Visualizing and Understanding Convolutional Networks-ZFNet
博客转载自:http://www.cnblogs.com/taojake-ML/p/6287158.html
在所有深度网络中,卷积神经网和图像处理最为密切相关,卷积网在很多图片分类竞赛中都取得了很好的效果,但卷积网调参过程很不直观,很多时候都是碰运气。为此,卷积网发明者Yann LeCun的得意门生Matthew Zeiler在2013年专门写了一篇论文,阐述了如何用反卷积网络可视化整个卷积网络,并进行分析和调优。称之为ZFNet,其网络结构没什么改进,只是将AlexNet第一层卷积核由11变成7,步长由4变为2,第3,4,5卷积层转变为384,384,256–》512,1024,512。以下首先给出网上找的论文翻译版,使自己清晰地理解论文。然后给出一些对论文的分析和总结。
一、中文版论文


二、相关分析和总结
为了解释卷积神经网络为什么work,我们就需要解释CNN的每一层学习到了什么东西。为了理解网络中间的每一层,提取到特征,paper通过反卷积的方法,进行可视化。反卷积网络可以看成是卷积网络的逆过程。反卷积网络在文献《Adaptive deconvolutional networks for mid and high level feature learning》中被提出,是用于无监督学习的。然而本文的反卷积过程并不具备学习的能力,仅仅是用于可视化一个已经训练好的卷积网络模型,没有学习训练的过程。
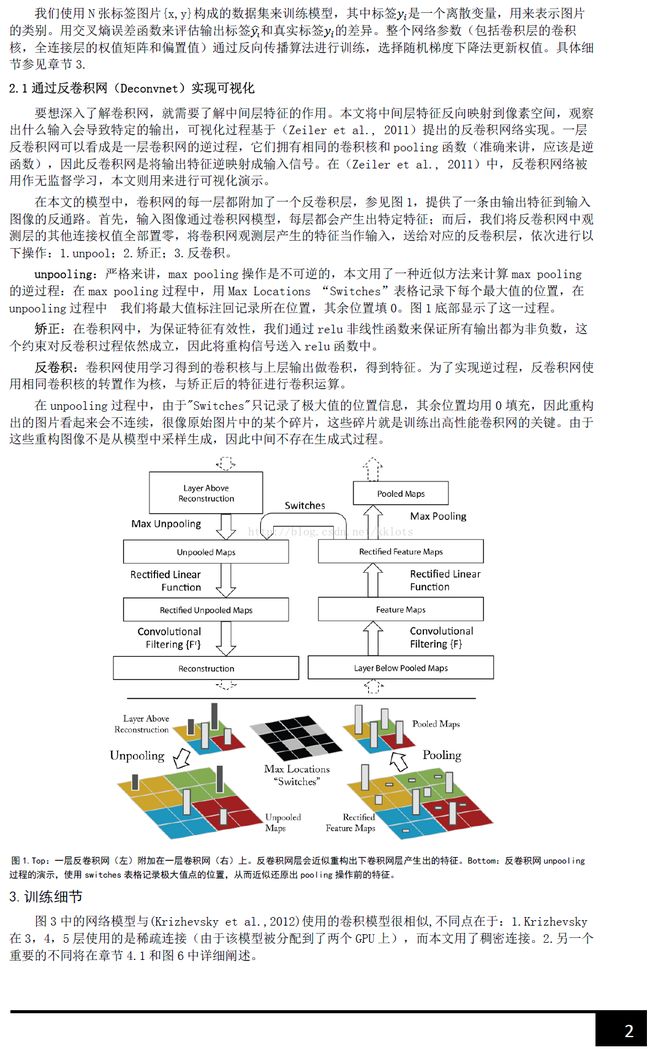
反卷积可视化以各层得到的特征图作为输入,进行反卷积,得到反卷积结果,用以验证显示各层提取到的特征图。举个例子:假如你想要查看Alexnet 的conv5提取到了什么东西,我们就用conv5的特征图后面接一个反卷积网络,然后通过:反池化、反激活、反卷积,这样的一个过程,把本来一张13*13大小的特征图(conv5大小为13*13),放大回去,最后得到一张与原始输入图片一样大小的图片(227*227)。
1、反池化过程
我们知道,池化是不可逆的过程,然而我们可以通过记录池化过程中,最大激活值得坐标位置。然后在反池化的时候,只把池化过程中最大激活值所在的位置坐标的值激活,其它的值置为0,当然这个过程只是一种近似,因为我们在池化的过程中,除了最大值所在的位置,其它的值也是不为0的。刚好最近几天看到文献:《Stacked What-Where Auto-encoders》,里面有个反卷积示意图画的比较好,所有就截下图,用这篇文献的示意图进行讲解:

以上面的图片为例,上面的图片中左边表示pooling过程,右边表示unpooling过程。假设我们pooling块的大小是3*3,采用max pooling后,我们可以得到一个输出神经元其激活值为9,pooling是一个下采样的过程,本来是3*3大小,经过pooling后,就变成了1*1大小的图片了。而upooling刚好与pooling过程相反,它是一个上采样的过程,是pooling的一个反向运算,当我们由一个神经元要扩展到3*3个神经元的时候,我们需要借助于pooling过程中,记录下最大值所在的位置坐标(0,1),然后在unpooling过程的时候,就把(0,1)这个像素点的位置填上去,其它的神经元激活值全部为0。再来一个例子:

