研究生周报(第七周)
研究生周报(第七周)
学习目标
- 吴恩达深度学习课程
- 正则化
- 梯度检验
- 归一化处理
- 多种梯度下降算法
学习时间
6.19~6.25
学习产出
- Python代码
- github记录
正则化
-
L2正则化
用于避免过拟合
- m i n w , b J ( w , b ) min_{w,b}J(w,b) minw,bJ(w,b)(L2正则化)
- J ( w , b ) = 1 m ∑ i = 1 m ( y i ^ , y i ) + λ 2 m ∣ ∣ w ∣ ∣ 2 2 + λ 2 m b 2 J(w,b)=\frac{1}{m}\sum_{i=1}^m(\hat{y^i},y^i)+\frac{\lambda}{2m}||w||_2^2+\frac{\lambda}{2m}b^2 J(w,b)=m1∑i=1m(yi^,yi)+2mλ∣∣w∣∣22+2mλb2
- 因为w包含许多参数,而b只是其中一个参数,故可以省略
- L1正则化使用的比较少
-
dropout(随机失活)
- dropout是值在深度学习网络的训练过程中,按照一定的概率将一部分神经网络单元暂时从网络中丢弃,相当于从原始的网络中找到一个更瘦的网络
-
数据扩增
- 图片可以进行翻转、放大等方法提供更多的素材
-
早终止法
- 当模型在验证集上的表现开始下降的时候停止训练
- 主要步骤
- 将原始的训练数据集划分为训练集和验证集
- 只在训练集上进行训练,并每隔一个周期计算模型在验证集上的误差
- 当模型在验证集上(权重的更新低于某个阙值;预测的错误率低于某个阙值;达到一定的迭代词数),则停止训练
- 使用上一次迭代的参数作为模型的最终参数
归一化输入
- 零均值化
- μ = 1 m ∑ 1 m x i \mu=\frac{1}{m}\sum_1^mx_i μ=m1∑1mxi
- m i = m i − μ m_i=m_i-\mu mi=mi−μ
- 归一化方差
- σ 2 = 1 m ∑ 1 m x i 2 \sigma^2=\frac{1}{m}\sum_1^mx_i^2 σ2=m1∑1mxi2
- m i = m i σ 2 m_i=\frac{m_i}{\sigma^2} mi=σ2mi
- 为什么要进行归一化操作(变量的范围过大)
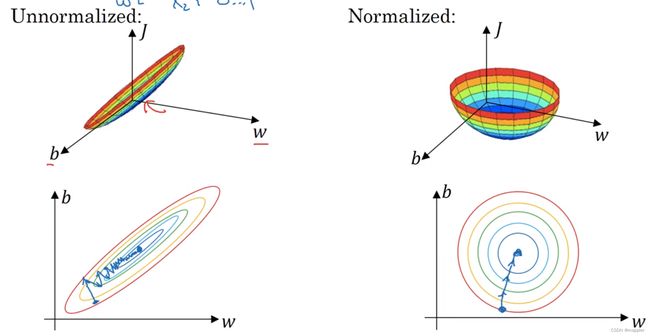
梯度消失与梯度爆炸
- 梯度消失:在神经网络中,当前面隐藏层的学习速率低于后面隐藏层的学习速率,即随着隐藏层数目的增加,分类准确率反而下降了。这种现象叫梯度消失
- 隐藏层的层数过多
- 采用了不合适的激活函数
- 梯度爆炸:在神经网络中,当前面隐藏层的学习速率低于后面隐藏层的学习速率,即随着隐藏层数目的增加,分类准确率反而下降了。这种现象叫梯度爆炸。
- 隐藏层的层数过多
- 权重的初始化值过大
- 初始化参数
- 全零初始化:在线性回归,logistics回归中可行,在神经网络中不行
- 随机初始化:随机分布选择不当将会导致网络优化陷入困境
- Xavier初始化:保持输入和输出的方差一致(服从相同的分布),就避免了所有输出值都趋向于0
- 根据输入和输出神经元的数量自动决定初始化的范围:定义参数所在的层的输入维度为m,输出维度为n,那么参数将从 ( − 6 m + n , 6 m + n ) (-\sqrt{\frac{6}{m+n}},\sqrt{\frac{6}{m+n}}) (−m+n6,m+n6)
- He initialization
- 在ReLU网络中,假定每一层都有一半的神经元被激活,另一半为0,所以要保持variance不变,只需要在Xavier的基础上再除以2
- Batch Normalization Layer
- pre-training
- pre-training阶段:将神经网络中的每一层取出,构造一个auto-encoder做训练,使得输入层和输出层保持一致。在这一过程中,参数得以更新,形成初始值。
- fine-tuning阶段:将pre-train过的每一层放回神经网络,利用pre-train阶段得到的参数初始值和训练数据对模型进行整体调整。在这一过程中,参数进一步被更新,形成最终模型。
梯度检验
- 梯度检验是一种对求导结果进行数值检验的方法,该方法可以验证求导代码是否正确
- 数学原理
- 最小化以 θ \theta θ为自边量的目标函数 J ( θ ) J(\theta) J(θ),梯度更新公式为: θ : = θ − α d d θ J ( θ ) \theta:=\theta-\alpha\frac{d}{d\theta}J(\theta) θ:=θ−αdθdJ(θ)
