TP,FP,TN,FN,FAR,FRR,HTER等常见实验指标理解
目录
一、TP,TN,FP,FN
二、FAR,FRR
三、Recall,Precision,Accuracy
四、ROC,TPR,FPR,AUC
五、HTER,EER
六、APCER,NPCER(BPCER),ACER
一、TP,TN,FP,FN
前面的字母表示这次预测的结果是正确还是错误(T就是预测结果是对的,F就是预测结果是错误的),后面的字母表示这次预测结果(P就是预测的结果是正类,N就是预测的结果为负类)。
比如TP,表面意思是正确(True)的正例(Positive),即标签是x,预测也是x (P和N表示两种类别),全称叫True Positive,其它三个同理。
- TP:被模型预测为正类的正样本(原本是正样本,预测为正样本)
- TN:被模型预测为负类的负样本(原本是负样本,预测为负样本)
- FP:被模型预测为正类的负样本(原本是负样本,预测为正样本)
- FN:被模型预测为负类的正样本(原本是正样本,预测为的负样本)
| 实际情况 | 预测情况 | |
| 正例 | 反例 | |
| 正例 | TP | FN |
| 反例 | FP | TP |
二、FAR,FRR
FAR和FRR全称分别为False Accept Rate(误识率)和False Rejection Rate(拒识率)。
FAR:错误地接受,即将错误的判别为正确的,实际的标签为N,但是预测错误为P,所以对应FP。
![]()
数据集中标签为N,但预测为P的样本占数据集中所有标签为N的比例。
注:有的论文也会将FAR写作FMR(False match rate)。
FRR:错误地拒绝,即将正确的判别为错误的,实际的标签为P,但是预测错误为N,所以对应FN。
![]()
数据集中标签为P,但预测为N的样本占数据集中所有标签为P的比例。
注:有的论文也会将FRR写作FNMR(False non-match rate)。
三、Recall,Precision,Accuracy
Recall:召回率,即实际为P的样本中预测为P的样本的占比,越大越好。
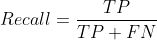
可以得到:
![]()
Precision:准确率、精度,即从预测的角度出发,被分为正例的样本中实际为正例的比例。

Accuracy:准确率,即所有样本中预测正确的占比,计算方式为被分对的样本数除以总的样本数,通常来说,正确率越高,分类器越好。但是在正负样本不平衡的情况下,这个评价指标有很大缺陷。如在互联网广告里面,点击的数量是很少的,一般只有千分之几,如果用acc,即使全部预测成负类(不点击)acc也有 99% 以上,没有意义。
![]()
四、ROC,TPR,FPR,AUC
ROC:受试者工作特征曲线(receiver operating characteristic curve,简称ROC曲线),又称为感受性曲线(sensitivity curve)。
TPR:真正类率,即所有正样本中被分类器预测为正样本的个数。

FPR:假正类率,即所有负样本中被分类器预测为正样本的个数。

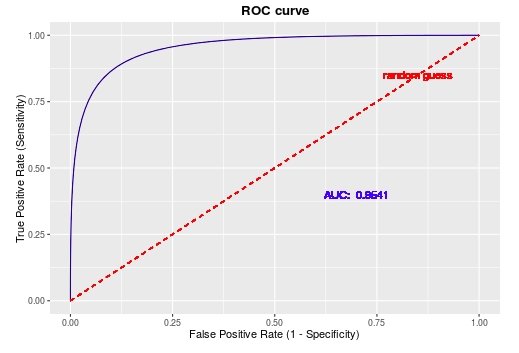
ROC曲线,其横坐标是FPR,纵坐标是TPR。
需要注意,虽然TPR和FPR看起来没有关系,因为一个计算的是正样本,一个计算的是负样本,而样本总数是固定的。但阈值的选定会影响TPR和FPR的值。
在理想情况下,我们都希望一个分类器能够将所有的正类均正确分类对应TPR=1,并将所有的负类也正确分类对应FPR=0。因此,ROC曲线越靠拢(0,1)点,越偏离45度对角线越好。
ROC本质上就是在设定某一阈值之后,计算出该阈值对应的TPR 和 FPR,便可以绘制出ROC曲线上的一个点。其正是通过不断移动分类器的“正例阈值”来生成曲线上的一组关键点的。
AUC(Area Under Curve):为ROC曲线下方的面积大小。显然,AUC越大,预测效果越好,一般AUC取值范围一般在0.5和1之间。
使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
- AUC=1,是完美分类器,采用这个预测模型时,不管设定什么截断点都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5
- AUC=0.5,跟随机猜测一样(例:抛硬币),模型没有预测价值。
- AUC<0.5,比随机猜测还差,但只要总是反预测而行,就优于随机预测。
五、HTER,EER
HTER:Half Total Error Rate,将FAR和FRR都考虑进去,通常应用于活体检测中。
![]()
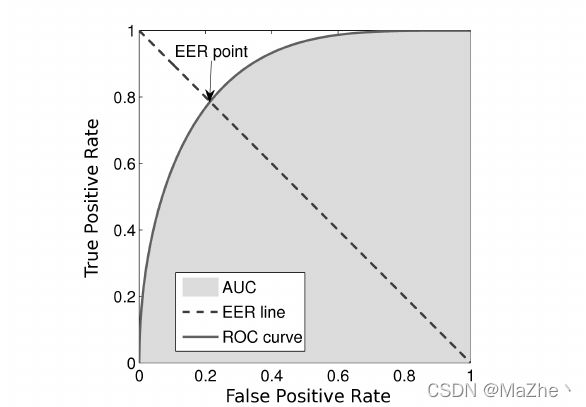
EER:Equal Error Rate,指当阈值取某个值是FPR=TRR,此时该值即为EER。
六、APCER,NPCER(BPCER),ACER
在活体检测中,通常将攻击视为正样本,而真实人脸视为负样本。
APCER:Attack Presentation Classification Error Rate,将攻击(正样本)识别为真实人脸(负样本),即将攻击错误分类。与FRR计算方式相同。
![]()
NPCER:Normal Presentation Classification Error Rate,将真实人脸(负样本)识别为攻击(正样本),即将真实样本错误分类。与FAR计算方式相同。
![]()
ACER:Average Classification Error Rate,平均分类错误率。
![]()
References:
如何理解TP,FP,TN,FN,FAR,FRR,HTER等变量 - 程序员大本营
[深度概念]·评估指标EER(Equal Error Rate)介绍_小宋是呢的博客-CSDN博客_equal error rate
https://www.quora.com/How-can-I-understand-the-EER-Equal-Error-Rate-and-why-we-use-it
机器学习:准确率(Precision)、召回率(Recall)、F值(F-Measure)、ROC曲线、PR曲线_nana-li的博客-CSDN博客_recall 如何理解误识率(FAR)拒识率(FRR),TPR,FPR以及ROC曲线_2014wzy的博客-CSDN博客_far frr