i , q j > ) 2 + λ ∥ p ∥ 2 2 + μ ∥ q ∥ 2 2 min_{p,q}\sum_{(i,j)}(r_{i,j}-
其中, r i , j r_{i,j} ri,j代表原始评分矩阵中用户i对物品j的非0值评分, p i , q j p_i,q_j pi,qj分别代表用户和物品的隐向量,上式优化的目标是使得用户i的隐向量和物品j的隐向量之间的点积值,与评分矩阵中用户i对物品j的实际评分尽量接近。在推断预测阶段,要得到任意一个用户i与物品j的评分值,我们只需要求取用户i与物品j的隐向量点积值 < p i , q j >
2.2 因子分解机
将推荐问题归结为回归问题。传统的线性模型如线性回归,因其模型简单,所以在工业界备受推崇,但是线性模型不能捕获非线性信息,这是特征之间相互作用造成的。这种相互作用就是特征工程中常用的交叉特征,比如年龄和性别的交叉特征。
一直以来通过人为方式构造的交叉特征非常耗时,因此FM算法通过在线性模型中加入二阶信息,为自动构建和寻找交叉特征提供了一种可行的方案,FM模型如下所示,其中最后项 x i x j x_ix_j xixj,就是指任意两个特征 x i x_i xi和 x j x_j xj的交叉特征。
y = w 0 + ∑ i = 1 n w i x i + ∑ 0 < i < j ⩽ n w i , j x i x j . y=w_0+\sum_{i=1}^{n}w_ix_i+\sum_{0
但是上式最大的问题是参数数量太大,一方面学习需要大量训练样本,二是稀疏性特点,二阶特征组合会更加稀疏,对二阶交叉稀疏 w i , j w_{i,j} wi,j的学习很不理想。
FM算法利用向量化思想来优化。为每一个特征值 x i x_i xi学习大小为k维的特征向量 v i v_i vi,将上式中二阶项权重参数 w i , j w_{i,j} wi,j看成特征 x i x_i xi与特征 x j x_j xj对应的特征向量的点积,即满足 w i , j = < v i , v j > w_{i,j}=
y = w 0 + ∑ i = 1 n w i x i + ∑ 0 < i < j ⩽ n < v i , v j > x i x j . y=w_0+\sum_{i=1}^{n}w_ix_i+\sum_{0
这样做的好处是:
- 二阶项权重参数数量大大减少。参数量由原来的n(n-1)/2下降到nk。
- 每个特征 x i x_i xi对应的特征向量为 v i v_i vi,是一个k维的稠密向量,因此即使在训练样本中两个特征 x i x_i xi和 x j x_j xj没同时出现,它们交叉特征对应的权重值 < v i , v j >
当前的个性化推荐系统设计,通常是以一家公司为独立单位进行的,如果能联合用户在不同公司的行为数据,将大大提高推荐的质量。为此使用联邦学习技术,一方面保证用户数据不被泄露,另一方面提升推荐质量。
3. 联邦矩阵分解
本节讨论跨公司联邦推荐问题。在该场景下,公司A以书籍为内容进行推荐,公司B以电影为内容进行推荐,根据协同过滤思想,具有相同观影爱好的用户会有相同的阅读爱好,如果能过在不泄露用户隐私的前提下,联合多方数据进行训练,将会明显提升推荐效果。
3.1 算法详解
公司A和B用户群体高度重合,但产品不同,适用于纵向联邦学习场景。在该场景下,多机构之间的推荐系统目标函数就变为下式:
m i n p , q ∑ ( i , j ) ∈ K A ( r i , j A − < p i , q j A > ) 2 + ∑ ( i , j ) ∈ K B ( r i , j B − < p i , q j B > ) 2 + λ ∥ p ∥ 2 2 + μ ( ∥ q A ∥ 2 2 + ∥ q B ∥ 2 2 ) min_{p,q}\sum_{(i,j)\in K_A}(r_{i,j}^A-
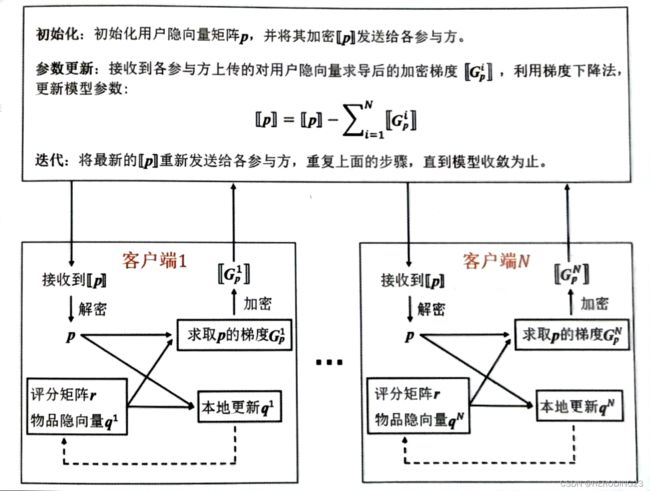
其中 r i , j A r_{i,j}^A ri,jA和 r i , j B r_{i,j}^B ri,jB表示A和B公司的原始评分矩阵,两家公司共享用户的隐向量信息。本算法的流程如下:
- 由可信第三方服务端初始化用户隐向量矩阵P,并使用公钥进行加密,同时,各家公司初始化物品隐向量矩阵。
- 服务端将加密的隐向量矩阵[[P]]分发给所有参与联合建模的公司。
- 各个参与方用私钥解密用户隐向量矩阵,利用梯度下降更新本地的物品隐向量矩阵。以公司A为例: ∂ L ∂ q j A = − 2 ∑ i p i ( r i , j A − < p i , q j A > ) + 2 μ q i A \frac{\partial L}{\partial q_j^A}=-2\sum_{i}p_i(r_{i,j}^A-
- 服务端受到加密后的用户隐向量梯度,在密文状态下更新矩阵p,如用户j对应的隐向量 p j p_j pj,更新公式如下所示: [ [ p j ] ] = [ [ p j ] ] − ∑ i = 1 N [ [ G p j i ] ] [[p_j]]=[[p_j]]-\sum_{i=1}^{N}[[G_{p_{j}}^i]] [[pj]]=[[pj]]−i=1∑N[[Gpji]]N代指参与联邦训练的客户方数量。
- 重复步骤2~4,直到算法收敛为止。
算法可视化步骤如下图所示:
3.2 详细实现