- 以sigmoid函数为例, f ( z ) = 1 1 + e x p ( − z ) f(z)=\frac{1}{1+exp(-z)} f(z)=1+exp(−z)1,其导数形式为: f ′ ( z ) = g ( z ) = f ( z ) ( 1 − f ( z ) ) f^{'}(z)=g(z)=f(z)(1-f(z)) f′(z)=g(z)=f(z)(1−f(z))
- 导数的数学定义: d d θ J = l i m ε → 0 J ( θ + ε ) − J ( θ − ε ) 2 ε \frac{d}{d\theta}J=lim_{\varepsilon\rightarrow 0}\frac{J(\theta+\varepsilon)-J(\theta-\varepsilon)}{2\varepsilon} dθdJ=limε→02εJ(θ+ε)−J(θ−ε)
- 深度学习的优化算法,差不多就是梯度下降,每次的参数更新有两种方式
- 批梯度下降:遍历全部数据集算一个损失函数,然后算函数对各个参数的梯度,更新梯度。这种方法没更新一次参数都要把数据集的所以样本看一遍,计算开销大
- 随机梯度下降:每看一个数据就算一次损失函数,然后求梯度更新参数,速度快但是收敛性能不太好
- 折中手段(mini-batch):小批的梯度下降
- mini-batch实现步骤
- 确定mini-batch size,一般有32、64、128等,按照自己的数据集而定,确定mini-batch_num=m/mini-batch_num+1
- 在分组之前将原数据集顺序打乱,随机打乱
- 分组,将打乱后的数据集分组
- 将分好的mini-batch组放入迭代循环中,每次循环都做mini-batch_num次梯度下降
- batch_size选取原则
- m<2000时,batch_size=m,即采用batch梯度下降法
- m>2000时,batch_size=64,128,256,512,使用mini-batch梯度下降法
指数加权平均
- 公式: v t = β × v t − 1 + ( 1 − β ) × θ ( t ) v_t=\beta\times v_{t-1} + (1-\beta)\times \theta(t) vt=β×vt−1+(1−β)×θ(t)
- 偏差修正: v t 1 − β t \frac{v_t}{1-\beta^t} 1−βtvt
动量梯度下降法
-
动量梯度下降算法对比梯度下降算法直观体现:数值方向波动变小了,而在水平方向下降速度变快了
-
实现代码
def sgd_momentum(parameters, vs, lr, gamma): for param, v in zip(parameters, vs): v[:] = gamma * v + lr * param.grad.data param.data = param.data - v
RMSPrp算法
- Momentum优化算法使得模型可以更加快的朝着最优化方向更新,且效果不错,但存在参数更新波动过大问题
- 为保证模型加快收敛速度的同时保持参数波动平稳,对权重与偏置的梯度使用微分平方加权平均数:
- S d W = β S d W + ( 1 + β ) d W 2 S_{dW}=\beta S_{dW}+(1+\beta)dW^2 SdW=βSdW+(1+β)dW2
- S d b = β S d W + ( 1 + β ) d b 2 S_{db}=\beta S_{dW}+(1+\beta)db^2 Sdb=βSdW+(1+β)db2
- W = W − α d W S d W + ϵ , b = b − α d b S d b + ϵ W=W-\alpha\frac{dW}{\sqrt{S_{dW}+\epsilon}}, b=b-\alpha\frac{db}{\sqrt{S_{db}+\epsilon}} W=W−αSdW+ϵdW,b=b−αSdb+ϵdb
梯度下降算法比较
- Batch Gradient Descent(BGD)
- BGD采用整个训练集的数据来计算cost function对参数的梯度: θ = θ − η ⋅ ∇ θ J ( θ ) \theta=\theta-\eta\cdot\nabla_{\theta}J(\theta) θ=θ−η⋅∇θJ(θ)
- Stochastic Gradient Descent(SGD)
- SGD一次只进行一次更新,没有荣与,比较快,并且可以新增样本: θ = θ − η ⋅ ∇ θ J ( θ ; x ( i ) ; y ( i ) ) \theta=\theta-\eta\cdot\nabla_{\theta}J(\theta;x^{(i)};y^{(i)}) θ=θ−η⋅∇θJ(θ;x(i);y(i))
