机器学习爬大树之决策树(ID3,C4.5)
自己自学机器学习的相关知识,过了一遍西瓜书后准备再刷一遍,后来在看别人打比赛的代码时多次用到XGBoost,lightGBM,遂痛下决心认真学习机器学习关于树的知识,自己学习的初步流程图为:
决策树(ID3,C4.5)---->CART----->Boost Tree---->Gradient Boosting Decision Tree(GBDT)----->XGBoost------>lightGBM
后面还会补上,Bagging,RF(Random Forest),那么机器学习中关于树的知识算是入门了!
一 决策树 (ID3算法基础)
决策树模型是是一种描述对实例进行分类 的树形结构。决策树由结点(node)和有向边(directed edge)组成。结点有两种类型:内部结点(internal node)和叶结点(leaf node)。内部结点表示一个特征或属性,叶结点表示一个类(即决策的结论)
下图是一个决策树的示例(注意我们仅用了两个feature就对数据集中的5个记录实现了准确的分类):

上图问题我们采用Headache特征作为根节点划分,那么当然我们也可以采用其他特征如:cough,temperatu等特征划分,所以我们要解决的问题是依据什么特征对数据集进行划分最为合理
信息熵:
熵:源于物理学中度量一个热力学系统的无序程度。而在信息学中,熵是对不确定的度量(即混乱程度的度量),1948年,香农引入了信息熵的概念
信息熵:为离散随机事件出现的概率。一个系统越有序,信息熵就越低;反之,一系统越是混乱,它的信息熵就越高。所以信息熵可以被认为是系统有序化的度量。
假设当前样本集合D中第k类样本所占的比例为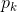 (k=1,2,3,...,N),则D的信息熵定义为:
(k=1,2,3,...,N),则D的信息熵定义为:
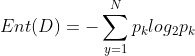
计算信息熵时约定:若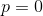 ,则
,则![]() ,显然当N=1时
,显然当N=1时![]() 最小;当
最小;当![]() ,
,![]() ,因为信息熵是衡量一系统不确定(本人喜欢用混乱这个词)程度,显然
,因为信息熵是衡量一系统不确定(本人喜欢用混乱这个词)程度,显然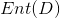 越大,这当前集合
越大,这当前集合 的混乱程度越高!
的混乱程度越高!
具体计算来看下面的一个简单的例子,以二分类为例(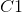 表示第一类,
表示第一类,![]() 表示第二类):
表示第二类):

现在我们需要一个定量来找到最佳的划分点
信息增益(information gain) :
假设离散特征 (如上面的例子中的Headache)有
(如上面的例子中的Headache)有 个可能的属性取值
个可能的属性取值![]() ,(如特征headache的severe,no,mild),若使用离散特征来对样本集合进行划分,则会产生个分支结点,其中第
,(如特征headache的severe,no,mild),若使用离散特征来对样本集合进行划分,则会产生个分支结点,其中第 个分支结点包含了集合中所用在特征中属性为
个分支结点包含了集合中所用在特征中属性为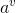 的样本,记为
的样本,记为 ,而
,而![]() 即属性为的样本个数,我们可以根据信息熵公式算出的信息熵
即属性为的样本个数,我们可以根据信息熵公式算出的信息熵 ,再考虑到不同的分支结点所包含的样本数不同,给分支结点赋予权重
,再考虑到不同的分支结点所包含的样本数不同,给分支结点赋予权重![]() ,即样本数越多的分支结点的影响越大,于是便可计算出用特征对样本集进行划分所获得的“信息增益(information gain)”:
,即样本数越多的分支结点的影响越大,于是便可计算出用特征对样本集进行划分所获得的“信息增益(information gain)”:

现在我们用上面的例子依次计算下分别取特征(headache,Cough,Temperature,Sore)的信息增益就一目了然:
首先要先计算:显然,这是一个二分类问题,我们要根据特征来诊断病人是Flu,还是Cold两类,所以公式中的![]() ,当前样本中的样本个数为
,当前样本中的样本个数为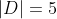 ;
;
分类为Flu的样本个数为![]() (即病人编号为p1,p3,p5),则
(即病人编号为p1,p3,p5),则![]()
分类为cold的样本个数为![]() (即病人编号为p2,p4);则
(即病人编号为p2,p4);则![]()
故