FATE完整的实现过程和细节在对应的GitHub目录中。实现的代码主要是两部分构成,协调方和参与方。它们共同继承基类HeteroFMBase,HeteroFMBase的构建如下所示:
from arch.api.utils import log_utils
from federatedml.framework.homo.procedure import aggregator
from federatedml.model_base import ModelBase
from federatedrec.param.matrix_factorization_param import HeteroMatrixParam
from federatedrec.transfer_variable.transfer_class.hetero_mf_transfer_variable import \
HeteroMFTransferVariable
LOGGER = log_utils.getLogger()
class HeteroMFBase(ModelBase):
"""
Hetero Matrix Factorization Base Class.
"""
def __init__(self):
super(HeteroMFBase, self).__init__()
self.model_param_name = 'MatrixModelParam'
self.model_meta_name = 'MatrixModelMeta'
self.model_param = HeteroMatrixParam()
self.aggregator = None
self.user_ids_sync = None
self.params = None
self.transfer_variable = None
self.aggregator_iter = None
self.max_iter = None
self.has_registered = False
def _iter_suffix(self):
return self.aggregator_iter,
def _init_model(self, params):
super(HeteroMFBase, self)._init_model(params)
self.params = params
self.transfer_variable = HeteroMFTransferVariable()
secure_aggregate = params.secure_aggregate
if not self.has_registered:
self.aggregator = aggregator.with_role(role=self.role,
transfer_variable=self.transfer_variable,
enable_secure_aggregate=secure_aggregate)
self.has_registered = True
self.max_iter = params.max_iter
self.aggregator_iter = 0
@staticmethod
def extract_ids(data_instances):
"""
Extract user ids and item ids from data instances.
:param data_instances: Dtable of input data.
:return: extracted user ids and item ids.
"""
user_ids = data_instances.map(lambda k, v: (v.features.get_data(0), None))
item_ids = data_instances.map(lambda k, v: (v.features.get_data(1), None))
return user_ids, item_ids
构建模型类: 构造函数如下,关键的成员变量包括用户的ID列表和物品的ID列表,隐向量维度,模型参数等。
import copy
import io
import tempfile
import typing
import zipfile
import numpy as np
import tensorflow as tf
from tensorflow.python.keras.backend import set_session
from tensorflow.python.keras.initializers import RandomNormal
from tensorflow.python.keras.layers import Dot, Embedding, Flatten, Input
from tensorflow.python.keras.models import Model
from tensorflow.python.keras.regularizers import l2
from federatedml.framework.weights import OrderDictWeights, Weights
from federatedrec.utils import zip_dir_as_bytes
class MFModel:
"""
Matrix Factorization Model Class.
