机器学习实战——泰坦尼克号
通过泰坦尼克号生存项目来熟悉机器学习的整个流程,数据来源是kaggle上的titanic数据。该项目从数据获取->数据清洗->特征处理->构建模型->模型评估5个步骤进行分析。

该比赛提供了891名泰坦尼克号的乘客数据,包含乘客的姓名,性别、年龄、客舱等级等信息,数据中还包含一个最重要的信息:乘客是否生还(1:生还,0:遇难)。目的是通过对训练数据集的学习来构建一个分类预测模型,对测试数据集中的418名乘客生存情况进行预测。
数据来源链接:https://www.kaggle.com/c/titanic/data
- train.csv 用于训练,标记了乘客是否生还的信息
- test.csv 用于测试,没有标记乘客是否生还信息,该数据集需要用模型来预测乘客是否生还
数据导入:
导入我们的训练数据和测试数据
# 导入包:
import pandas as pd
import numpy as np
# 读取数据:
train_data = pd.read_csv("/Desktop/泰坦尼克号/train.csv")
test_data = pd.read_csv("/Desktop/泰坦尼克号/test.csv")
# 查看前5行
train_data.head()
数据字段的含义:
数据集中有12 个字段,每一个字段的名称和含义如下
- PassengerId:乘客 ID
- Survived:是否生存
- Pclass:客舱等级
- Name:乘客姓名
- Sex:性别
- Age:年龄
- SibSp:在船兄弟姐妹数/配偶数
- Parch:在船父母数/子女数
- Ticket:船票编号
- Fare:船票价格
- Cabin:客舱号
- Embarked:登船港口
查看数据基本信息:
# 查看数据基本信息
train_data.info()
从上面info()中我们可以看出,Age, Cabin, Embarked这三个变量有缺失值。
删除一些无效的数据列:
有些变量在模型中是没有意义的,所以我们可直接在train_data中删除一些没有意义的变量,通过drop()方法来删除:PassengerId,Name,Ticket
# 删除无效的数据变量
train_data=train_data.drop(['PassengerId','Name','Ticket'],axis=1)
train_data.head()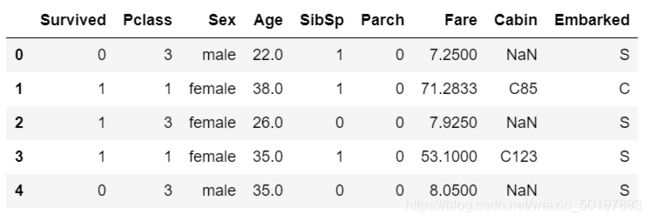
单变量分析:
单变量数据就是每次只对1个变量进行分析,相对的,多变量数据就是同时对多个变量之间的相关性进行分析。单变量数据分析主要目的是对单个变量的数据分布进行查看,方便后期的数据预处理,常用的单变量分析方法有:频数分析、描述性统计、直方图等。
- 频数分析:分析类别型变量每一个值出现的频数。
- 描述性统计:对数值型变量的常用统计量进行分析:均值,总和,最小值,最大值,分位数。
- 直方图:对数值型变量进行分段处理后进行频数分析并作图。
频数分析:(类别型变量)
数据集中的 Survived(是否生还), Pclass(客舱等级), Sex(性 别), Embarked(登船港口)等变量是类别型变量,所以可对他们进行频数分析。
1、变量Survived(是否生还)的频数分析及可视化:
# 统计频数
Survived_freq=train_data.Survived.value_counts()
print(Survived_freq)
# 统计结果的可视化分析(条形图和饼图)
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.figure(figsize=(12,5))
plt.subplot(121)
sns.countplot(x='Survived',data=train_data)
plt.title('Count')
plt.subplot(122)
