Tensorflow基于卷积神经网络(CNN)的手写数字识别
一、简介
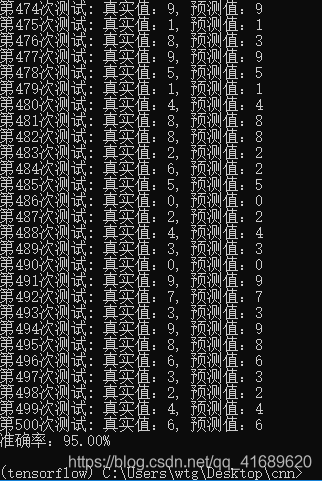
本项目在Tensorflow平台下利用卷积神经网络(CNN)实现了对mnist数据集(28*28)的手写数字图片的识别,通过5000*50个样本训练后,对500个样本进行测试,准确率可以达到95%左右。本文完整代码:https://github.com/iapcoder/cnnMnistRecognition。
二、mnist数据集简介
MNIST(Mixed National Institute of Standards and Technology database)是一个计算机视觉数据集,该数据集被分为两部分:60000行训练数据集和10000行测试数据集,其中训练集拆分为55000行训练集和5000行验证集。该数据集共70000张手写数字灰度图片,其中每一张图片为28*28个像素点,其中数字的范围为0-9,每张图片都有一个对应图片上数字的标签 。
60000行数据的训练集是一个形状为[60000, 784]的张量。在张量里的每一个元素都表示某张图片某个像素点的强度值,其值为0-1之间。

60000行训练集的标签采用One-hot编码表示,比如数字2表示只在第2维度(从0开始)为1其他维度为0 的10维向量([0 0 1 0 0 0 0 0 0 0]),因此标签是一个[60000, 10]的矩阵。

三、卷积神经网络结构介绍
神经网络(neural networks)的基本组成包括输入层、隐藏层、全连接层和输出层。而卷积神经网络的特点在于隐藏层分为卷积层、激励层和池化层。通过卷积神经网络的隐藏层可以减少输入的特征,其过程可以形象地描述为:

各层的作用
- 输入层:用于将数据输入到训练网络
- 卷积层:使用卷积核提取特征
- 激励层:对线性运算进行非线性映射,解决线性模型不能解决的问题
- 池化层:对特征进行稀疏处理,目的是减少特征数量
- 全连接层:在网络末端恢复特征,减少特征的损失
- 输出层:输出结果
1. 输入层
输入层的数据不限定维度,mnist数据集中是28*28的灰度图片,因此输入为[28, 28]的二维矩阵。
2.卷积层
卷积层使用卷积核即过滤器来获取特征,这里需要指定过滤器的个数、大小、步长及零填充的方式,其工作方式如下图:
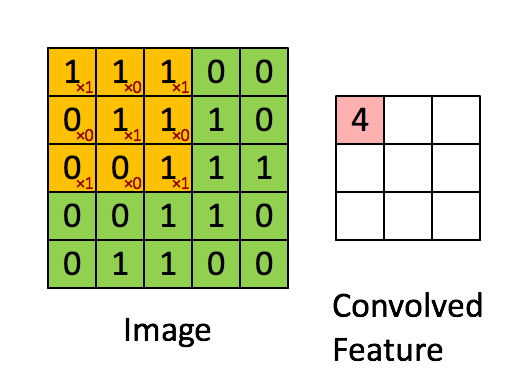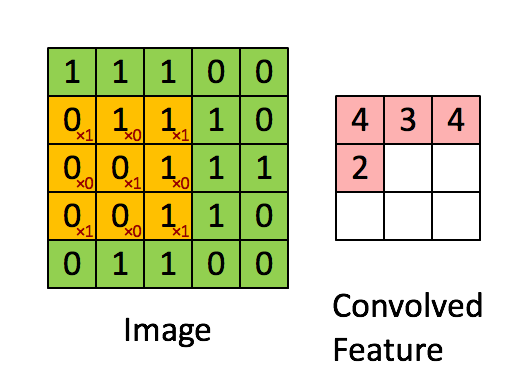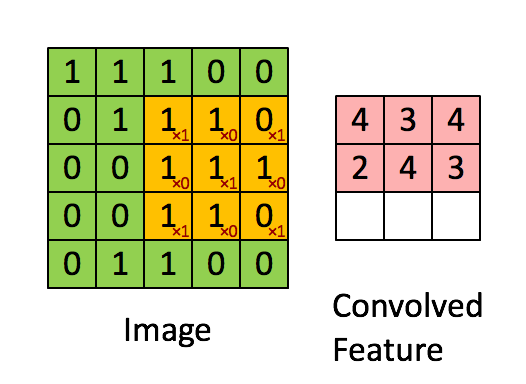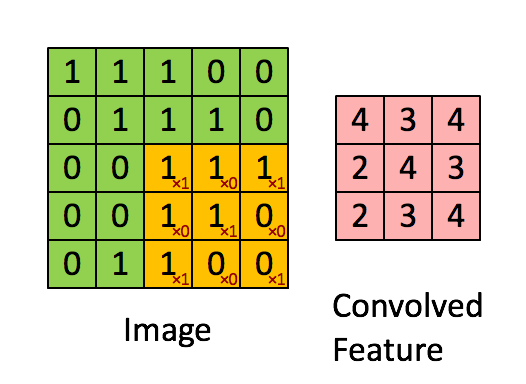
卷积操作的特征图的输出大小为:
 下面池化操作的输出大小也是该公式。
下面池化操作的输出大小也是该公式。
3.激励层
激励层是神经网络的关键,有了激活函数就可以解决一些复杂的非线性问题,卷积神经网络常用的激活函数是Relu函数: 。
。
4.池化层
池化层的主要目的是特征提取,Feature Map去掉不重要的样本,进一步减少参数数量,池化层常用的方法是Max Pooling。