"""
def __init__(self, user_ids=None, item_ids=None, embedding_dim=None):
if user_ids is not None:
self.user_num = len(user_ids)
if item_ids is not None:
self.item_num = len(item_ids)
self.embedding_dim = embedding_dim
self._sess = None
self._model = None
self._trainable_weights = None
self._aggregate_weights = None
self.user_ids = user_ids
self.item_ids = item_ids
模型的构建很简单,分别创建用户和物品的嵌入层,对其输出点积操作即可,如下:
def build(self, lambda_u=0.0001, lambda_v=0.0001, optimizer='rmsprop',
loss='mse', metrics='mse', initializer='uniform'):
"""
Init session and create model architecture.
:param lambda_u: lambda value of l2 norm for user embeddings.
:param lambda_v: lambda value of l2 norm for item embeddings.
:param optimizer: optimizer type.
:param loss: loss type.
:param metrics: evaluation metrics.
:param initializer: initializer of embedding
:return:
"""
# init session on first time ref
sess = self.session
# user embedding
user_input_layer = Input(shape=(1,), dtype='int32', name='user_input')
user_embedding_layer = Embedding(
input_dim=self.user_num,
output_dim=self.embedding_dim,
input_length=1,
name='user_embedding',
embeddings_regularizer=l2(lambda_u),
embeddings_initializer=initializer)(user_input_layer)
user_embedding_layer = Flatten(name='user_flatten')(user_embedding_layer)
# item embedding
item_input_layer = Input(shape=(1,), dtype='int32', name='item_input')
item_embedding_layer = Embedding(
input_dim=self.item_num,
output_dim=self.embedding_dim,
input_length=1,
name='item_embedding',
embeddings_regularizer=l2(lambda_v),
embeddings_initializer=initializer)(item_input_layer)
item_embedding_layer = Flatten(name='item_flatten')(item_embedding_layer)
# rating prediction
dot_layer = Dot(axes=-1,
name='dot_layer')([user_embedding_layer,
item_embedding_layer])
self._model = Model(
inputs=[user_input_layer, item_input_layer], outputs=[dot_layer])
# compile model
optimizer_instance = getattr(
tf.keras.optimizers, optimizer.optimizer)(**optimizer.kwargs)
losses = getattr(tf.keras.losses, loss)
self._model.compile(optimizer=optimizer_instance,
loss=losses, metrics=metrics)
# pick user_embedding for aggregating
self._trainable_weights = {v.name.split(
"/")[0]: v for v in self._model.trainable_weights}
self._aggregate_weights = {
"user_embedding": self._trainable_weights["user_embedding"]}
客户端模型训练: 在hetero_mf_client.py中实现,客户端本地训练执行下面三个关键步骤,保证物品隐向量q的更新。
- 梯度下降等优化算法,更新物品隐向量。同时计算出用户隐向量的梯度。
- 发送梯度信息给服务端进行聚合并且更新下发。
- 判断是否达到收敛条件,满足则退出,否则重复上述步骤。
def fit(self, data_instances, validate_data=None):
"""
Train matrix factorization on input data instances.
