MySQL面试题
MySQL面试题
文章目录
- MySQL面试题
-
-
-
- 1,常见的存储引擎
- 2,MyISAM和InnoDB的区别?
- 3,InnoDB和MyISAM如何选择?
- 4,B(B-)树和B+树的区别?
- 5,为什么不用Hash索引?为什么不用平衡二叉树索引?
- 6,为什么索引会失效?
- 7,什么是聚簇索引和非聚簇索引?
- 8,InnoDB为什么推荐使用自增ID作为主键?
- 9,什么是索引覆盖和回表?
- 10,MySQL中锁的类型?
- 11,事务的基本特性(ACID)?
- 12,事务的隔离级别?
- 13,ACID靠什么保证?
- 14,什么是当前读和快照读?
- 15,什么是MVCC?
- 16,什么是幻读?
- 17,什么是间隙锁?
- 18,你们数据量级多大,分库分表怎么做的?
- 19,分表后的ID如何保证唯一性?
- 20,分表后非sharding_key的查询怎么处理?
- 21,mysql主从同步
- 22,如何解决主从延迟?
- 23,平时遇到慢SQL如何调优?
-
-
1,常见的存储引擎
- MyISAM:5.5版本之前的默认引擎,不支持事务。表级锁,支持全文搜索,不支持外键。
- InnoDB:5.5版本后默认的搜索引擎,支持事务。引入了行级锁和外键约束,并拥有较高的并发读取效率。
- MEMORY:速度较快,因为存储在内存中,重启后数据会丢失。
- ARCHIVE:拥有很好的压缩特性,只支持插入和查询。
- CSV:每个表生成一个CSV文件用来存储数据,不支持事务。
2,MyISAM和InnoDB的区别?
-
InnoDB支持事务,MyISAM不支持
-
InnoDB支持外键,MyISAM不支持
-
InnoDB是聚簇索引,MyISAM是非聚簇索引
MyISAM把索引和数据分开存储,索引放xx.myi文件中(数据地址),数据存放在xx.myd文件中。InnoDB数据和索引都存在一个xx.idb文件中。
-
InnoDB不保存全表的具体行数,执行select count(*) from table 时需要全表扫描;而MyISAM用一个变量保存了整个表的行数,因此速度很快(注意不能加where)
- 为什么InnoDB没有了这个行数呢?因为同一时刻表中的行数对于不同的事务而言是不一样的
-
InnoDB不支持全文索引,而MyISAM支持(5.7以后InnoDB支持了)
-
MyISAM只支持表级锁,InnoDB支持行级锁,InnoDB的行锁是实现在索引上的,而不是锁在行记录上。即如果没有命中索引,也会退化为行锁
-
InnoDB必须有唯一索引(如主键),如果没有指定的话会自己生成一个隐藏列row_id来充当默认主键,而MyISAM可以没有
-
InnoDB具有更好的容灾策略
3,InnoDB和MyISAM如何选择?
- 如果要支持事务,选InnoDB
- 如果表中绝大多数甚至全部操作都只是查询,可以考虑MyISAM
- MySQL5.5之后默认就是InnoDB,如果不知道选什么,那么就选InnoDB
4,B(B-)树和B+树的区别?
B树:每个节点都存储key和data,所有节点组成这棵树,并且叶子节点指针为null:

B+树:只有叶子节点存储data,叶子节点包含了这棵树所有的键值,叶子节点不存储指针。
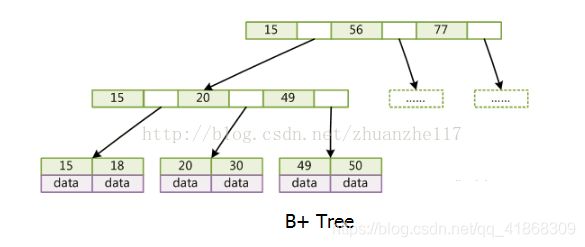
后来在B+树上增加了顺序访问指针(双向链表),也就是每个叶子节点增加一个指向相邻叶子节点的指针。
这样一来我们就看到了B+树的好处:
1,非叶子节点不存储数据保证一次IO能取到更多的节点,减少IO次数,更快找到要查找的数据
2,底部的双向链表更适合我们进行顺序查找和索引排序
5,为什么不用Hash索引?为什么不用平衡二叉树索引?