plt.pie(Survived_freq,labels=Survived_freq.index,autopct='%1.0f%%')
plt.title('percent')
plt.show
我们从上述的分析中可以看出,训练样本中有38%的乘客生还了。
2、变量Pclass(客舱等级)的频数分析及可视化:
# 统计频数
Pclass_freq=train_data.Pclass.value_counts()
print(Pclass_freq)
# 统计结果的可视化分析(条形图和饼图)
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(12,5))
plt.subplot(121)
sns.countplot(x='Pclass',data=train_data)
plt.title('Count')
plt.subplot(122)
plt.pie(Pclass_freq,labels=Pclass_freq.index,autopct='%1.0f%%')
plt.title('percent')
plt.show()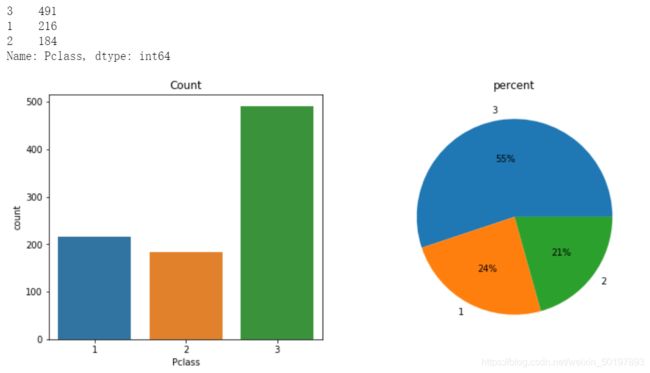
我们从上述的频数分析中可以看出,训练样本中3等舱的乘客最多占比55%,2等舱最少占比21%,1等舱占比24%。
3、变量Sex(性别)的频数分析及可视化:
# 统计频数
Sex_freq=train_data.Sex.value_counts()
print(Sex_freq)
# 统计结果的可视化分析(条形图和饼图)
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(12,5))
plt.subplot(121)
sns.countplot(x='Sex',data=train_data)
plt.title('Count')
plt.subplot(122)
plt.pie(Sex_freq,labels=Sex_freq.index,autopct='%1.0f%%')
plt.title('percent')
plt.show()
从上述分析中可得出训练样本中女性乘客314人,占比35%;男性乘客577人,占65%。
4、变量Embarked(登船港口)的频数分析及可视化:
# 统计频数
Embarked_freq=train_data.Embarked.value_counts()
print(Embarked_freq)
# 统计结果的可视化分析(条形图和饼图)
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(12,5))
plt.subplot(121)
sns.countplot(x='Embarked',data=train_data)
plt.title('Count')
plt.subplot(122)
plt.pie(Embarked_freq,labels=Embarked_freq.index,autopct='%1.0f%%')
plt.title('percent')
plt.show()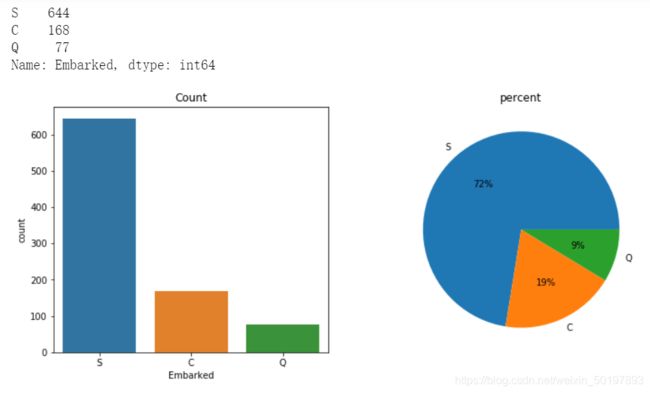
我们从上述的频数分析中可以看出,训练样本中港口S处登船的乘客最多,占比72%;港口Q最少,占比9%;港口C占比19%。
直方图:(连续型变量)
直方图用来查看连续型变量的取值分布情况,通过pandas数据对象的hist()方法来绘制直方图
# Age(年龄)直方图,把Age划分为50个区间绘图直方图,使用hist()
plt.figure(figsize=(20,5))
plt.subplot(221)
train_data['Age'].hist(bins=50)
plt.xlabel('Age')
plt.ylabel('Frequence')
plt.show()
我们从Age直方图可以看到,直方图的中间部分高,两边低,乘客的年龄主要分布在20-40之间。