:param data_instances: training data
:param validate_data: validation data(Currently not used)
:return:
"""
LOGGER.debug("Start data count: {}".format(data_instances.count()))
# self._abnormal_detection(data_instances)
# self.init_schema(data_instances)
# validation_strategy = self.init_validation_strategy(data_instances, validate_data)
user_ids_table, item_ids_table = self.extract_ids(data_instances)
self.send_user_ids(user_ids_table)
received_user_ids = self.get_user_ids()
join_user_ids = user_ids_table.union(received_user_ids)
user_ids = sorted([_id for (_id, _) in join_user_ids.collect()])
LOGGER.debug(f"after join, get user ids {user_ids}")
item_ids = [_id for (_id, _) in item_ids_table.collect()]
# Convert data_inst to keras sequence data
data = self.data_converter.convert(
data_instances, user_ids, item_ids, batch_size=self.batch_size)
self._model = MFModel.build_model(
user_ids,
item_ids,
self.params.init_param.embed_dim,
self.loss,
self.optimizer,
self.metrics)
epoch_degree = float(len(data))
while self.aggregator_iter < self.max_iter:
LOGGER.info(f"start {self.aggregator_iter}_th aggregation")
# train
self._model.train(
data, aggregate_every_n_epoch=self.aggregate_every_n_epoch)
# send model for aggregate, then set aggregated model to local
modify_func: typing.Callable = functools.partial(
self.aggregator.aggregate_then_get,
degree=epoch_degree * self.aggregate_every_n_epoch,
suffix=self._iter_suffix())
self._model.modify(modify_func)
# calc loss and check convergence
if self._check_monitored_status(data, epoch_degree):
LOGGER.info(f"early stop at iter {self.aggregator_iter}")
break
LOGGER.info(
f"role {self.role} finish {self.aggregator_iter}_th aggregation")
self.aggregator_iter += 1
else:
LOGGER.warn(
f"reach max iter: {self.aggregator_iter}, not converged")
协调方: 接收各个客户端上传的用户隐特征向量梯度,进行用户隐向量的聚合更新,并将更新后结果分发给各个参与方。
def fit(self, data_inst):
"""
Aggregate model for host and guest, then broadcast back.
:param data_inst: input param is not used.
:return:
"""
while self.aggregator_iter < self.max_iter:
self.aggregator.aggregate_and_broadcast(suffix=self._iter_suffix())
if self._check_monitored_status():
LOGGER.info(f"early stop at iter {self.aggregator_iter}")
break
self.aggregator_iter += 1
else:
LOGGER.warn(
f"reach max iter: {self.aggregator_iter}, not converged")
4 联邦因子分解机
另一种联邦学习场景中,公司A是在线书籍销售商,公司B不销售商品但是有每个用户的画像数据,如果A获得了用户的画像信息,将可以更好销售书籍,本节引入联邦因子分解机算法,来解决这一场景的推荐问题。
4.1 算法详解
假设公司A有用户的反馈分数和部分特征信息,设为 ( X 1 , Y ) (X_1,Y) (X1,Y),而B拥有额外的特征数据,设为 X 2 X_2 X2,需要保证在两方的数据不出本地的前提下,帮助公司A提升推荐性能。对于两方的联合建模,其FM模型可以表示为:

损失函数可表示为:
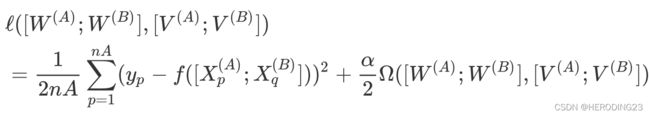
联邦因子分解机的详细算法流程,描述如下:
- 公司A和公司B各自初始化本地模型,A初始化参数 w i A w_i^A wiA和 v i A v_i^A viA,B初始化参数 w i B w_i^B wiB和 v i B v_i^B viB。
- 公司B将中间结果 w 0 B + ∑ j = 1 m w j B x j B w_0^B+\sum_{j=1}^{m}w_j^Bx_j^B w0B+∑j=1mwjBxjB和 v i B x i B v_i^Bx_i^B viBxiB加密,传输给A。
- 公司A接收到B传输的加密中间结果,计算加密残差 [ [ d ] ] = [ [ y ^ − y ] ] [[d]]=[[\hat y - y]] [[d]]=[[y^−y]],公司A将[[d]]和 v i A x i A v_i^Ax_i^A viAxiA发送回公司B。
- 公司A和公司B分别利用前面的推导公式,分别求解加密梯度 [ [ ∂ L ∂ w 0 A ] ] [[\frac{\partial L}{\partial w_0^A}]] [[∂w0A∂L]]、 [ [ ∂ L ∂ w 0 B ] ] [[\frac{\partial L}{\partial w_0^B}]] [[∂w0B∂L]]、 [ [ ∂ L ∂ w i A ] ] [[\frac{\partial L}{\partial w_i^A}]] [[∂wiA∂L]]、 [ [ ∂ L ∂ w i B ] ] [[\frac{\partial L}{\partial w_i^B}]] [[∂wiB∂L]]、 [ [ ∂ L ∂ v i , f A ] ] [[\frac{\partial L}{\partial v_{i,f}^A}]] [[∂vi,fA∂L]]、 [ [ ∂ L ∂ v i , f B ] ] [[\frac{\partial L}{\partial v_{i,f}^B}]] [[∂vi,fB∂L]]。
- 将这些加密参数梯度上传到第三方服务器解密,结果分别重新返回公司A和公司B,利用梯度下降更新参数。
- 重复步骤2~5,直到算法收敛。
4.2 详细实现
FATE完整的实现过程和细节在对应的GitHub目录中。实现的代码主要是三部分构成,协调方、guest方(带标签信息)、host方(无标签)。它们共同继承基类HeteroFMBase。
算法在实现的过程中会根据标签一方信息不同,区分为二项训练(0,1)和多类训练(1,2,3,4等具体分值),本节只针对二类训练。
def fit(self, data_instances=None, validate_data=None):
LOGGER.debug("Need one_vs_rest: {}".format(self.need_one_vs_rest))
classes = self.one_vs_rest_obj.get_data_classes(data_instances)
if len(classes) > 2:
self.need_one_vs_rest = True
self.in_one_vs_rest = True
self.one_vs_rest_fit(train_data=data_instances, validate_data=validate_data)
else:
self.need_one_vs_rest = False
self.fit_binary(data_instances, validate_data)
- guest方:即公司A,代码实现在
hetero_fm_guest.py中,主要功能是实现模型训练和预测。在模型训练部分,算法首先初始化公司A的参数,如下所示:
def fit_binary(self, data_instances, validate_data=None):
...
