【数据挖掘】数据挖掘笔记(一)开源数据集与数据采集
目录
-
- 1 开源数据集
-
- 1.1 部分开源数据集及介绍
- 1.2 数据搜索网站
- 2 网络爬虫
-
- 2.1 BeautifulSoup
-
- 2.1.1 举例部分代码
- 2.2 模拟浏览器登录
-
- 2.2.1 配置
- 2.2.2 举例部分代码
- 2.3 re 正则表达式
-
- 2.3.1 正则表达式
- 2.3.2 常用函数
- 2.4 Fiddle抓包
- 推荐
- 参考
1 开源数据集
1.1 部分开源数据集及介绍
1)GLUE:数据集具体介绍可参考博客
2)腾讯AI Lab开源大规模高质量中文词向量数据:数据下载地址
3)nltk_data:NLTK Corpora介绍
4)其它机器学习数据集及框架自带数据可参考博客ML - 数据集(Datasets)
1.2 数据搜索网站
图片来源斯坦福实用机器学习课程,进入该幻灯片点击即可进入相应链接

另外有需要,部分宏观数据可在国家统计局搜集
2 网络爬虫
2.1 BeautifulSoup
2.1.1 举例部分代码
1)
url = ''
request = urllib.request.Request(url,headers=header)
response = urllib.request.urlopen(request)
html = response.read()
soup = BeautifulSoup(html)
url_text = soup.select('div[class="air_con f-f0"] a') # 上下级用空格隔开
2)
html = urllib2.urlopen("https://en.wikipedia.org/wiki/" + articleUrl).read()
bsObj = BeautifulSoup(html)
Taps = bsObj.findAll("a",href=re.compile('^/wiki/((?!:).)*$'))
2.2 模拟浏览器登录
2.2.1 配置
下载对应Chrome Driver,版本号可在设置中找到

将ChromeDriver.exe放在Chrome的根目录,并将该目录添加到环境变量
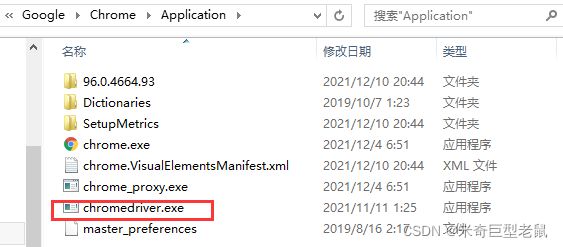
(注:看到以前的笔记有提到,也可以将下载下来的驱动放到python安装目录的lib目录中)
补充:
1)火狐浏览器驱动下载
2)opera浏览器驱动
2.2.2 举例部分代码
# 用的Xpath匹配
url = ''
driver = webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe')
driver.get(url)
def program(channel_text,TV_text):
result_ = pd.DataFrame()
while(1):
for i in range(7):
day = driver.find_element_by_xpath('//*[@id="weekday_' + str(i) + '"]')
date = day.text
day.click()
imfor = driver.find_element_by_xpath('//*[@id="liveepg"]').text
insert_data = pd.DataFrame([[channel_text,TV_text,date,imfor]],columns = ['channel','TV','date','detail'])
result_ = result_.append(insert_data,ignore_index = True)
try:
next_week = driver.find_element_by_xpath('//*[@id="upweek"]')
next_week.click()
except:
break
return result_
补充:
1)val_.click()这块有时候会报错,可替换为
driver.execute_script("arguments[0].click();", val_)
2)标签页关闭切换
# 以下代码参考来源[7]
allhandles = driver.window_handles # 获取所有页面的句柄,作为一个序列
driver.switch_to.window(allhandles[1]) # 通过序列的索引切换到第二个标签页
js = 'window.close()'
driver.execute_script(js) # 关闭当前标签页
driver.switch_to.window(allhandles[0]) # 切换回第一个标签页
3)不显示界面