- Hash值是无序的,既然是无序的,那么就无法通过哈希索引进行范围查找和排序
- 首先平衡二叉树需要成本去维护平衡特性,且范围查找和顺序查找效率较低
6,为什么索引会失效?
先来看一下联合索引在B+树中是如何排序的:

由图中可以看出,联合索引中B+树会先对第一个字段进行排序,在第一个字段相同的情况下再对第二个字段进行排序,更多字段的联合索引以此类推。假如有A,B,C三字段联合索引,以下是几种索引失效的情况:
- 未遵循左前缀法则:如【select * from B=1;】只查B的情况下就会索引失效,因为没有A的情况下,B相当于是无序的。
- 【select * from A>1 and B=1】这种情况下也会导致索引失效,因为A虽然是有序的,找出了A>1的数据之后对于其中B的数据是无序的。
- like查询导致索引失效:未匹配前缀,即百分号在右边。在B+树中,字符排序也是通过头字母开始依次排序的。
还有其他几种情况导致的索引失效:
- is null判断:单列索引不存储null值,复合索引不存储全为null的值
- 条件中有or:除非针对or中的条件字段,分别单独建立索引
- 如果mysql使用全表扫描要比使用索引快,那么将不使用索引。
7,什么是聚簇索引和非聚簇索引?
- 聚簇索引:可以理解为一本书的页码,假设我们翻到了页码为49的这一页,那么这一页包含了49页所有的内容(数据)。
- 非聚簇索引:可以理解为一本书的目录,我们通过目录显示某个内容在第49页,然后我们去49页查看内容。(数据)
8,InnoDB为什么推荐使用自增ID作为主键?
自增ID可以保证每次插入B+Tree时索引是从右边扩展的,可以避免B+树频繁的合并和分裂。如果使用字符串主键和随机主键,会使得数据随即插入,效率较差。
9,什么是索引覆盖和回表?
索引覆盖指的是再一次查询中,如果一个索引包含或者说覆盖所有需要查询的字段的值,我们就称之为覆盖索引,而不需要再回表查询。(从6中联合索引排序就可以看出,如果达不到索引覆盖的条件,将会在找到第一个符合条件的数据之后,再次回表查询这些数据中符合后续条件的数据)
10,MySQL中锁的类型?
mysql锁分为共享锁和排他锁,也叫读锁和写锁。
-
读锁是共享的,可以通过lock in share mode实现【例:select * from user lock in share mode】,这个时候只能读不能写。
-
写锁是排它的,它会阻塞其他写锁和读锁,从颗粒度来分,可以分为表锁和行锁两种。
- 表锁会锁定整张表并且阻塞其他用户对该表的所有读写操作,比如alter修改表结构时会锁表
- 行锁又可以分为乐观锁和悲观锁
- 悲观锁:通过for update实现
- 乐观锁:可以通过版本号实现
11,事务的基本特性(ACID)?
- 原子性:一个事务中的操作要么全部成功,要么全部失败
- 一致性:数据库总是从一个一致性的状态转换到另外一个一致性的状态。比如A转账给B一百块钱,假设SQL执行过程中系统崩溃A也不会损失100块,因为事务还未提交,修改也就不会保存到数据库。
- 隔离性:指的是一个事务的修改在最终提交前对其他事务是不可见的
- 持久性:事务一旦提交,所做的修改就会永久保存到数据库中
12,事务的隔离级别?
- 读未提交(read uncommit):读未提交,即可能会读到其他事务未提交的数据(脏读)
- 如用户本来应该读取到id=1的用户的age应该是10,结果读取到了其他事务还没提交的数据,结果读取结果age=20
- 读已提交(read commit):在本次事务中能读到别的事务已经提交的数据,两次读取的结果不一致,也叫做不可重复读。
- 如用户开启事务读取id=1的用户,查询到age=10,这时另一个事务将age改成了20并提交了事务,这时再读取id=1的用户查到的id就变成了20。
- 可重复读(repeatable read):mysql默认隔离级别,就是每次读取结果都一样,但是有可能会产生幻读。
- 串行化(serializable):各个事务串行执行,一般不会使用,会给每一行读取的数据加锁,导致大量超时和锁竞争的问题。
13,ACID靠什么保证?