- SGD的噪音比BGD多,并且迭代不是每次都向着整体最优化方向。所以虽然训练速度快,但是准确率下降,并不是全局最优。
- Mini-Batch Gradient Descent(MBGD)
- MBGD每一次利用一小批样本,即n个样本进行计算,这样它可以降低参数更新时的方差,收敛更稳定,另一方面可以充分得利用深度学习库中高度优化的矩阵来进行更有效的梯度计算: θ = θ − η ⋅ ∇ θ J ( θ ; x ( i ; i + n ) ; y ( i ; i + n ) ) \theta=\theta-\eta\cdot\nabla_{\theta}J(\theta;x^{(i;i+n)};y^{(i;i+n)}) θ=θ−η⋅∇θJ(θ;x(i;i+n);y(i;i+n))
- 缺点
- MBGD不能保证很好的收敛性,learn rate如果选择的太小,收敛速度会很慢,如果太大,loss function就会在极小值处不停地震荡甚至偏离。
- SGD对所有参数更新时应用同样的 learning rate,如果我们的数据是稀疏的,我们更希望对出现频率低的特征进行大一点的更新。LR会随着更新的次数逐渐变小。
- Momentum(动量梯度下降法)
- 通过加入 y v t = 1 yv_t=1 yvt=1,可以加速SGD,并且抑制震荡: v t = γ v t − 1 + η ∇ θ J ( θ ) ; θ = θ − v t v_t=\gamma v_{t-1}+\eta\nabla_{\theta}J(\theta);\theta=\theta-v_t vt=γvt−1+η∇θJ(θ);θ=θ−vt
- 超参数设定值: γ \gamma γ一般取0.9左右
- Nesterov Accelerated Gradient
-
用 θ − γ v t − 1 \theta-\gamma v_{t-1} θ−γvt−1来近似当做参数下一步会变成的值,则在计算梯度时,不是在当前位置,而是未来的位置上: v t = γ v t − 1 + η ∇ θ J ( θ − γ v t − 1 ) ; θ = θ − v t v_t=\gamma v_{t-1}+\eta\nabla_{\theta}J(\theta-\gamma v_{t-1});\theta=\theta-v_t vt=γvt−1+η∇θJ(θ−γvt−1);θ=θ−vt
-
NAG会在前一步积累梯度上有一个大的跳跃,然后衡量一下梯度做一下修正,这种预期的更新可以避免我们走的太快

-
这个算法可以对低频的参数做较大的更新,对高频的做较小的更新,因此对于稀疏的数据它的表现很好,很好的提高了SGD的鲁棒性(健壮性)
-
梯度更新规则: θ t + 1 = θ t , i − η G t , i i + ϵ ⋅ g t , i \theta_{t+1}=\theta_{t,i}-\frac{\eta}{\sqrt{G_{t,ii}+\epsilon}}\cdot{g_{t,i}} θt+1=θt,i−Gt,ii+ϵη⋅gt,i,其中g为t时刻 θ i \theta_i θi的梯度: g t , i = ∇ θ J ( θ i ) g_{t,i}=\nabla_{\theta}J(\theta_i) gt,i=∇θJ(θi)
-
Adagrad的优点是减少了学习率的手动调节
-
Adagrad的缺点是分布会不断积累,这样学习率就会收缩并最终会变得非常小
-
- Adadelta
- 算法是对Adagrad的改进,就是坟墓的G改成了梯度平方的衰减平均值: ∇ θ t = − θ E [ g 2 ] t + ϵ g t \nabla\theta_t=-\frac{\theta}{\sqrt{E[g^2]_t+\epsilon}}g_t ∇θt=−E[g2]t+ϵθgt
- RMSprop都是为了解决Adagrad学习率急剧下降问题的: E [ g 2 ] t = 0.9 E [ g 2 ] t − 1 + 0.1 g t 2 , θ t + 1 = θ t − η E [ g 2 ] t + ϵ g t E[g^2]_t=0.9E[g^2]_{t-1}+0.1g_t^2,\theta_{t+1}=\theta_t-\frac{\eta}{E[g^2]_t+\epsilon}g_t E[g2]t=0.9E[g2]t−1+0.1gt2,θt+1=θt−E[g2]t+ϵηgt
- Adaptive Moment Estimation(Adam)
- 计算每个参数的自适应学习率的方法:RMSprop+Momentum