描述性统计:
对所有的数值型变量进行描述性统计
train_data.describe()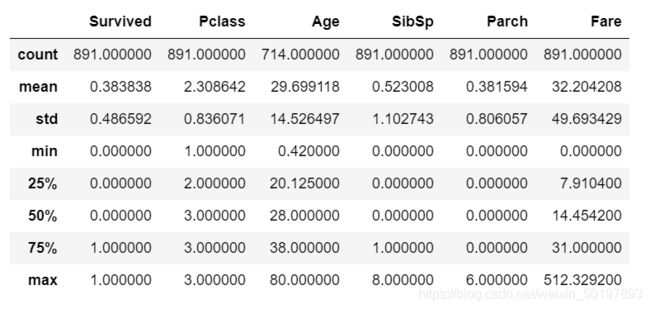
统计量的含义:
- count:非空值频数
- mean:均值
- std:标准差
- min:最小值
- 25%: 25%分位数,又叫下四分位数
- 50%: 50%分位数,又叫中位数(median)
- 75%: 75%分位数,又叫上四分位数
- max:最大值
从上面的描述性统计中得出结论: Age 变量的均值是29.7 岁,最小的乘客只有0.4 岁,最大的有 80 岁,中位值是28 岁,也就是说50%的乘客是28 岁以上,另外50%的乘客是28 岁以下。
分位数可自定义:
一般情况下describe()提供的分位数是25%,50%,75%三个位置的分位数,若分位数的精度不够,我们可以通过用qunantile()方法来自定义分位数
比如:10%,20%,30%,...,100%位置的分位数:
train_data.quantile([0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1])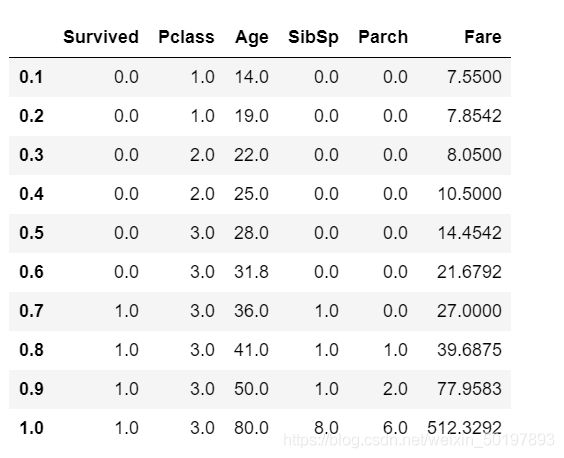
以Age(年龄)来理解下分位数,当分位数位置在60%时年龄的值是31.8,也就是说:60%的乘客年龄小于31.8岁,反过来说就是40%的乘客年龄大于31.8岁。31.8 岁就是所有乘客的年龄从高到底排序后,位于最高的 top40%的那个临界点的年龄值。所以最大值我们又叫 100%分位数,最小值就是 0%分位数了。
多变量分析:
多变量分析是同时探索多个变量之间的相关关系。最简单的多变量就是分析 2 个变量之间的相关性。在单变量分析的时候不同类型的变量分析方法是不一样的,比如类别型变量使用频数统计,而数值型变量使用描述性分析。同样的,两个变量之间的相关性分析,也要区分变量类型。
- 两个数值型变量之间的相关性方法方法:使用散点图
- 两个类别型变量之间的相关性分析方法:适合用交叉表(crosstab)与堆栈条
- 一个数值型变量,一个类别型变量分析方法:适合用分类汇总(groupby)统计
两个数值型变量的相关性分析
大部分情况下,两个变量的相关性分析,一个变量会作为自变量x,另一个变量会作为目标变量(也就是因变量)y,在该项目中目标变量(是否生还)是一个类别型变量,故在此不能使用两个数值型变量的相关性分析,我们选择两个数值型的自变量来做一个数值型变量的相关性分析的示例。
如:我们选用Age(年龄)和 Fare(船票价格) 两个数值型变量
# Age(年龄)和 Fare(船票价格) 两个数值型变量
import matplotlib.pyplot as plt
plt.scatter(train_data.Age,train_data.Fare,50,'blue')
plt.show() 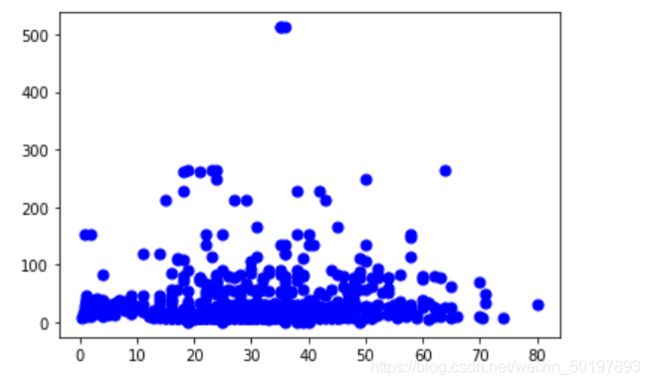
从散点图中我们可以得出结论:船票价格和年龄之间没有很强的相关性
两个类别型变量的相关性分析
通过对每一个类别变量与目标变量(类别变量)的相关性分析,我们可以知道哪些特征与目标变量的相关性最强。
分析Pclass客舱等级与目标变量Survived之间的相关性
# Survived VS Pclass交叉表
pd.crosstab(train_data.Survived,train_data.Pclass,margins=True)
计算每个客舱等级下生还乘客和遇难乘客的占比,我们可按列进行统计汇总
# Survived VS Pclass 交叉表,单元格显示的是列百分比
pd.crosstab(train_data.Survived,train_data.Pclass).apply(lambda r:r/r.sum(),axis=0)