(1) 计算特征值为Headache的信息增益![]()
1:特征headache的属性值分别为severe,no,mild:
则 ![]()

![]()
![]()
![]()
![]()
2:分别计算![]() :
:
i):![]() =
=![]() 两个样本,所以:
两个样本,所以:
![]()
ii):![]() =
=![]() 一个样本,所以:
一个样本,所以:
![]()
Iii):![]() =
=![]() 两个样本,所以:
两个样本,所以:
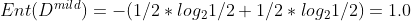
3.计算headache的信息增益(将上面的值依次带入公式)
![]() =
= ![]()
(2) 分别计算特征值为Cough,Temperature,Sore信息增益![]() ,
,![]()
![]()
与上面的求Headache的步骤一样,在这里不在详细写出
![]() =
=![]()
![]() =
=![]()
![]() =
=![]()
(3)比较每个特征的信息增益,选取最大的特征进行划分(在这里Headache与Cough信息增益相同,我们选取Headache划分),之后再对每一个划分后的子集进行相同的步骤(已用的特征将不再以后的划分中使用),一般情况下叶子节点的生成满足以下步骤:
i):当前结点包含的样本全属于同一类别,将不再划分并作为叶子结点,其类别标签为样本的类别
ii):当前属性集为空,或是所有样本在所有属性上取值相同,将不再划分并作为叶子结点,其类别标签为该结点所含样本最多的类别
iii):当前结点包含的样本集合为空,不能划分并将该结点作为叶子结点,但将其类别设定为其父结点所含样本最多的类别
(我的理解是:以上例子来说,我们假设先取Headache划分,则severe中的样本 为(p1,p5),然后在子集(p1,p5)中,我们假设用Sore的特征划分这个子集,那么在Sore中属性值为no的样本是没有的,这个时候就用它的父结点的样本最多的类别来做该叶结点(空集)的类别)
实际上,信息增益准则对可取值数目较多的属性有所偏好,为减小这种偏好可能带来的不利影响,下面介绍著名的C4.5算法
二 C4.5算法
C4.5算法采用增益率(Gain ratio)来选择最优划分特征,我们来看看增益率的计算公式:
![]()
其中:
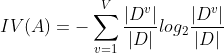
称为特征A的固有值(intrinsic value),特征A的可能取值数目越多(即越大),则![]() 的值通常会越大,需要注意的是,增益率准则对可取值数目较少的特征有所偏好,因此,C4.5算法并不是直接选择增益率最大的候选划分特征,而是使用了一个启发式:先从候选划分属性中找出一个信心增益高于平均水平的特征,再从中选择增益率最高的。
的值通常会越大,需要注意的是,增益率准则对可取值数目较少的特征有所偏好,因此,C4.5算法并不是直接选择增益率最大的候选划分特征,而是使用了一个启发式:先从候选划分属性中找出一个信心增益高于平均水平的特征,再从中选择增益率最高的。
连续与缺失值处理:
一 连续值处理:到目前为止我们都是用离散特征来生成决策树,但现实学习中有很多连续特征,因为连续特征的可取数目不再有限,因此,不能直接根据连续特征的可取值来对结点进行划分,在这里,我们采用的策略是二分法(bi-partition)对连续特征进行处理。
给定样本集和连续特征 ,假定在上有
,假定在上有 个不同的取值,其中第个取值记为
个不同的取值,其中第个取值记为 :
:
1:将这些值从小到大进行排序,记为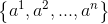 ;
;
2:基于划分点 可将样本集分为子集
可将样本集分为子集 和
和![]() ,其中包含那些在特征上取值不大于的样本,
,其中包含那些在特征上取值不大于的样本,![]() 表示其样本个数;而
表示其样本个数;而![]() 则包含那些在特征上取值大于的样本,
则包含那些在特征上取值大于的样本,![]() 则表示取值大于的样本个数;
则表示取值大于的样本个数;
3:把区间![]() 的中位点
的中位点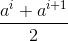 作为候选划分点。因此,对连续特征,我们可考察包含
作为候选划分点。因此,对连续特征,我们可考察包含 个元素的候选划分点集合
个元素的候选划分点集合
![]()
4:然后我们可以像离散属性值一样来考察这些划分点,选取最优的划分点进行样本集合的划分,则属性的信息增益公式为:
![]()