5.全连接层
前面的卷积和池化相当于是特征工程,全连接相当于是特征加权,在整个神经网络中起到“分类器”的作用。
6.输出层
输出层表示最终结果的输出,该问题是个十分类问题,因此输出层有10个神经元向量。
模型结构:
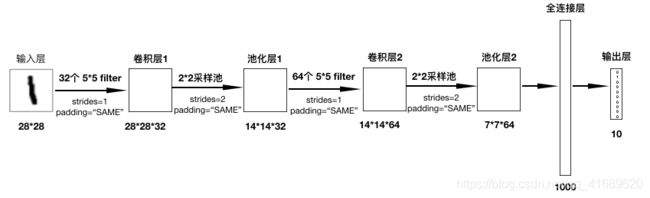
四、代码实现
1.准备数据占位符
with tf.variable_scope("data"):
x = tf.placeholder(tf.float32, [None, 784])
y_true = tf.placeholder(tf.int32, [None, 10])2. 第一层卷积网络, 卷积:32个5*5filter,激活:tf.nn.rule,池化
with tf.variable_scope("conv1"):
# 随机初始化权重,偏置 32
w_conv1 = weight_varialbles([5,5,1,32])
b_conv1 = bias_variables([32])
# 对x进行形状改变[None, 784] [None, 28, 28, 1]
x_reshape = tf.reshape(x, [-1, 28, 28, 1])
# [None, 28, 28, 1] ------> [None, 28, 28, 32]
x_relu1 = tf.nn.relu(tf.nn.conv2d(x_reshape, w_conv1, strides=[1,1,1,1], padding="SAME") + b_conv1)
# 池化 2*2, strides2 [None, 28, 28, 32]---->[None, 14, 14, 32]
x_pool1 = tf.nn.max_pool(x_relu1, ksize=[1,2,2,1], strides=[1,2,2,1], padding="SAME")
3.第二层卷积网络,卷积:64个5*5filter,激活:tf.nn.relu,池化
with tf.variable_scope("conv2"):
# 随机初始化权重 权重:[5,5,32,64] 偏置[64]
w_conv2 = weight_varialbles([5,5,32,64])
b_conv2 = bias_variables([64])
# 卷积 激活 池化计算
# [None, 14, 14, 32]----->[None, 14, 14, 64]
x_relu2 = tf.nn.relu(tf.nn.conv2d(x_pool1, w_conv2, strides=[1,1,1,1], padding="SAME")+b_conv2)
# 池化 2*2, strides 2, [None, 14, 14, 64]---->[None, 7, 7, 64]
x_pool2 = tf.nn.max_pool(x_relu2, ksize=[1,2,2,1], strides=[1,2,2,1], padding="SAME")
4.全连接层
with tf.variable_scope("full_connection"):
# 随机初始化权重和偏置
w_fc = weight_varialbles([7*7*64, 1000])
b_fc = bias_variables([1000])
# 修改形状[None, 7, 7, 64]--->[None, 7*7*64]
x_fc_reshape = tf.reshape(x_pool2, [-1,7*7*64])
# 非线性映射到1000维向量
x_fc = tf.nn.relu(tf.matmul(x_fc_reshape, w_fc) + b_fc)5.输出层
with tf.variable_scope("Out_result"):
w_out = weight_varialbles([1000,10])
b_out = bias_variables([10])
# 进行矩阵运算得出每个样本的10个结果
y_predict = tf.matmul(x_fc, w_out) + b_out6.将数据送入模型,开启会话训练
def conv_fc():
# 1.获取真实数据
mnist = input_data.read_data_sets("./data/mnist/input_data", one_hot=True)
# 2.定义模型,得出输出
x, y_true, y_predict = model()
# 3.进行交叉熵损失计算
with tf.variable_scope("soft_cross"):
# 求平均交叉熵损失
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_true, logits=y_predict))
# 4.梯度下降求出损失
with tf.variable_scope("optimizer"):
train_op = tf.train.GradientDescentOptimizer(0.0001).minimize(loss)
# 5.计算准确率
with tf.variable_scope("acc"):
equal_list = tf.equal(tf.argmax(y_true, 1), tf.argmax(y_predict, 1))
accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32))
# 定义一个初始化变量的op
init_op = tf.global_variables_initializer()
# 开启会话运行
with tf.Session() as sess:
sess.run(init_op)
# 循环训练
for i in range(10000):
# 取出真实存在的特征值和目标值
mnist_x, mnist_y = mnist.train.next_batch(50)
# 运行train_op训练
sess.run(train_op, feed_dict={x:mnist_x, y_true:mnist_y})
print("训练%d步,准确率为:%f"%(i+1, sess.run(accuracy, feed_dict={x:mnist_x, y_true:mnist_y})))
五、训练5000步,每次训练50个样本,得出训练集准确率可以达到96%左右
python cnn_mnist_recognition.py --is_train=True
保存训练的模型,对500个样本进行测试,得出准确率可以达到95%左右
python cnn_mnist_recognition.py --is_train=False