通过对 Pclass 与 Survived 的交叉表分析,我们发现船舱等级与是否生有非常强的相关性:
- 1等舱的生还率是 62.96%,
- 2等舱的生还率是 47.28%,
- 3等舱的生还率是24.23%
与此我们可得:不同船舱等级的生还率差异比较大
交叉表分析结果可视化(堆栈条图)
有时候我们使用堆栈条图的方式来展现两个类别变量的相关性,堆栈条图是 crosstab 交叉表生成的结果展示。
# 使用crosstab生成作堆栈条图的数据
# 注:需要去掉margins=True,作图的时候不需要行列汇总的数据
data=pd.crosstab(train_data.Survived,train_data.Pclass)
# 绘制堆栈条图
data.plot(kind='bar',stacked=True)
plt.title('Pclass VS Survived')
plt.ylabel('Frequnce')
plt.show()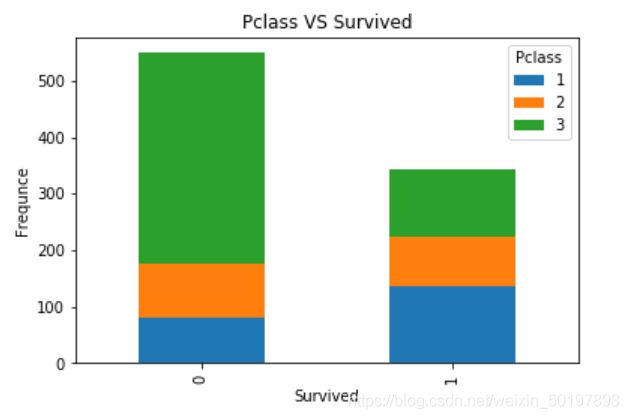
从图中可看到,1等舱的生还率明显高。
类别变量和数值变量的相关性分析
类别变量和数值变量的相关性分析,我们使用分类汇总统计来分析Age年龄,Fare船票价格与目标变量的Survived之间的相关性,注:Age\Fare(数值型变量)、Survived(类别变量)。
#方法:对Survived进行汇总,然后统计生还和未生还两类乘客的Age均值差异。
# 先按Survived汇总,求Age和Fare的均值
train_data.groupby('Survived').agg({'Age':'mean','Fare':'mean'})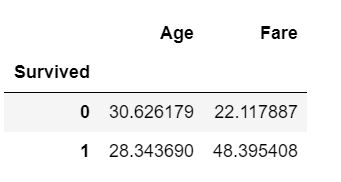
我们可以看到,是否生还和年龄的差异不是很大,但是与票价的差异较大,生还乘客的票价要高于未生还乘客的票价,也就是说生还乘客中1等舱的比例较多。
分类汇总结果的可视化
# 柱形图
data=train_data.groupby('Survived').agg({'Age':'mean','Fare':'mean'})
plt.figure(figsize=(12,5))
plt.subplot(121)
data.Age.plot(kind='bar')
plt.title('Age VS Survived')
plt.ylabel('Average')
plt.subplot(122)
data.Fare.plot(kind='bar')
plt.title('Fare VS Survived')
plt.ylabel('Average')
plt.show()
数据预处理:
数据预处理的主要目的是为建模进行的数据准备,数据准备的好坏对模型效果影响比较大。经常做的一些数据预处理工作有:
- 缺失值的处理
- 对类别型变量的值进行重新编码
- 把连续型变量进行分箱,然后再按照处理类别型变量的方式重新编码
- 对连续型变量进行标准化和归一化处理
删除缺失记录
# 删除整个数据集中任何一个变量有缺失的记录
dropna = train_data.dropna()
dropna.info() 
删除后只有183 条数据了,原数据有 891条,因此在这里不可以对整个数据集删除缺失值。于是我们需对指定的变量进行dropna()操作。
# 对Age变量删除缺失值,保存为一个新的变量
Age_dropna = train_data[['Age']].dropna()
Age_dropna.info()
构造缺失值标识变量
# 构造新的变量:Age_isna,当Age(年龄)是缺失值的时候Age_isna=1,没有缺失的时候Age_isna=0
train_data['Age_isna']=0
train_data.loc[train_data['Age'].isnull(),'Age_isna']=1
# 对Age_isna进行频数分析,确认Age_isna是否构造正确
train_data['Age_isna'].value_counts() 