其中![]() 是样本集基于划分点二分后的信息增益,于是,我们就可选择使
是样本集基于划分点二分后的信息增益,于是,我们就可选择使![]() 最大化的划分点
最大化的划分点
具体计算参考下面的一个例子即一目了然:假设我们有6个样本,其一个特征 为连续特征,现计算其特征的信息增益,具体步骤与例子如下:
为连续特征,现计算其特征的信息增益,具体步骤与例子如下:
| 编号 | 1 | 2 | 3 | 4 | 5 | 6 |
|
0.5 | 0.4 | 0.1 | 0.6 | 0.3 | 0.2 |
 |
0 | 0 | 1 | 0 | 1 | 0 |
i):对连续特征从下到大进行排序:
| 编号 | 3 | 6 | 5 | 2 | 1 | 4 |
|
0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 |
|
1 |
0 | 1 | 0 | 0 | 0 |
ii):候选划分点集合:
| 划分点 | 0.15 | 0.25 | 0.35 | 0.45 | 0.55 |
iii):计算每个划分点对应的![]() :
:
先计算出 
![]()
1:取划分点![]() 0.15
0.15
则=![]() ,
,![]() =
=![]() ;
;
![]() ;
; ![]()
![]()
![]()
![]()
2:取划分点![]() 0.25
0.25
则=![]() ,
,![]() =
=![]() ;
;
![]() ;
; ![]()
![]()
![]()
![]()
3:取划分点![]() 0.35
0.35
则=![]() ,
,![]() =
=![]() ;
;
![]() ;
; ![]()
![]()
![]()
![]()
4:取划分点![]() 0.45
0.45
则=![]() ,
,![]() =
=![]() ;
;
![]() ;
; ![]()
![]()
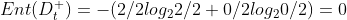
![]()
5:取划分点![]() 0.55
0.55
则=![]() ,
,![]() =
=![]() ;
;
![]() ;
; ![]()
![]()
![]()
![]()
iV):比较每个划分点对应的![]() ,取最大的作为划分点:
,取最大的作为划分点:
显然 ![]() 0.35时
0.35时![]() 最大,故取其作为该连续特征的划分点。
最大,故取其作为该连续特征的划分点。
须知,与离散特征不同,若当前结点划分特征为连续特征,那么该特征还可作为其后代结点的划分特征!
注意:其实连续值得处理有一个最优化的方法,不需要逐个计算每个划分点的![]() ,仅考虑位于具有不同类标号的两个相邻记录之间的候选划分点,最佳划分点一定是在这些候选划分点中的一个,例如上面的不同类别划分点有
,仅考虑位于具有不同类标号的两个相邻记录之间的候选划分点,最佳划分点一定是在这些候选划分点中的一个,例如上面的不同类别划分点有![]() 这3个,因此大大简化了计算;这是因为信息增益的目的是找出一个划分点能最好的划分将相同的类别放在一起,将不同的类别分开,所以若一个划分点左边与右边的样本类别相同,但我们将他们分开,显然是不合理的,所以我们仅需考虑位于不同类别标签之间的候选划分点即可!!!
这3个,因此大大简化了计算;这是因为信息增益的目的是找出一个划分点能最好的划分将相同的类别放在一起,将不同的类别分开,所以若一个划分点左边与右边的样本类别相同,但我们将他们分开,显然是不合理的,所以我们仅需考虑位于不同类别标签之间的候选划分点即可!!!
二 缺失值处理:现实任务中常会遇到不完整的样本,即样本某些特征值缺失。如果简单地放弃不完整样本,仅使用无缺失值的样本进行学习,显然是对数据信息极大的浪费,下表是我们以前使用的例子,但一些特征的特征值已经缺失,如果放弃不完整的样本,则仅有一个样本可为我们所用!