- 原子性:原子性有undo log日志保证,它记录了需回滚的日志信息,事务回滚时撤销已经执行成功的sql
- 一致性:由代码层面保证
- 隔离性:MVCC保证
- 持久性:由内存+redo log保证,mysql修改数据的同时在内存和redo log记录这次操作,事务提交的时候通过redo log刷盘,宕机的时候可以从redo log恢复
14,什么是当前读和快照读?
- 当前读:像select lock in share mode(共享锁), select for update ; update, insert ,delete(排他锁)这些操作都是一种当前读,为什么叫当前读?就是它读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。
- 快照读:像不加锁的select操作就是快照读,即不加锁的非阻塞读;快照读的前提是隔离级别不是串行级别,串行级别下的快照读会退化成当前读;之所以出现快照读的情况,是基于提高并发性能的考虑,快照读的实现是基于多版本并发控制,即MVCC,可以认为MVCC是行锁的一个变种,但它在很多情况下,避免了加锁操作,降低了开销;既然是基于多版本,即快照读可能读到的并不一定是数据的最新版本,而有可能是之前的历史版本。
15,什么是MVCC?
多版本并发控制(MVCC)是一种用来解决读-写冲突的无锁并发控制,也就是为事务分配单向增长的时间戳,为每个修改保存一个版本,版本与事务时间戳关联,读操作只读该事务开始前的数据库的快照。
16,什么是幻读?
假如有一个客户表,用户名不可重复,事务A在插入username=张三时,先查询了表中有无张三的信息,确认没有之后执行insert操作,这时事务B新插入了一条张三导致A出现唯一索引冲突,插入失败,这种情况就是幻读。
17,什么是间隙锁?
间隙锁是可重复度级别下才会有的锁,结合MVCC和间隙锁可以解决幻读的问题。假设User表现在有如下几条记录:
| id(主键索引) | age |
|---|---|
| 10 | 18 |
| 20 | 18 |
| 30 | 18 |
而现在有两个事务同时操作这个表(时间依次向下):
| 事务A | 事务B |
|---|---|
| select * from user where id = 20 for update; |
|
| insert into user values(10,20) --成功 | |
| insert into user values(11,20) --失败 | |
| insert into user values(13,20) --失败 | |
| insert into user values(20,20) --失败 |
这时事务B只有第一条插入语句可以插入成功,因为表的间隙mysql自动帮我们生成了区间(左开右闭)。如事务A的操作生成的间隙锁区间就是(10,20],所以id为10的记录可以插入,而20插不进去。
需要注意的是唯一索引是不会有间隙锁的。
18,你们数据量级多大,分库分表怎么做的?
首先分库分表分为垂直和水平两种方式,一般来说我们拆分的顺序是先垂直后水平。
垂直分库
基于现在微服务拆分来说,都是已经做到了垂直分库了。例如用户模块使用用户数据库,项目模块使用项目库。
垂直分表
如果表字段比较多,将不常用的,数据较大的等等做拆分。
水平分表
首先根据业务场景来决定使用什么字段作为分表字段(sharding_key),比如我们现在日交易2kw,可以用user_id作为sharding_key,数据查询支持到最近1个月的交易,超过一个月的做归档处理,那么一个月的数量就是6E,可以分为512张表,那么每张表的数据就在100万左右。
比如用户id为100,那都经过hash(100),然后对512取模,就可以落到对应的表上了。
19,分表后的ID如何保证唯一性?
1,分布式ID,自己实现一套分布式ID生成算法或者使用开源的比如雪花算法这种
2,分表后不使用主键作为查询依据,而是每张表单独新增一个字段作为唯一主键使用,比如订单表订单号是唯一的,不管最终落在哪张表都基于订单号作为查询依据,更新也一样。
20,分表后非sharding_key的查询怎么处理?