替换缺失值(使用均值替换缺失值)
# 求均值(使用mean()计算Age的均值)
age_mean=round(train_data['Age'].mean())
# 对年龄缺失值进行均值填充
train_data['Age'].fillna(age_mean,inplace=True)
train_data.Age.describe()
独热编码
对类别变量重新编码,如:Pclass、Sex和Embarked,这里只演示Pclass的执行结果,对Sex和Embarked也可用类似的处理方法。
# 把 Pclass 进行独热编码,prefix 参数设置独热编码后的变量名前缀
Pclass_onehot = pd.get_dummies(train_data.Pclass,prefix='Pclass')
Pclass_onehot.head()
连续变量分箱操作
变量分箱有三种类型:◼ 自定义分箱 ◼ 等宽分箱 ◼ 等深分箱/等频分箱
如:对Age(年龄)进行分箱操作

自定义分箱
#对 Age 进行自定义分箱
cut_points = [0,18,25,40,60,100] # 定义分箱边界值
train_data['Age_bin'] = pd.cut(train_data.Age, bins=cut_points)#分箱后的新变量 Age_bin
train_data['Age_bin'].value_counts() # 分箱后的频数分析

等宽分箱
train_data['Age_wbin'] = pd.cut(train_data.Age,10) # 等宽分箱,分箱数为 10
train_data['Age_wbin'].value_counts() # 分箱后的频数分析
等深分箱
train_data['Age_dbin'] = pd.qcut(train_data.Age,5) # 等深分箱,分箱数为 5
train_data['Age_dbin'].value_counts() # 分箱后的频数分析
等深分箱的每一个箱内的数量应该是一样的,这里运行的结果看上去差别较多,是因为:30 岁的乘客比较多,且30岁是一个临界点,由于分箱必须要保证不重不漏,把30岁归入到(28.0, 30.0]这个箱的话,这个箱的样本数量就会比较多了。
分箱后的热度编码
分箱后得到的变量是类别型变量,因此可对类别型变量进行热度编码
# 对自定义分箱后的变量进行热度编码
Age_bin_onehot = pd.get_dummies(train_data.Age_bin,prefix='Age_bin')
Age_bin_onehot.head()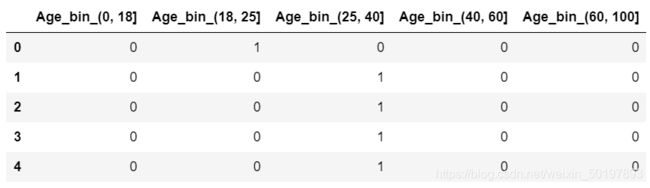
标准化和归一化
主要是为了调整样本数据每个维度的量纲,让每个维度数据量纲相同或接近可以进行比较。
- 标准化要做的事情就是把原始的连续型变量转换为均值为0,标准差为1 的变量。使用 sklearn.preprocessing.StandardScaler()来进行均值为 0,标准差为 1 的标准化
- 归一化就是把原始的连续型变量转换为范围在【a-b】之间的变量,常见的a=0,b=1。使用 sklearn.preprocessing.MinMaxScaler()来进行[0-1]之间的归一化
标准化:
# 标准化 先导入包
from sklearn import preprocessing
# 对Age标准化处理后保存为原数据对象中的新变量:Age_std
train_data['Age_std']=preprocessing.scale(train_data[['Age']])
# 标准后的数据
train_data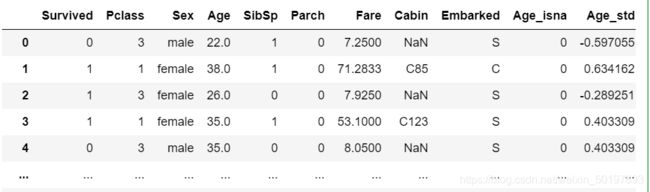
标准化的检验:
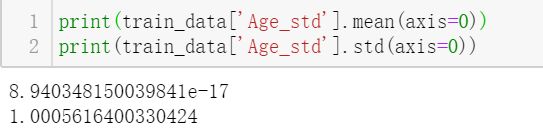
均值逼近于0,标准差逼近于1.
