python导出数据到excel文件_Python笔记:把数据导出到Excel文件上
相信初学Python数据分析的小伙伴都发现了,只是把数据加载在Python的环境中做数据处理还不够,因为环境的问题(Python加载进来的只是一张虚拟表,数据暂存内存中),我们最终还是需要把粗加工好的数据放在一些更具普遍性的载体(如:Excel、PPT、CSV、TXT等)中,以便向老板或领导、同事、投资人等传递相关的信息。这时,我们就需要从Python环境中把数据导出来。而通常,我们一般把结果导出到Excel(有.xlsx , .xls , .xlsm 等格式)中。我自己习惯把数据导入到.xlsx的Excel文件中(因为版本比较高)。下面我就以此为例。
# 把数据从Excel中加载到Python环境中
import pandas as pd
df = pd.read_excel(r"D:\Python\2020年3月份采购经营综合查询.xlsx",header = 2)
df

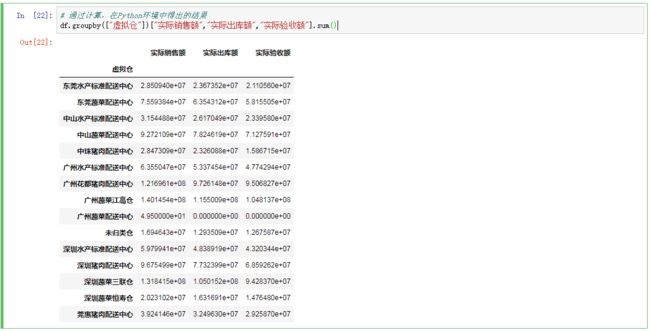
# 通过计算,在Python环境中得出的结果
df.groupby(["虚拟仓"])["实际销售额","实际出库额","实际验收额"].sum()
# 把结果导出到本机桌面上
df.groupby(["虚拟仓"])["实际销售额","实际出库额","实际验收额"].sum().to_excel(excel_writer = r"C:\Users\QDM\Desktop\导出结果.xlsx")
导出前桌面“空空如也”:
通过写指令,运行代码,欣喜地发现,电脑瞬间神奇地在桌面生成一个按照自己需求命名的Excel工作簿:
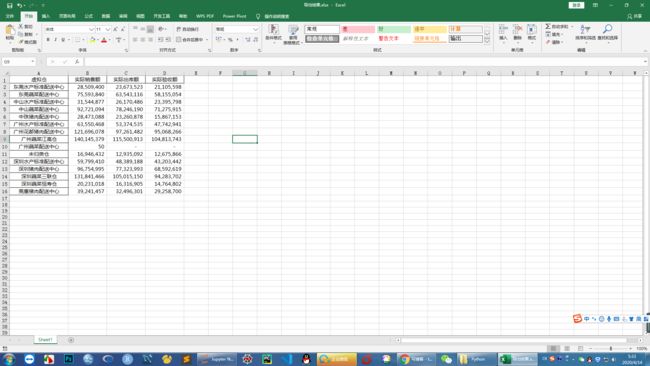
双击打开工作簿,发现里面就是我们刚才在Python中计算所得结果,但是格式一团糟,因为pandas不支持对格式的操作(起码就目前来说):

这时,我们可以通过手动框选,或用Ctrl+A快捷键全选文本内容,或点击下图所示——行号和列标相交的灰色倒小三角:
我习惯调为中文的“微软雅黑 11号”(Excel、PPT中皆如此),数值一般加个“千位符(,)”,位置为“右对齐”较好,以便能更直观地阅读对比
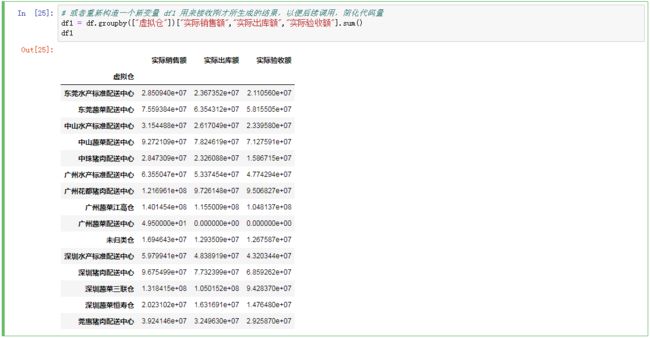
# 或者重新构造一个新变量 df1 用来接收刚才所生成的结果,以便后续调用,简化代码量
df1 = df.groupby(["虚拟仓"])["实际销售额","实际出库额","实际验收额"].sum()
df1
# 简化后的代码也可以得出相同结果
df1.to_excel(excel_writer = r"C:\Users\QDM\Desktop\导出结果1.xlsx")
但是,相信细心的人都注意到了,我们所导出的Excel表名称为默认的sheet1,这简直是逼死“强迫症”。所以,“强迫症”们可通过用sheet_name = "***"来给所输出的工作簿自定义工作表名称,示例如下:
# 给工作表命名为“业绩汇总”
df.groupby(["虚拟仓"])["实际销售额","实际出库额","实际验收额"].sum().to_excel(excel_writer = r"C:\Users\QDM\Desktop\导出结果.xlsx",sheet_name = "业绩汇总")
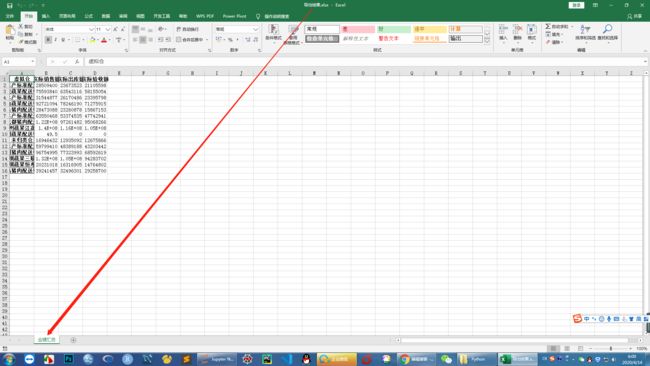
# 给工作表命名为“业绩汇总”---- 或者简化后的代码为:
df1.to_excel(excel_writer = r"C:\Users\QDM\Desktop\导出结果.xlsx",sheet_name = "业绩汇总")

值得注意的是:如果同一个名称与格式的文件已经在本地打开(处于打开状态),再次运行该代码就会报错。这时,我们应该先把该文件关闭之后再运行代码去导出新的结果。这类似于某个文件处于被占用(打开)状态,则不能成功地修改它的文件名。切记!