2.3 re 正则表达式
2.3.1 正则表达式
各正则表达式对应(PS:很早保存的图片,不知道来源了,侵删)
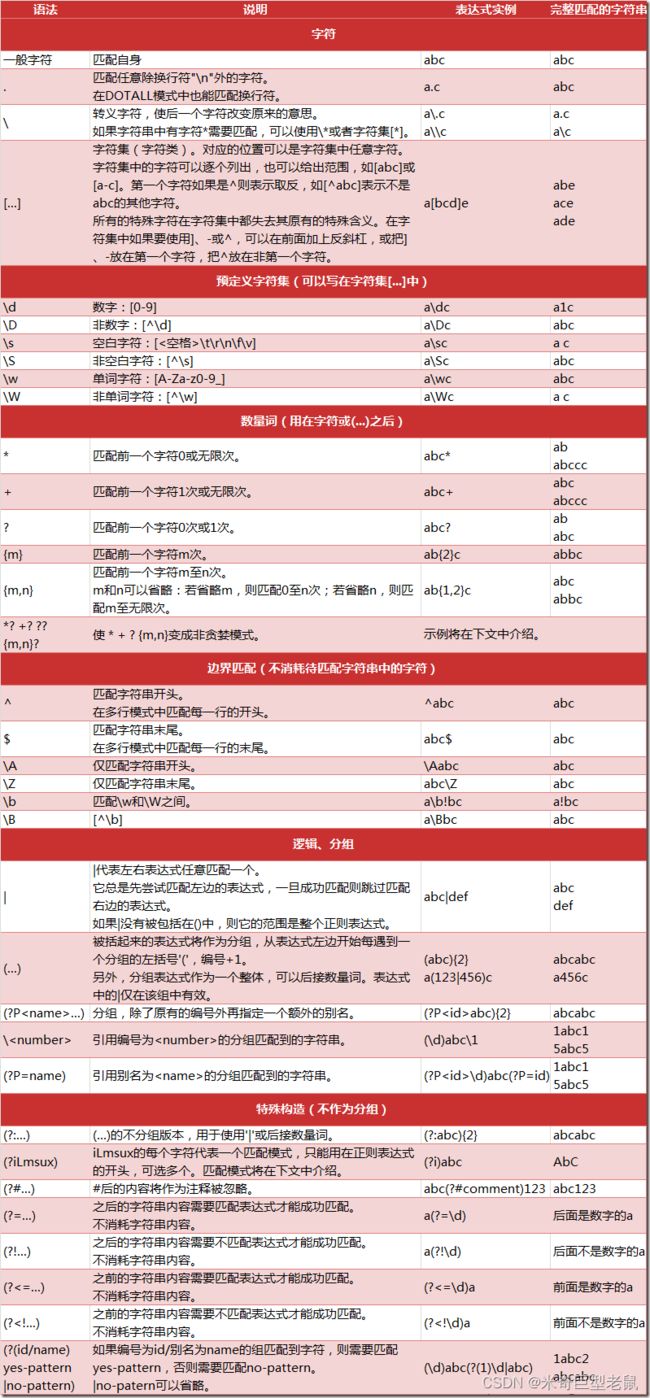
补充:
中文对应正则式:[\u4e00-\u9fa5]
2.3.2 常用函数
1)re.compile 相当于把正则式赋值到某个参数
regex = re.compile('[\u4e00-\u9fa5]')
2)re.sub 替换
ata['txt'][i] = re.sub(regex, '', data['txt'][i])
3)re.search
re.search('\.csv',f) # 前一个参数为正则式,后一个为变量
4)re.findall
def getUrl(html):
reg = r'(?:href|HREF)="?((?:http://)?.+?\.pdf)'
url_re = re.compile(reg)
url_lst = re.findall(url_re,html)
return url_lst
2.4 Fiddle抓包
(同早期存图,来源应该是中间水印,侵删)

推荐
可以看看up跟李沐学AI,这个老师专门给中国学生录了斯坦福课程的中文版,链接在参考[1]
参考
[1]跟李沐学AI
[2]炼数成金爬虫课
[3]GLUE
[4]斯坦福实用机器学习课程主页
[5]selenium 安装与 chromedriver安装
[6]Window 下配置ChromeDriver(简单4步完成)
[7]python实现关闭浏览器标签页
[8]selenium中ChromeOptions的headless(不显示页面的界面,即在后台运行)