Longformer论文解读和代码解析
前言
这篇博文记录了longformer论文的主要思想、代码实现和结果复现方面的一些工作,相关链接如下:
原longformer论文地址
github上原作者公开的代码
huggingface上原作者编辑的longformer模块
原论文解读
其时transformer-xl已经突破了transformer对处理文本长度的限制,那longformer的意义是什么呢?原作者的解释是这样的:
transformer-xl处理长文本时按从左到右的方式自回归处理,这样每一个segment只能看到其所在的segment和其之前的segment,而看不到其后方的内容。这对于需要双向信息的任务是不利的(比如QA),而longformer将整个长文本直接输入,避免了transformer-xl的问题。
longformer的核心技术
longformer本质上是一种sparse attention的方法,也就是每个token不是attend到整个输入文本,而仅attend一个窗口大小的范围。这个窗口在此token附近。 根据前人的工作[1],这种处理是合理的。并且将模型运行的时间复杂度从与文本长度的二次相关降到了一次相关。
需要注意的是,这里的一次相关不是如下形式: r e q u i r e d _ t i m e = k ∗ l e n ( c o n t e x t ) + b required\_time=k*len(context)+b required_time=k∗len(context)+b而是这样的: r e q u i r e d _ t i m e = k ∗ T ∗ ⌈ ( l e n ( c o n t e x t ) l e n ( s l i d i n g _ w i n d o w ) ) ⌉ + b required\_time=k*T*\lceil (\frac{len(context)}{len(sliding\_window)})\rceil+b required_time=k∗T∗⌈(len(sliding_window)len(context))⌉+blongformer将输入文本长度截断/填充到了滑动窗口长度的整数倍,对应了向下取整/向上取整(上面公式只列出一种情况)。上述公式中的参数 T T T和 l e n ( s l i d i n g _ w i n d o w ) len(sliding\_window) len(sliding_window)二次相关。在作者原代码中,为了和roberta做比较, l e n ( s l i d i n g _ w i n d o w ) = 512 len(sliding\_window)=512 len(sliding_window)=512。
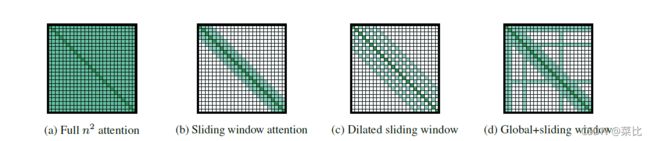
Attention Pattern
Sliding Window
原始Transformer中的self attention矩阵如上图(a)所示,任何两个位置间都是有关联的。而sliding window是“缩水版”attention,每一个向量只和有限个其他位置的向量间有attention关联。这“有限个其他位置”排列在此向量左右(左右各一半),如上图(b)所示。
还记得在transformer-xl中Zihang Dai提到的vanilla model吗?也就是将长文本划分为一个个较短的、交集为空而并集为全集的segment,然后依次处理各segment,不同segment间没有信息传递[2]。按笔者理解,sliding window的思想和这种原始的方法很相似,只不过vanilla model是静态分割segment,sliding window是动态生成segment;vanilla model各segment间没有交集,而sliding window各segment间有交集。
这里对论文中的一段话再额外解释一下:
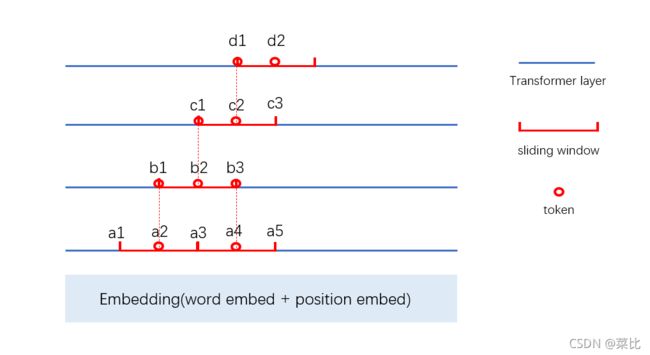
In a transformer with l l l layers, the receptive field size at the top layer is l ∗ w l*w l∗w (assuming w w w is fixed for all layers)
如下图所示,假设下图所有的sliding window大小均为 w w w。第一层中,token a 2 a_2 a2的attention能覆盖的范围就是一个窗口大小 w w w;第二层中,token b 2 b_2 b2的attention在第二层能覆盖的范围也是 w w w,即 b 1 b_1 b1到 b 3 b_3 b3。但这一层的token都是从下面一层,也就是第一层传上来的,所以 b 1 b_1 b1包含了 a 2 a_2 a2捕获到的上下文信息, b 3 b_3 b3包含了 a 4 a_4 a4捕获到的上下文信息,也就是说, b 2 b_2 b2能利用到从 a 1 a_1 a1到 a 5 a_5 a5的全部信息,而 a 1 a_1 a1到 a 5 a_5 a5的context长度为 2 ∗ w 2*w 2∗w。同理可知, c 2 c_2 c2能利用的context范围为 3 ∗ w 3*w 3∗w, d 2 d_2 d2能利用的context范围为 4 ∗ w 4*w 4∗w,第 n n n层的token能利用的context范围为 m i n ( m a x _ s e q _ l e n , n ∗ w ) min(max\_seq\_len, n*w) min(max_seq_len,n∗w)。所以,longformer底层的layer仅能获取到局部信息,越上层的layer能获取到的信息越多。
Dilated Sliding Window
Dilated Sliding Window如前图c中所示,每一个token的sliding window不是紧密靠在token左右,而是在token左右两边分散开。比如说token a a a右边有m个需要attend到的对象 [ a 1 , a 2 . . . a m ] [a_1,a_2...a_m] [a1,a2...am]( l e n ( s l i d i n g _ w i n d o w ) = 2 m len(sliding\_window)=2m len(sliding_window)=2m),那么 a 1 a_1 a1和 a 2 a_2 a2间会空出 d d d个token,这 d d d个token和 a a a之间没有attention连接。同理于任意的 a n a_n an和 a n + 1 a_{n+1} an+1之间。
Global Attention
Global Attention如前图d中的水平、竖直标线所示。拥有global attention的token会通过global attention关联到输入的每一个token。而对称的,被关联到的token除了要attend到自己sliding window里的token,还要attend到所有使用了global attention的token。
