数据增强实测之mixup
mixup是2018年发表在ICLR上的一种数据增强方法,核心思想是从每个batch中随机选择两张图像,并以一定比例混合生成新的图像。需要注意的是,全部训练过程都只采用混合的新图像训练,原始图像不参与训练过程。
mixup: Beyond Empirical Risk Minimization
paper: https://arxiv.org/pdf/1710.09412
code: https://github.com/facebookresearch/mixup-cifar10
mixup的图像混合生成方式比较简单,如下公式所示:
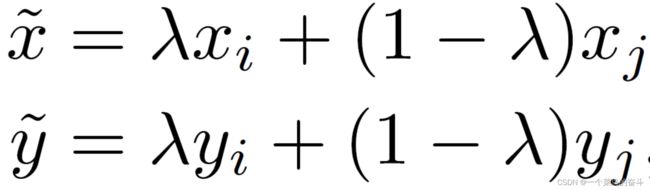
( ,
, )与(
)与( ,
,![]() )是同一个batch中随机选择的两个样本及对应标签,
)是同一个batch中随机选择的两个样本及对应标签, 为从beta分布中随机采样的数,
为从beta分布中随机采样的数,![]() 。随机生成的Python代码如下:
。随机生成的Python代码如下:
lam = numpy.random.beta(alpha, alpha)实现代码比较简单,如下:
alpha = 1.0 # 默认设置为1
criterion = nn.CrossEntropyLoss()
for (inputs, labels) in train_loader:
lam = np.random.beta(alpha, alpha)
index = torch.randperm(inputs.size(0))
images_a, images_b = inputs, inputs[index]
labels_a, labels_b = labels, labels[index]
mixed_images = lam * images_a + (1 - lam) * images_b
outputs = model(mixed_images)
_, preds = torch.max(outputs, 1)
loss = lam * criterion(outputs, labels_a) + (1 - lam) * criterion(outputs, labels_b)看看在图像上执行mixup是什么效果,代码如下:
import cv2
import numpy as np
img1 = cv2.imread('cat.png')
img1 = cv2.resize(img1, (224, 224))
img2 = cv2.imread('dog.png')
img2 = cv2.resize(img2, (224, 224))
alpha = 1.0
lam = np.random.beta(alpha, alpha)
mixed_img = lam * img1 + (1 - lam) * img2
cv2.imwrite('mixup.png', mixed_img)原图如下:

mixup随机生成两次,效果如下:


公平起见,训练时采用了和ResNet-50相同的配置,没有加大训练epochs,结果见下表。
| Method | CIFAR-10 | CIFAR-100 |
| ResNet-50 | 96.76/96.82/96.81/96.79 96.72/96.69/96.60/96.82 (96.75) |
83.80/83.66/84.19/83.26 83.89/83.90/83.57/83.69 (83.74) |
| ResNet-50+mixup | 96.56/96.61/96.35/96.49 96.67/96.56/96.31/96.39 (96.49) |
82.48/82.55/82.77/82.06 82.50/82.35/82.23/82.40 (82.42) |
从上表中的结果来看,在CIFAR10和CIFAR100两个数据集上使用mixup的效果都比较差,相比于ResNet-50无法提高识别精度。分析原因主要可能有两点:(1)mixup由于采用的都是合成图像训练,需要更多的epochs才能取得较好的效果;(2)论文中的baseline指标都比较低,因此看起来是有提升的,而这里的baseline是基于ImageNet预训练过的,这也是我们通常会用到的方式,因此相比之下这些增强方法的效果就很有限了。
采用作者提供的代码,在CIFAR10上基于mixup训练ResNet-50模型,测试精度为95.91。
数据增强实测之cutout_一个菜鸟的奋斗-CSDN博客
数据增强实测之Random Erasing_一个菜鸟的奋斗-CSDN博客
数据增强实测之RICAP_一个菜鸟的奋斗-CSDN博客
数据增强实测之GridMask_一个菜鸟的奋斗-CSDN博客
数据增强实测之Hide-and-Seek_一个菜鸟的奋斗-CSDN博客