# intercept is initialized within FactorizationMachineWeights.
# Skip initializer's intercept part.
fit_intercept = False
if self.init_param_obj.fit_intercept:
fit_intercept = True
self.init_param_obj.fit_intercept = False
w_ = self.initializer.init_model(model_shape, init_params=self.init_param_obj)
embed_ = np.random.normal(scale=1 / np.sqrt(self.init_param_obj.embed_size),
size=(model_shape, self.init_param_obj.embed_size))
self.model_weights = \
FactorizationMachineWeights(w_, embed_, fit_intercept=fit_intercept)
...
模型训练过程中,先求取梯度信息,注意除了计算自身的加密参数梯度,还需要计算残差[[d]],对应下方代码块的fore_gradient,计算残差必须在guest方进行,因为残差需要标签信息,只有guest有标签。如下代码所示:
while self.n_iter_ < self.max_iter:
LOGGER.info("iter:{}".format(self.n_iter_))
batch_data_generator = self.batch_generator.generate_batch_data()
self.optimizer.set_iters(self.n_iter_)
batch_index = 0
for batch_data in batch_data_generator:
LOGGER.debug(f"MODEL_STEP In Batch {batch_index}, batch data count: {batch_data.count()}")
# Start gradient procedure
LOGGER.debug("iter: {}, before compute gradient, data count: {}".format(self.n_iter_,
batch_data.count()))
# optim_guest_gradient, fore_gradient, host_forwards = self.gradient_loss_operator. \
optim_guest_gradient, fore_gradient = self.gradient_loss_operator. \
compute_gradient_procedure(
batch_data,
self.encrypted_calculator,
self.model_weights,
self.optimizer,
self.n_iter_,
batch_index
)
最后利用梯度下降更新参数,如下所示:
loss_norm = self.optimizer.loss_norm(self.model_weights)
self.gradient_loss_operator.compute_loss(data_instances, self.n_iter_, batch_index, loss_norm)
# clip gradient
if self.model_param.clip_gradient and self.model_param.clip_gradient > 0:
optim_guest_gradient = np.maximum(optim_guest_gradient, -self.model_param.clip_gradient)
optim_guest_gradient = np.minimum(optim_guest_gradient, self.model_param.clip_gradient)
_model_weights = self.optimizer.update_model(self.model_weights, optim_guest_gradient)
self.model_weights.update(_model_weights)
batch_index += 1
- host方:对于公司B,没有标签信息,代码实现在
hetero_fm_host.py中,模型训练部分与guest一样,如下所示:
def fit_binary(self, data_instances, validate_data):
...
fit_intercept = False
if self.init_param_obj.fit_intercept:
fit_intercept = True
self.init_param_obj.fit_intercept = False
w_ = self.initializer.init_model(model_shape, init_params=self.init_param_obj)
embed_ = np.random.normal(scale=1 / np.sqrt(self.init_param_obj.embed_size),
size=(model_shape, self.init_param_obj.embed_size))
self.model_weights = \
FactorizationMachineWeights(w_, embed_, fit_intercept=fit_intercept)
...
