Python 数据合并及查询方法——Pandas merge()
本文目录
- merge() 官方地址
- merge() 主体部分及其参数说明
- 不同的连接示意图
-
- 内连接 inner join
- 全连接 Outer Join
- 左连接 left join
- 右链接
- 半连接 semi join
- 反连接 anti join
- 例子解释
- Reference
merge() 官方地址
这一节主要讲的是 merge() methods。
这都是官方文档的链接,https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.merge.html
(大家可以自行翻译理解,官方也给了案例。)
merge() 主体部分及其参数说明
首先,我们看看merge()的主体组成
pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False,
sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
下面是官方的解释,直接翻译,有一些个人注释
-
Parameters 参数解释
left : DataFrame
right : DataFrame or named Series,两个表只有right才会是要合并的对象,而left是等待合并的,即右表和左表合并
how : {‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’}, default ‘inner’
left:仅使用左帧中的键,类似于 SQL 左外连接;保留密钥顺序。 right:仅使用右框架中的键,类似于 SQL 右外连接;保留密钥顺序。 outer:使用来自两个帧的键并集,类似于 SQL 完全外部联接;按字典顺序对键进行排序。 inner:使用来自两个帧的键的交集,类似于 SQL 内部连接;保留左键的顺序。 cross:从两个帧创建笛卡尔积,保留左键的顺序。#上面是翻译的结果,就是和sql的连接一样。默认是取两个表的交集,并且保持left中的顺序
on :label or list
要加入的列或索引级别名称。这些必须在两个 DataFrame 中都可以找到。如果 on 是 None 并且不合并索引,则默认为两个 DataFrame 中列的交集。
suffixes:如果有相同的列,我们可以自定义名称加以区分
left_on 和right_on:这两个需要一起使用的!这仅在左表和右表的列名称不同时使用,且二者的长度需要相同,如果不同会报错。
left_index和right_index: 这两个是个布林值。默认为False,当选为True的时候,说明我们需要合并索引。如果你要保留的是left_on的值,作索引,那就为True;right_on做索引,同样如此。
(剩下的可以看看文档链接,就不一一说明了)
值得注意的是
merge() 默认是内连接 inner join!!!!
不同的连接示意图
这一部分就是每个连接到解释,以及他们是怎么合并筛选的
内连接 inner join

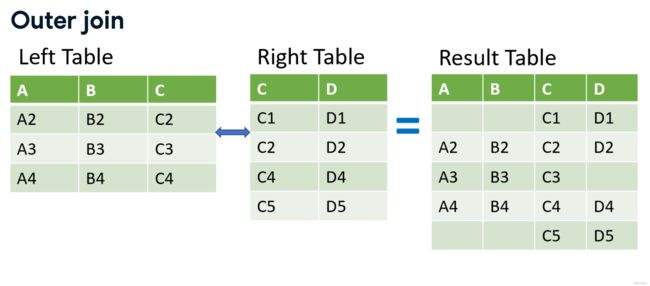
全连接 Outer Join

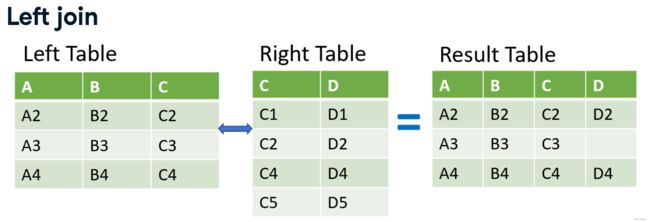
左连接 left join

右链接


半连接 semi join

返回左表中和右表想匹配的行;上图右表有C2,C3,所以返回了左表的第一行和第三行。
与内连接不同的是,它只会显示与左表匹配的column
反连接 anti join
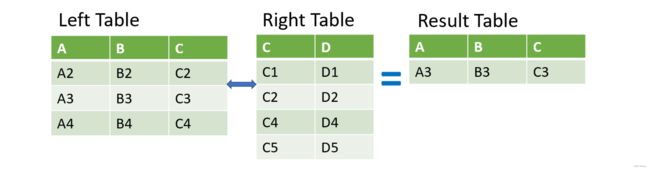
返回左表里没有的行;右表没有C3,所以直接返回了左表的第二行
例子解释
我把网站上的实例复制了下来,可以结合一下。
您的目标是
找出在 7 月(月 == 7)的工作日(day_type == ‘Weekday’)乘坐芝加哥公共交通系统时通过威尔逊车站 (station_name == ‘Wilson’) 的乘客提供的乘车总数.幸运的是,芝加哥提供了这些详细数据,但它位于三个不同的表格中。您将努力将这些表合并在一起以回答问题。
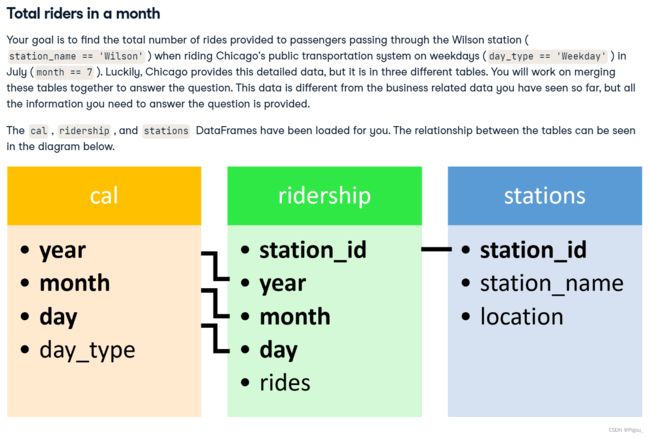



上面是几个表的示例。
首先,将 Ridership 和 cal 表合并在一起,从左侧的 Ridership 表开始,并将结果保存到变量 ridership_cal
ridership_cal = ridership.merge(cal, on = ['year', 'month', 'day'])
然后,通过合并 station表将先前的合并扩展到三个表。
ridership_cal_stations = ridership.merge(cal, on=['year','month','day']) \
.merge(stations, on = 'station_id')

最后,创建一个名为 filter_criteria 的变量以从合并表中选择适当的行,以便可以对 ‘rides游乐设施列’ 求和。
# Merge the ridership, cal, and stations tables
ridership_cal_stations = ridership.merge(cal, on=['year','month','day']) \
.merge(stations, on='station_id')
# Create a filter to filter ridership_cal_stations
filter_criteria = ((ridership_cal_stations['month'] == 7)
& (ridership_cal_stations['day_type'] == 'Weekday')
& (ridership_cal_stations['station_name'] == 'Wilson'))
# Use .loc and the filter to select for rides
print(ridership_cal_stations.loc[filter_criteria, 'rides'].sum())
# result
140005
上面就是先按要求的列进行合并,这样就能将所有的表连接在一起,最后再按条件进行筛选。
有不懂得欢迎提问哈
Reference
Datacamp