在max pooling的时候,我们不仅要得到最大值,同时还要记录下最大值得坐标(-1,-1),然后再unpooling的时候,就直接把(-1-1)这个点的值填上去,其它的激活值全部为0。
2、反激活
我们在Alexnet中,relu函数是用于保证每层输出的激活值都是正数,因此对于反向过程,我们同样需要保证每层的特征图为正值,也就是说这个反激活过程和激活过程没有什么差别,都是直接采用relu函数。
3、反卷积
对于反卷积过程,采用卷积过程转置后的滤波器(参数一样,只不过把参数矩阵水平和垂直方向翻转了一下),这一点我现在也不是很明白,估计要采用数学的相关理论进行证明。
最后可视化网络结构如下:

网络的整个过程,从右边开始:输入图片-》卷积-》Relu-》最大池化-》得到结果特征图-》反池化-》Relu-》反卷积。到了这边,可以说我们的算法已经学习完毕了,其它部分是文献要解释理解CNN部分,可学可不学。
总的来说算法主要有两个关键点:1、反池化 2、反卷积,这两个源码的实现方法,需要好好理解。
特征可视化:一旦我们的网络训练完毕了,我们就可以进行可视化,查看学习到了什么东西。但是要怎么看?怎么理解,又是一回事了。我们利用上面的反卷积网络,对每一层的特征图进行查看。
1、特征可视化结果:
总的来说,通过CNN学习后,我们学习到的特征,是具有辨别性的特征,比如要我们区分人脸和狗头,那么通过CNN学习后,背景部位的激活度基本很少,我们通过可视化就可以看到我们提取到的特征忽视了背景,而是把关键的信息给提取出来了。从layer 1、layer 2学习到的特征基本上是颜色、边缘等低层特征;layer 3则开始稍微变得复杂,学习到的是纹理特征,比如上面的一些网格纹理;layer 4学习到的则是比较有区别性的特征,比如狗头;layer 5学习到的则是完整的,具有辨别性关键特征。
2、特征学习的过程。

作者给我们显示了,在网络训练过程中,每一层学习到的特征是怎么变化的,上面每一整张图片是网络的某一层特征图,然后每一行有8个小图片,分别表示网络epochs次数为:1、2、5、10、20、30、40、64的特征图:
结果:(1)仔细看每一层,在迭代的过程中的变化,出现了sudden jumps;(2)从层与层之间做比较,我们可以看到,低层在训练的过程中基本没啥变化,比较容易收敛,高层的特征学习则变化很大。这解释了低层网络的从训练开始,基本上没有太大的变化,因为梯度弥散嘛。(3)从高层网络conv5的变化过程,我们可以看到,刚开始几次的迭代,基本变化不是很大,但是到了40~50的迭代的时候,变化很大,因此我们以后在训练网络的时候,不要着急看结果,看结果需要保证网络收敛。
3、图像变换。
从文献中的图片5可视化结果,我们可以看到对于一张经过缩放、平移等操作的图片来说:对网络的第一层影响比较大,到了后面几层,基本上这些变换提取到的特征没什么比较大的变化。
个人总结:我个人感觉学习这篇文献的算法,不在于可视化,而在于学习反卷积网络,如果懂得了反卷积网络,那么在以后的文献中,你会经常遇到这个算法。大部分CNN结构中,如果网络的输出是一整张图片的话,那么就需要使用到反卷积网络,比如图片语义分割、图片去模糊、可视化、图片无监督学习、图片深度估计,像这种网络的输出是一整张图片的任务,很多都有相关的文献,而且都是利用了反卷积网络,取得了牛逼哄哄的结果。所以我觉得我学习这篇文献,更大的意义在于学习反卷积网络。
作者提出了两点问题:为什么深度卷积神经网络性能如此好?如何再提升该网络呢?作者做了几组实验,分别证明了从实验现象上解释了这两个问题,可以详细来了解一下,包括其设计实验的技巧。
1,为什么深度网络性能如此好?
回答该问题,首先从实验结果来看,较高层次提取的feature对于平移和尺度变化具有不变性(对非中心对称的旋转不具有不变性)。
其次,通过设计实验来验证在图像分类问题中,深度神经网络是能够确定物体位置还是仅与其周围内容有关,作者对图像不同部分用gray square进行遮挡,以一下参数变化来反映模型能够identify物体的位置:(1)发现当遮住物体时,正确类别的概率值下降特别明显;(2)遮住feature map响应最大的物体时,整体的activity下降很大;(3)最有可能的标记如果是某一物体,这个物体遮挡后,其概率下降很大。
深度模型在隐含地计算correspondence between specific object parts in different images。作者利用5幅狗的图像,每次遮住相同物体的某些部位,对其中一幅图像,可以计算遮住某部位前后特征向量的变化,而再计算不同图像之间这种变化的相似度,相似度高说明不同图像中狗的这些部位变化对最终分类结果影响很相近,来证明深度模型对不同部位能够建立一定的correspondence。
总起来在证明什么呢?在证明深度模型提取的特征具有不变性,而且能够identify物体的位置,不仅如此还能够建立一种物体与其不同部位(即使不同图像存在变化)有一定relation。这都在说明深度网络性能为什么这么好!
2,如何再提升该网络呢?
回答该问题,作者通过将feature map中的个别较大响应可视化发现,在卷积的过程中尺寸选择较大时会出现aliasing artifacts,因此减小这些参数能够提升深度网络的性能,其实验结果也证明如此。
当然,作者在实验过程中通过变化网络的深度等,提出了很多事实,也可以看一下。
相关参考文献:
http://blog.csdn.net/chenyanqiao2010/article/details/50488075
http://www.gageet.com/2014/10235.php
http://blog.csdn.net/tina_ttl/article/details/52048765
http://blog.csdn.net/kklots/article/details/17136059
http://blog.sina.com.cn/s/blog_6caa9fa10101lzcy.html