归一化:
from sklearn import preprocessing
minmaxscaler=preprocessing.MinMaxScaler() # 获取最大值和最小值
minmaxscaler.fit(train_data[['Age']])
# Age 归一化处理后保存为新变量 Age_normal
train_data['Age_normal']=minmaxscaler.transform(train_data[['Age']])
train_data.head()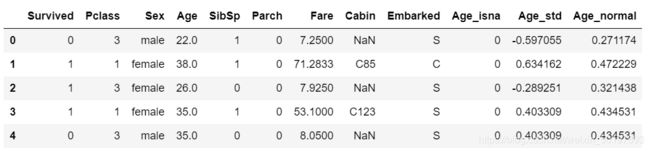
归一化的检验:

最大值为1 ,最小值为0。
(注意:标准化和归一化只选择其中一种方法即可)
特征变量的构造与组合
变量的构造比较重要,有句话是这样说的:数据决定了模型的上限, 算法只不过是无限逼近这个上限而已,由此可见特征构造的重要性,也就是说对机器学习来说重要的步骤不是选择哪个算法,而是能否构造出对目标变量有强相关性的变量,根据已有变量构造新的衍生变量一般有如下构造方法:
- 多个变量之间的数学运算,例如构造一个新变量 z=a/b
- 基于逻辑判断来构造衍生变量,形如 SQL 中的 case when ... then ...这样的方式
- 多个特征变量进行组合,例如性别,年龄本来是两个独立的变量,可以把他们组合起来变成新的独 热编码变量:男&(0,18],男&(18,25]...
基于多个变量的运算构造新变量(目标变量不变动)
SibSp和Parch数据
- SibSp:在船兄弟姐妹数/配偶数量
- Parch:在船父母数/子女数
两个都归属于直系亲属,且都是一个家庭的成员,我们发现:SibSp+Parch+乘客本人,这个新变量可以创建成家庭人数(FamilySize)的特征
# 构造新变量 FamilySize (类别型变量)
train_data['FamilySize']=train_data['SibSp']+train_data['Parch']+1
train_data.head(5)
通过前面使用过的分析方法来判断新的变量(FamilySize)与是否生还有一定的相关性。
# 使用交叉表分析FamilySize与Survived之间的相关性
pd.crosstab(train_data.Survived,train_data.FamilySize,margins=True)
# 按列统计交叉表百分比
# FamilySize与Survived的交叉表,显示列占比
pd.crosstab(train_data.Survived,train_data.FamilySize).apply(lambda r:r/r.sum(),axis=0)

通过交叉表我们得到:新变量FamilySize与Survived有一定的关系,一个人上船的人数比较多,他们的生还率在 30%左右,家庭成员为 2 个的生还率上升到 55%,3 个家庭成员的生还率为 58%,4 个家庭成员则达到了 72%左右。
基于逻辑判断来构造新的变量
1、构造一个新变量 IsAlone(是否是独自一个人登船),判断逻辑:如果 FamilySize=1,那么 IsAlone=1,否则 IsAlone=0
train_data['IsAlone']=0 # 构造新的变量,赋值为0
train_data.loc[train_data['FamilySize']==1,'IsAlone']=1 # 变量FamilySize=1时,用1替换原来给IsAlone赋的值 0
train_data['IsAlone'].value_counts() # 查看变量IsAlone的频数
2、构造一个新变量 IsMother(是否是母亲),判断逻辑:如果性别是女性,同时父母/子女数大于 0,并且年龄大于 20 岁,那么 IsMother=1,否则 IsMother=0
train_data['IsMother'] = 0 # 构造新变量 IsMother,赋值为 0
train_data.loc[(train_data['Sex']=='female') & (train_data['Parch']>0) &(train_data['Age']>20),'IsMother'] = 1
train_data['IsMother'].value_counts() # 频数统计