所以,我们需要解决两个问题 :
(1): 如何在特征值缺失的情况下进行划分特征选择;
(2): 给定划分特征,若样本在该特征上的值缺失,如何对样本进行划分?
对缺失值得处理的核心想法是为每个特征都附加一个权重![]() ,每一个样本都附加一个权重
,每一个样本都附加一个权重 ,在决策树学习开始阶段,根结点中各样本的权重初始化为1
,在决策树学习开始阶段,根结点中各样本的权重初始化为1
接下来 我们看看如何在特征值缺失的情况下进行划分特征选择。
(1)特征值缺失的情况下进行划分特征选择
给定训练集和特征,令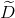 表示中特征上没有缺失值得样本集合,显然我们可以仅根据来判断用特征划分时的信息增益;假设特征有个可取值
表示中特征上没有缺失值得样本集合,显然我们可以仅根据来判断用特征划分时的信息增益;假设特征有个可取值![]() ,令
,令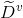 表示中特征上取值为样本子集;
表示中特征上取值为样本子集;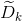 表示中属于第
表示中属于第 类(
类(![]() )的 样本子集,现假设我们为每个样本赋予一个权重,直观地看,对特征来说,定义以下3个占比:
)的 样本子集,现假设我们为每个样本赋予一个权重,直观地看,对特征来说,定义以下3个占比:
![]() (
( 表示无缺失值样本占训练集的比例,即前面提到的特征的权重
表示无缺失值样本占训练集的比例,即前面提到的特征的权重![]() ,算信息增益用)
,算信息增益用)
![]() (
(![]() 表示无缺失值样本中第类样本的权重之和与无缺失值样本的权重之和的比例,算信息熵用)
表示无缺失值样本中第类样本的权重之和与无缺失值样本的权重之和的比例,算信息熵用)
![]() (
(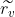 表示无缺失值样本中特征值为的样本权重之和与无缺失值样本的权重之和的比例,算信息增益用)
表示无缺失值样本中特征值为的样本权重之和与无缺失值样本的权重之和的比例,算信息增益用)
基于上述定义,我们可将信息增益的计算式推广为如下公式(注意上面几个参数的用处):
![]()
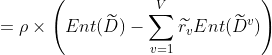 ,
,
其中:
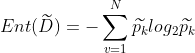
直接看上面的公式有些晦涩难懂,其实跟前面学的信息增益相差无几,我们就简单的以上面的例子计算一下:我们想算出特征为Headache的信息增益,其他的类似
训练集=![]() ; =
; =![]() ;
;  =
=![]() ;
; ![]() =
=![]() ; 同样
; 同样![]() ; 为每个样本赋予权重=1;
; 为每个样本赋予权重=1;
接下来我们开始一个一个的根据公式算出参数:
![]() (不是样本个数比,是权重之和的比值)
(不是样本个数比,是权重之和的比值)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
万事俱备只欠带公式啦:
![]()
![]()
基于以上步骤,用无缺失值得样本集分别计算出各个特征的信息增益,就很好的回答了问题(1)如何在特征值缺失的情况下进行划分特征选择!
(2)特征值缺失的情况下进行划分特征选择
对问题(2),若样本 在划分特征上的取值已知,则将划入与其取值对应的子结点上,且样本权值在子结点中保持为
在划分特征上的取值已知,则将划入与其取值对应的子结点上,且样本权值在子结点中保持为![]() ;若样本在划分特征上取值未知,则将同时划入所有子结点,且样本权值在与特征值
;若样本在划分特征上取值未知,则将同时划入所有子结点,且样本权值在与特征值![]() 对应的子结点中调整为
对应的子结点中调整为![]() ;
;
其实,就是让同一个样本以不同的概率划入到不同的子结点中去,还是通过例子来简单的 讲讲吧!
假如我们算的Headache的信息增益最大,对其划分有:
![]() =
=![]() ;
; ![]() ;
; ![]() ;
;
但![]() 这个样本因为在特征Headache上的值是缺失的,且此时
这个样本因为在特征Headache上的值是缺失的,且此时![]() ,将
,将![]() 同时划入所有的子结点上
同时划入所有的子结点上
![]() =
=![]() 其中
其中![]()
![]() 其中
其中![]()
![]() 其中
其中![]()
然后在进行下一轮的划分!
这是我的第一篇文章,一方面做为自己的学习笔记;另一方面希望对新学习的小伙伴们提供一些帮助!望共勉,后续文章我也会尽快更新!!有不足之处希望小伙伴们多多指教!!
参考资料:
李航《统计学习方法》
周志华《机器学习》
https://blog.csdn.net/baimafujinji/article/details/51724371