TCP 加速小记
都说 BBR 比 CUBIC,但 CUBIC 究竟差在哪儿?看下图理解一下 CUBIC 为什么不抗丢包:
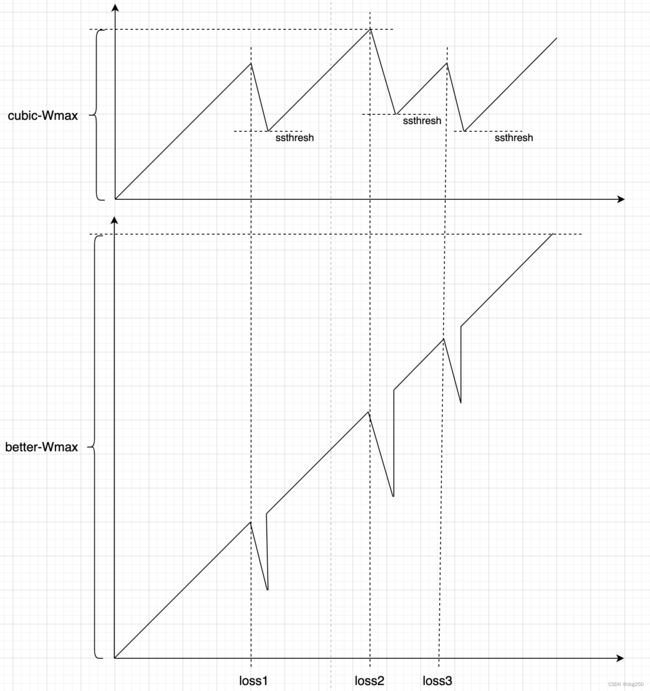
CUBIC 遭遇丢包后无条件 MD,此后从新的 ssthresh 处开始 AI,CUBIC 认为丢包一定是拥塞导致的 buffer overflow 引起的。事实上并不一定。
25 Gbps * 50us 链路,5% 丢包率,吞吐下降到 300 Mbps,原因正如上图所示,链路越长,问题越严重。
如何优化呢?
常规思路是丢包不降窗或少降窗,但没有直指核心。核心不是丢包后降窗,相反,丢包降窗和数据包守恒无论如何都是必须的策略(范雅各布森守恒率:只要每个数据包在网络上只有一个副本,就不会拥塞崩溃),问题的核心在于丢包恢复后,本应 undo 却没有 undo。
只要是随机非拥塞丢包,都应执行完全 undo 动作。
如何判定是非拥塞丢包?
这里有个 10 行代码方案,不复杂但有效。改 tcp_cubic.c,重命名 cc name 为 cubic2,修改 pkts_acked/set_state 回调:
// 增加 currRTT,minRTT 字段,冒泡跟踪 minRTT,实时更新 currRTT。
static void bictcp_acked(struct sock *sk, const struct ack_sample *sample)
{
const struct tcp_sock *tp = tcp_sk(sk);
struct bictcp *ca = inet_csk_ca(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
u32 delay;
/* Some calls are for duplicates without timetamps */
if (sample->rtt_us < 0)
return;
if (icsk->icsk_ca_state < TCP_CA_Recovery)
ca->currRTT = sample->rtt_us;
ca->minRTT = min(ca->minRTT, sample->rtt_us);
/* Discard delay samples right after fast recovery */
...
}
static void bictcp_state(struct sock *sk, u8 new_state)
{
struct tcp_sock *tp = tcp_sk(sk);
struct bictcp *ca = inet_csk_ca(sk);
if (new_state == TCP_CA_Loss) {
bictcp_reset(inet_csk_ca(sk));
bictcp_hystart_reset(sk);
}
if (new_state == TCP_CA_Open) {
// int gamma = 3;
// module_param(gamma, int, 0644);
// MODULE_PARM_DESC(gamma, "gamma");
if (ca->currRTT < gamma*ca->minRTT) {
tp->snd_cwnd = max(tp->snd_cwnd, tp->prior_cwnd);
tp->snd_ssthresh = tp->prior_ssthresh;
tp->snd_cwnd_stamp = tcp_jiffies32;
tp->undo_marker = 0;
tp->rack.advanced = 1;
} else {
printk("un-undo %d to %d min:%d curr:%d srtt:%d\n",
tp->snd_cwnd,
tp->prior_cwnd,
ca->minRTT,
ca->currRTT,
tp->srtt_us);
}
}
}
我只记录 Open 和 Disorder 状态下的 currRTT,事实上我已有办法在 Recovery 状态精确测量 RTT,但为了每日一 tip,就没将它们关联在一起。
代码意思是,丢包时如果 currRTT 没有比 minRTT 大太多(代码里是 5 倍,可调,如果 minRTT 本就很小,gamma 显然就不要这么大了,2 足矣),就判定为随机丢包,全部 undo。
到底 currRTT,minRTT,srtt_us 要保持一个什么关系才判定为随机丢包,可说的很复杂,也可简单粗暴,还是要结合实际效果来调参,至于链路 AQM QoS策略,只能猜测。
BBR 用实际测量的 maxbw, minrtt 指导 pacing rate, cwnd 计算,CUBIC 同样可用 minRTT,currRTT,srtt_us,半程抖动等更简单地指导 undo。总之是充分利用测量的信息来启发未来动作。
至于 minRTT 是否精确,一行代码肯定不精确,万一路由重收敛了就有必要重测。也不能完全学 BBR,那就变成 BBR 了,最简单的办法还是全局冒泡。
大概 10 行代码,完成一个启发式 undo。看看效果:
[ 4] 0.0-100.7 sec 3.16 GBytes 270 Mbits/sec # cubic
[ 5] 0.0-101.0 sec 49.1 GBytes 4.18 Gbits/sec # cubic2
[SUM] 0.0-101.0 sec 52.3 GBytes 4.45 Gbits/sec
重传率:
cubic bytes_sent:3565663872 bytes_retrans:177562484 重传/传输:0.0497
cubic2 bytes_sent:55514372396 bytes_retrans:2773832160 重传/传输:0.0499
并没有由于 undo 造成激进丢包而增加重传率,相对还是精准的,并没有以重传率换吞吐。
最后我们看绝大多数场景下 BBR 比 CUBIC 吞吐更好的核心原因,其实就是 BBR 的 undo 做得好。BBR 卯足了劲憋住 10 rounds 内的 maxbw 重复使用,并在丢包恢复后直接 undo 到该 maxbw 和 prior cwnd,这就是它效果的原因。
回到 CUBIC,结合前些天的那些小 tips,如半程抖动测量,Recovery 状态 RTT 精确测量,还可以对随机非拥塞丢包判断更精确,但今天就先这样了。
等了几天的雨还是没下,今年雨带在华南滞留太久了,以至于爽约了江南梅雨季,以往华南龙舟水后接着就是江南梅雨季了,然后是华北,东北。今年雨带在华南不走了。这天气搞不来太复杂的,等下雨吧。简单小记。
浙江温州皮鞋湿,下雨进水不会胖。