多个特征变量的组合
对Sex(性别)和Age_bin(年龄分箱)两个类别变量进行组合
# 对Sex和Age_bin进行组合,得到新的变量 Sex_Age_combo
train_data['Sex_Age_combo'] = train_data['Sex'] + "_" +train_data['Age_bin'].astype(str)
train_data['Sex_Age_combo'].value_counts() # 新变量Sex_Age_combo 的频数 
对新变量Sex_Age_combo进行独热编码
# 对变量 Sex_Age_combo 进行独热编码
Sex_Age_combo_onehot=pd.get_dummies(train_data['Sex_Age_combo'],prefix='Sex_Age')
Sex_Age_combo_onehot.head()
拼接需要的变量
最后我们将处理后的train文件中的数据集进行拼接,将需要的变量拼接在一起
# 把需要的变量拼接起来
TrainData=pd.concat([train_data[['Survived','Age_isna','IsAlone','IsMother']],Pclass,Sex,Embarked,AgeBin,FareBin,FamilySize,SexAgeCombo],axis=1)
TrainData.describe().transpose() # 描述性统计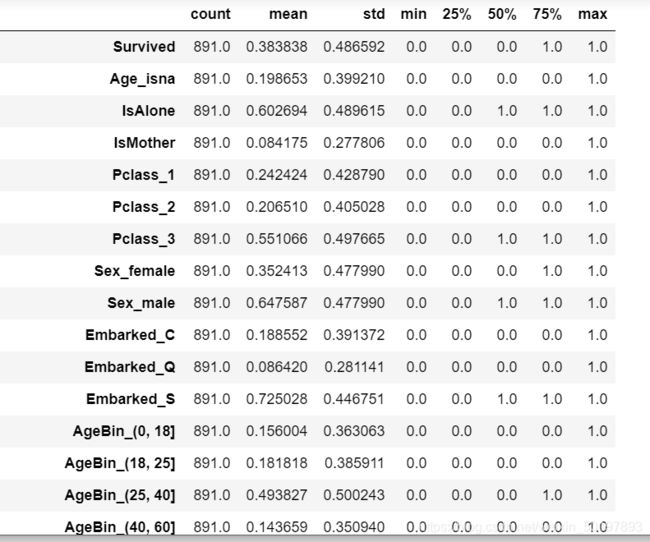
TrainData.shape
# 运行结果:(891, 41)最后我们得到了一个有891条数据,41个变量的新表TrainData,将处理好的数据保存下来,文件名为:processed

模型训练
加载处理好的训练数据,并将目标变量和特征变量分离开,其中 trainData_X:特征变量,trainData_y:目标变量
trainData=pd.read_csv("Desktop\泰坦尼克号\processed.csv")
trainData.head()
trainData_X=trainData.drop(['Survived'],axis=1)
trainData_y=trainData.Survived在训练模型时我们不能将所有的数据全部用于训练模型,因为我们还需要部分数据对建立的模型进行验证,故需要将数据分为训练集和测试集,对于这一问题我们可以使用数据交叉验证这一方法来解决。

train: 训练集数据 test:测试集数据
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(trainData_X,trainData_y,test_size=0.3,random_state=123456)
逻辑回归算法(Logistic Regression)与模型评估:
# 逻辑回归算法
from sklearn.linear_model import LogisticRegression
LR = LogisticRegression()
LR.fit(train_x, train_y) # 训练集 (训练模型)
# 模型评估 (测试集)
from sklearn.metrics import classification_report
y_test_pred = LR.predict(test_x) # y_test_pred是预测的结果
print(classification_report(test_y,y_test_pred)) # 评估模型(真实的值与预测的结果对比)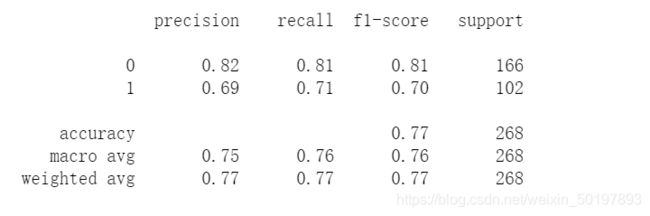
从模型的评估中我们可以得到准确率(precision)、召回率(recall)、f1值(f1-score),且该模型预测的正确率为77%。
模型在达到我们期望的情况下,可将训练好的模型对test.csv数据集进行预测,对test.csv处理的流程首先是将test.csv数据集加载进去,然后对数据集做类似于train.csv的处理,不过此时不需要将字段PassengerId去掉,因为预测的结果需要与PassengerId对应起来,最后将处理好的数据集放在模型中进行预测,即可得到测试结果。