opencv进阶-SSD模型实时人脸检测
reference:利用OpenCV和深度学习实现人脸检测
2018年之后,opencv DNN模式下开始使用卷积神经网络SSD人脸检测器,目前商业应用非常成熟,可以做到实时运行,对各种角度人脸均能做到准确的检测,具有很强的抗干扰性。
opencv自带的人脸检测模型
一、先安装opencv
二、下载模型文件
打开windows下的终端,点击左下角的徽标键,输入cmd即可。然后在终端输入cd /d D:\opencv-4.1.0\opencv\sources\samples\dnn\face_detector
然后继续输入:python download_weights.py,这样就会根据权重文件生成配置文件和模型文件。
三、查看参数
进入models.yml文件,查看需要设置的参数。文件路径:D:\opencv-4.1.0\opencv\sources\samples\dnn
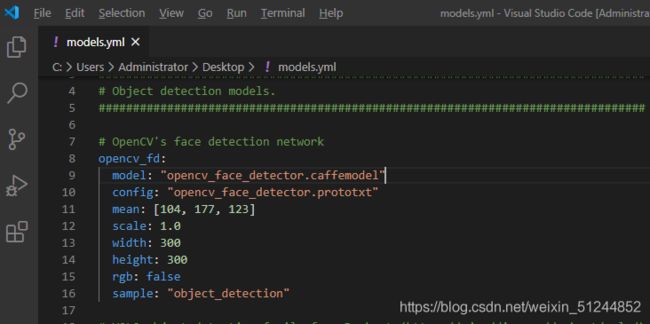
四、全部代码
1.基于caffe
基于caffe框架下的SSD深度卷积神经网络模型,做人脸检测。
.prototxt和.caffemodel的作用如下:
The .prototxt file(s) which define the model architecture (i.e., the layers themselves)
The .caffemodel file which contains the weights for the actual layers
#include 2.基于TensorFlow
基于TensorFlow的SSD模型,人脸检测。
#include 在笔记本上运行,还挺流程的。