- 除了像 Adadelta 和 RMSprop 一样存储了过去梯度的平方 vt 的指数衰减平均值 ,也像 momentum 一样保持了过去梯度 mt 的指数衰减平均值: m t = β 1 m t − 1 + ( 1 − β 1 ) g t ; v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 m_t=\beta_1m_{t-1}+(1-\beta_1)g_t;v_t=\beta_2v_{t-1}+(1-\beta_2)g_t^2 mt=β1mt−1+(1−β1)gt;vt=β2vt−1+(1−β2)gt2
- 如果 m t m_t mt和 v t v_t vt被初始化为0向量,那它们就会向0偏置,所以作了偏差校正,通过计算偏差校正后的 m t m_t mt和 v t v_t vt来抵消这些偏差: m t ^ = m t 1 − θ 1 t ; v t ^ = v t 1 − θ 2 t \hat{m_t}=\frac{m_t}{1-\theta_1^t};\hat{v_t}=\frac{v_t}{1-\theta_2^t} mt^=1−θ1tmt;vt^=1−θ2tvt
- 梯度更新规则: θ t + 1 = θ t − η v t ^ + ϵ m t ^ \theta_{t+1}=\theta_t-\frac{\eta}{\sqrt{\hat{v_t}}+\epsilon\hat{m_t}} θt+1=θt−vt^+ϵmt^η
- 算法选择
- 如果矩阵是稀疏的,就用自适应方法,即Adagrad,Adadelta,RMSprop,Adam(最好选择)
实习记录
- 本周写了一个富阳的脚本用于满足需求
- 内容
- 对于用户提供的经纬度围成的区域不应该直接计算,而是有两种方式
- 使用地图把经纬度区域上传,等待生成栅格编号
- 通过射线算法实现
独热编码
- 离散特征的编码分为两种情况
-
离散特征的取值之间没有大小的意义,毕设color:[red, blue],那么就使用one-hot编码
-
离散特征的取值有大小的意义,比如size:[X,XL,XXL],那么就使用数值的映射{X:1,XL:2,XXL:3}
# 第二种情况的代码 import pandas as pd df = pd.DataFrame([ ['green', 'M', 10.1, 'class1'], ['red', 'L', 13.5, 'class2'], ['blue', 'XL', 15.3, 'class1']]) df.columns = ['color', 'size', 'prize', 'class label'] size_mapping = { 'XL': 3, 'L': 2, 'M': 1} df['size'] = df['size'].map(size_mapping) class_mapping = {label:idx for idx,label in enumerate(set(df['class label']))} df['class label'] = df['class label'].map(class_mapping) -
分类器往往默认数据时连续的,并且是有序的
-
- 独热编码即One-Hot编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都由其它独立的寄存器位,并且在任意时候,其中只有一位有效
- 自然状态码:000,001,010,011,101,101
- 独热编码:000001,000010,000100,001000,010000,100000
- 独热编码可以使数据变得稀疏
- 解决了分类器不好处理属性数据的问题
- 在一定程度上也起到了扩充特征的作用
- 实现方式
- pandas.get_dummies(data, prefix=None, prefix_sep=‘_’, dummy_na=False, columns=None, sparse=False, drop_first=False)
- 通过sklearn实现
- 优缺点
- 优点:独热编码解决了分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用。它的值只有0和1,不同的类型存储在垂直的空间。
- 当类别的数量很多时,特征空间会变得非常大。在这种情况下,一般可以用PCA来减少维度。
总结
- 这周看了看吴恩达老师的深度学习课程,对于参数的处理和梯度计算有了进一步的了解,同时也看了独热编码用于处理离散数据
- 下周应该继续看吴恩达老师的深度学习课程,并且去看t-sne降维算法和一些聚类算法用于实习