比如要按机构查询客户,这时我们可以做一个机构用户映射表,通过机构号查询到用户列表,再通过user_id去查询。
21,mysql主从同步
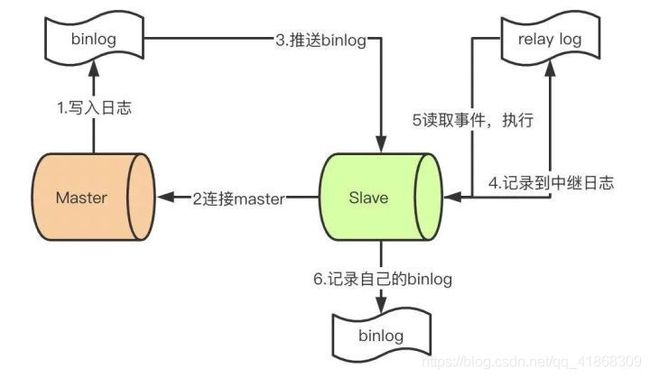
首先先了解mysql主从同步的原理:
- master提交完事务后,写入binlog
- slave连接到master,获取binlog
- master创建dump线程,推送binlog到slave
- slave启动一个IO线程获取同步过来的master的binlog,记录到relay log中继日志中
- slave再开启一个sql线程读取relay log事件并在slave执行,完成同步
- slave记录自己的binlog
由于mysql默认的复制方式是异步的,主库把日志发送给从库后不关心从库是否已经处理,这样会产生一个问题就是假设主库挂了,从库处理失败,这时从库上升为主库后,日志就丢失了。由此产生两个概念:
- 全同步复制:主库写入binlog后强制同步日志到从库,所有从库都执行完后才返回给客户端,但是这个方式性能会受到影响
- 半同步复制:和全同步不同的是,半同步复制的逻辑是这样,从库写入日志成功后返回ack确认给主库,主库收到至少一个从库的确认就认为写操作完成
22,如何解决主从延迟?
23,平时遇到慢SQL如何调优?
-
首先,尽量保证查询SQL走索引:
- 在where和order涉及到的列上建立索引
- 避免在索引上使用计算
- 效率高:where age = 100/20
- 效率低:where age*20 = 100
- 在保证效率的情况下,将多条SQL压缩到一条SQL,避免频繁和数据库交互
- 避免使用select*,要写详细的字段
- 尽量避免全表扫描
- 查询时少用<>,not in这种导致全表扫描的条件
-
如果还是有慢SQL,就开启慢查询日志,查看服务运行时哪条SQL运行速度慢
-
找出运行速度慢的SQL,使用explain执行计划分析,主要看rows,key,type等字段,type中关键字如下:
- all:全表扫描
- index:全表扫描
- RANGE:范围扫描
- ref:使用了索引但不是主键和唯一索引
- ref_eq:唯一性查询,查询的是唯一索引
- const:查询条件为主键,例id = 1
在进行执行计划调优时,应尽量保证查询中每一个语句至少是ref级别的。
mysql和hive的区别(Hive与传统数据库的区别)?
-
Hive采用了类SQL的查询语言HQL(hive query language)。除了HQL之外,其余无任何相似的地方。Hive是为了数据仓库设计的。
-
存储位置:Hive在Hadoop上;Mysql将数据存储在设备或本地系统中;
-
数据更新:Hive不支持数据的改写和添加,是在加载的时候就已经确定好了;数据库可以CRUD;
-
索引:Hive无索引,每次扫描所有数据,底层是MR,并行计算,适用于大数据量;MySQL有索引,适合在线查询数据;
-
执行:Hive底层是MapReduce(大数据计算框架);MySQL底层是执行引擎;
-
可扩展性:Hive:大数据量,慢慢扩去吧;MySQL:相对就很少了
参考博客:
InnoDB和MyISAM区别:https://blog.csdn.net/qq_35642036/article/details/82820178
面试题:https://blog.csdn.net/m0_45270667/article/details/108950184
B和B+树区别:https://blog.csdn.net/zhuanzhe117/article/details/78039692
MVCC:https://www.jianshu.com/p/8845ddca3b23
:
InnoDB和MyISAM区别:https://blog.csdn.net/qq_35642036/article/details/82820178
面试题:https://blog.csdn.net/m0_45270667/article/details/108950184
B和B+树区别:https://blog.csdn.net/zhuanzhe117/article/details/78039692
MVCC:https://www.jianshu.com/p/8845ddca3b23