在模型训练过程中,host方只需要计算其自身的加密参数梯度,其中需要的残差由guest求出并传递。
while self.n_iter_ < self.max_iter:
LOGGER.info("iter:" + str(self.n_iter_))
batch_data_generator = self.batch_generator.generate_batch_data()
batch_index = 0
self.optimizer.set_iters(self.n_iter_)
for batch_data in batch_data_generator:
LOGGER.debug(f"MODEL_STEP In Batch {batch_index}, batch data count: {batch_data.count()}")
optim_host_gradient = self.gradient_loss_operator.compute_gradient_procedure(
batch_data, self.model_weights, self.encrypted_calculator, self.optimizer, self.n_iter_,
batch_index)
LOGGER.debug('optim_host_gradient: {}'.format(optim_host_gradient))
self.gradient_loss_operator.compute_loss(self.model_weights, self.optimizer, self.n_iter_, batch_index)
# clip gradient
if self.model_param.clip_gradient and self.model_param.clip_gradient > 0:
optim_host_gradient = np.maximum(optim_host_gradient, -self.model_param.clip_gradient)
optim_host_gradient = np.minimum(optim_host_gradient, self.model_param.clip_gradient)
_model_weights = self.optimizer.update_model(self.model_weights, optim_host_gradient)
self.model_weights.update(_model_weights)
batch_index += 1
- 协调方:主要是对公司A和B的上传加密梯度进行解密,并将结果返回给各个参与方更新参数。
def fit_binary(self, data_instances=None, validate_data=None):
"""
Train FM model of role arbiter
Parameters
----------
data_instances: DTable of Instance, input data
"""
LOGGER.info("Enter hetero fm model arbiter fit")
self.cipher_operator = self.cipher.paillier_keygen(self.model_param.encrypt_param.key_length)
self.batch_generator.initialize_batch_generator()
validation_strategy = self.init_validation_strategy()
while self.n_iter_ < self.max_iter:
iter_loss = None
batch_data_generator = self.batch_generator.generate_batch_data()
total_gradient = None
self.optimizer.set_iters(self.n_iter_)
for batch_index in batch_data_generator:
# Compute and Transfer gradient info
gradient = self.gradient_loss_operator.compute_gradient_procedure(self.cipher_operator,
self.optimizer,
self.n_iter_,
batch_index)
if total_gradient is None:
total_gradient = gradient
else:
total_gradient = total_gradient + gradient
# training_info = {"iteration": self.n_iter_, "batch_index": batch_index}
# self.perform_subtasks(**training_info)
loss_list = self.gradient_loss_operator.compute_loss(self.cipher_operator, self.n_iter_, batch_index)
if len(loss_list) == 1:
if iter_loss is None:
iter_loss = loss_list[0]
else:
iter_loss += loss_list[0]
# if converge
if iter_loss is not None:
iter_loss /= self.batch_generator.batch_num
if not self.in_one_vs_rest:
self.callback_loss(self.n_iter_, iter_loss)
if self.model_param.early_stop == 'weight_diff':
weight_diff = fate_operator.norm(total_gradient)
LOGGER.info("iter: {}, weight_diff:{}, is_converged: {}".format(self.n_iter_,
weight_diff, self.is_converged))
if weight_diff < self.model_param.tol:
self.is_converged = True
else:
self.is_converged = self.converge_func.is_converge(iter_loss)
LOGGER.info("iter: {}, loss:{}, is_converged: {}".format(self.n_iter_, iter_loss, self.is_converged))
self.converge_procedure.sync_converge_info(self.is_converged, suffix=(self.n_iter_,))
validation_strategy.validate(self, self.n_iter_)
self.n_iter_ += 1
if self.is_converged:
break
5. 其他联邦推荐算法
在当前的FATE项目中,已经实现的联邦推荐算法列表包括:
- 基于纵向联邦的因子分解机算法
- 基于横向联邦的因子分解机算法
- 基于纵向联邦的矩阵分解算法
- 基于纵向联邦的奇异值分解算法
阅读总结
经过这一章的学习,我对联邦推荐算法有了深入的理解与认识,但是对于如何在FATE上运行章节中提到的案例,还是让我摸不着头脑。在GitHub上确实提供了完整的实现代码,但是感觉不用在FATE框架下也能运行(就是单纯的python代码),而我迫切想要了解的,是在FATE中如何运行联邦推荐算法,也许是我没能找到吧,如果有知道的朋友请在评论区call我,谢谢了!