Global Attention在下游任务中起到重要作用。比如QA中,为question的每个token都设置了global attention;在分类任务中,为[CLS]设置了global attention。
另外要注意的是,计算Global Attention的 k , q , v k, q, v k,q,v时使用和计算Sliding Window的 k , q , v k, q, v k,q,v不同的参数。
Pretrain-finetune
longformer引入了Pretrain-finetune机制。原作者在使用roberta参数初始化longformer模型参数的基础上,又通过mlm任务进行预训练,得到了longformer-base和longformer-large两个规模的预训练模型。预训练好的模型在原github项目和huggingface中都能找到(huggingface中使用YourAimedModel.from_pretrained("allenai/longformer-base-4096")即可加载base模型参数,large同理)
longformer代码解析
经过预训练的longformer在多个下游任务上取得了优秀的效果。这里不一一列举,请读者阅读原论文了解更多细节。我们这里只提一下复现论文效果时的一些注意事项。
https://github.com/allenai/longformer上的代码是基于pytorch-lightning和huggingface transformer实现的,笔者通过readme中的方法配环境没有成功,反倒是根据代码自己配的环境能让代码正常运行。
另外,https://github.com/allenai/longformer中scripts里的cheatsheet.txt写的是有问题的。如果读者按其命令运行,是得不到论文中提到的在triviaqa上的效果的。这个问题其实已经有大佬解决了,只是cheatsheet迟迟没有更新。此问题的解决办法见longformer论文中triviaqa上效果复现。由于有的人可能打不开链接或不清楚大佬是怎么做的,我将其截图如下并加以解释

首先,--save_prefix triviaqa-longformer-large并不能正确的加载预训练模型参数,导致测试结果极差。想要正确加载参数,我们需要用到--resume_ckpt path/to/triviaqa-longformer-large/checkpoints/ckpt_epoch_4_v2.ckpt。可是在github上下载的triviaqa-longformer-large/checkpoints/ckpt_epoch_4_v2.ckpt通过上述方法加载还会失败,所以我们要对checkpoint内容进行修改。这种修改在python terminal里进行即可。修改代码如下:
checkpoint = torch.load("path/to/triviaqa-longformer-large/checkpoints/ckpt_epoch_4_v2.ckpt")
checkpoint["state_dict"]["model.embeddings.position_ids"] = torch.arange(4098).to('cuda').unsqueeze(0)
checkpoint["checkpoint_callback_best_model_path"]="" # some versions of pytorch lightning may not need this
torch.save(checkpoint, "path/to/triviaqa-longformer-large/checkpoints/fixed_ckpt_epoch_4_v2.ckpt")
修改完后,使用--resume_ckpt path/to/triviaqa-longformer-large/checkpoints/fixed_ckpt_epoch_4_v2.ckpt就可以啦。我测试的效果如下:
{‘exact_match’: 73.16401851620168, ‘f1’: 77.782891117113}
Huggingface Longformer
https://huggingface.co/transformers/model_doc/longformer.html
Huggingface中实现了Longformer,并且是作者本人实现的。但是,上文中提到的Dilated Sliding Window并没有被实现,而且Huggingface中还给出了提示DISCLAIMER: This model is still a work in progress, if you see something strange, file a Github Issue.但不论怎样,这里给出的实现比github中原项目更易用。需要注意的是,longformer相关模型的forward函数都需要一个参数global_attention_mask用于标定需要使用global attention的token。虽然这个参数是可选的,但笔者建议大家用的时候加上这个参数。
对于Huggingface中Longformer的实现和原Longformer实现的区别,github上有一个相关的issue,但还没有答复。大家可以关注一下https://github.com/allenai/longformer/issues/210
最后提一点,longformer的最长处理长度不是4096。但是为了在可接受时间内得到结果,论文的作者在预训练longformer模型时,将输入的长度都限制在了4096个token内,超过4096个token的部分会被直接截断。
另外,longformer的时间复杂度虽然和输入长度线性相关,但这绝对不代表longformer对计算资源的需求小。恰恰相反,longformer对计算资源的需求远大于roberta。如果想在longformer上pretrain或finetune,v100是不错的选择。
Reference
[1] Olga V. Kovaleva, Alexey Romanov, Anna Rogers, and Anna Rumshisky. 2019. Revealing the dark secrets of bert. In EMNLP/IJCNLP.
[2] Zihang Dai, Zhilin Yang, Yiming Yang, William W Cohen, Jaime Carbonell, Quoc V Le, and Ruslan Salakhutdinov. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860, 2019.