Dubbo场景场景配置用法详解
前言
对Dubbo常用的场景详解以及配置说明。
dubbo配置来源有 JVM参数、外部配置、api配置(xml配置,注解配置)、属性文件配置。优先级从高到低,这点是前提。
启动时检查
Dubbo会在启动时默认检查所有依赖的服务是否可以正常访问(是否可用),不可用时会抛出异常,阻止spring初始化完成。以便上线时能及早发现问题。
但是在一些场景:
比如测试时、有些不关心的服务依赖可以关闭启动时检查。
服务之间出现依赖循环时(必须要一个服务先启动),还有如果spring容器的服务是延时加载的,或者通过API编程延时引用服务时,必须要关闭启动时检查。否则会找不到服务错误,阻止spring初始化完成。
关闭检查的方法:
对应的api配置。
对应的属性配置。
对应的@reference注解的属性配置。
对应的JVM启动参数配置。
外部配置中心的相应属性配置。
优先级情况是,不管是属性配置、xml配置、api、外部啥的,首先第一优先级是服务级别的check配置,也就是
基础环境:
![]()
//启动类
public class OrderConsumer {
public static void main(String[] args) {
//使用order-consumer.xml配置文件创建容器并初始化
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("order-consumer.xml");
//获取orderService bean
OrderService orderService = (OrderService) context.getBean("orderService");
System.out.println("spring初始化完成");
try {
System.in.read();
} catch (IOException e) {
e.printStackTrace();
}
}
}
![]()
以上是启动时默认检查依赖服务是否可用,因为服务提供者还没启动,所以抛出异常,阻止spring初始化完成。
关闭启动时检查:通过check属性关闭。
![]()

启动成功了。
集群容错
在集群调用失败时,Dubbo 提供了多种容错方案,缺省为 failover 重试。
Dubbo默认包含6中集群容错方式,但是可以自行扩展。
配置方式:
优先级由上到下,以客户端服务引用标签的优先级较高。服务级别的优先级比应用级别的优先级高。相对应的其他配置来源要在这个为前提下。
六种集群模式如下:
Failover Cluster :失败自动切换,当出现调用失败时,重试集群中其他节点,通常用于读操作(幂等操作),可以通过retries属性配置重试次数,不包括第一次,retries属性默认值为2,也就是默认会进行三次服务的调用,第一次调用负载均衡到的服务器,失败后调用其他节点,再次失败后就调用另外节点,三次失败后返回给客户端调用错误信息。可以使用
通过 cluster = “failover” 配置,可以直接不配置,因为这个是默认的集群容错方式。
Failfast Cluster:快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增、修改、删除记录操作。通过cluster = "failfast"配置。
Failsafe Cluster: 失败安全,出现异常时,直接忽略,通常用于日志审计记录等方面。
Failback Cluster:失败自动恢复,后台记录失败请求,定时重发,通常用于消息通知操作。
Forking Cluster:并行调用多个集群中的节点,也就是同时向这些节点发送同一请求,只要一个成功即返回,通常用于实时性要求较高的读操作,但需要浪费更多服务资源。因为每个服务节点都要执行该请求。但是实际上一台成功就行。可通过 forks=“2” 属性来设置最大并行数。
Broadcast Cluster: 广播所有服务节点提供者,逐个调用,任意一台报错则报错 。通常用于通知所有提供者更新缓存或日志等本地资源信息。但是不提供分布式事务功能,也就是说,假如调用前2台节点成功,更新缓存或日志等本地资源信息,但是调用第三台时报错,直接返回错误信息,后面的服务节点不再调用,但是前面那两台提供者的缓存或者日志等信息已经更新了,不会自动进行回滚,这就会导致多个提供者的状态不一致。
负载均衡
在集群负载均衡时,Dubbo 提供了多种均衡策略,缺省为 random 随机调用。
Dubbo默认提供了4种负载均衡的策略,也可以自己实现策略。
配置方式:
优先级由上到下,客户端的优先级比提供方要高,但是这个属性让提供方提供比较好,因为提供方更加清楚自己发布的服务的性能,能更好的进行调控。
四种负载均衡策略:
Random LoadBalance :
随机,按权重设置随机概率,可能会在一些情况下导致资源分配不均匀,因为是随机,所以可能会出现多次随机到同一节点的情况下。但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。
RoundRobin LoadBalance:
轮询,按照权重设置轮询比例,存在慢的提供者累积请求的问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。
LeastActive LoadBalance:
最小活跃调用数,这里的活跃数指调用前后计数差。也可以认为那台节点的性能,相同活跃数的节点进行随机调用,使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。
ConsistentHash LoadBalance:
一致性哈希,相同参数的请求总是发到同一提供者。当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。
默认只会对第一个参数进行哈希计算,如果要修改,可以通过节点
默认有160个虚拟节点,也就是能为160台挂掉的提供者进行一致性哈希容错,可以通过标签:
线程模型
Dubbo有两种线程,一种是用于接收请求并进行分发和对请求结果进行响应的IO线程,另外一种是进行业务请求处理的业务线程,IO线程接收到请求后就是分配到这些线程中处理。
如果事件处理的逻辑能迅速完成,并且不会发起新的 IO 请求,比如只是在内存中记个标识,则直接在 IO 线程上处理更快,因为减少了线程池调度。
但如果事件处理逻辑较慢,或者需要发起新的 IO 请求,比如需要查询数据库,则必须派发到线程池,否则 IO 线程阻塞,因为IO线程一般设置的非常有限的,将导致不能接收其它请求。
因此,需要通过不同的派发策略和不同的线程池配置的组合来应对不同的场景:
通过
all :所有消息都派发到线程池,包括请求,响应,连接事件,断开事件,心跳等。
direct:所有消息都不派发到线程池,全部在 IO 线程上直接执行。
message :只有请求响应消息派发到线程池,其它连接断开事件,心跳等消息,直接在 IO 线程上执行。
execution:只有请求消息派发到线程池,不含响应,响应和其它连接断开事件,心跳等消息,直接在 IO 线程上执行。
connection:在 IO 线程上,将连接断开事件放入队列,有序逐个执行,其它消息派发到线程池。
通过
fixed:固定线程池大小。启动时建立线程,不关闭,一直持有。(默认)
cached:缓存线程池,空闲一分钟自动删除,需要时重建。这个也是固定大小的。
通过
通过
通过
直连提供者
在开发及测试环境下,经常需要绕过注册中心,只测试指定服务提供者,这时候可能需要点对点直连,点对点直连方式,将以服务接口为单位,忽略注册中心的提供者列表,A 接口配置点对点,不影响 B 接口从注册中心获取列表。
进行点对点相连的配置方式:
-
使用启动参数指定,优先级最高。
-Dstudy.dubbostudy.orderapi.service.OrderService=dubbo://localhost:20880
语法是-D服务名=地址 -
使用映射文件(properties文件),其中 key 为服务名,value 为服务提供者 URL:
study.dubbostudy.orderapi.service.OrderService=dubbo://localhost:20880
然后使用启动参数指定映射文件。映射文件可以配置多个服务直连。
-Ddubbo.resolve.file=文件路径 -
使用标签
以上三种方式优先级从高到低。
示例其中一种

没有配置注册中心,也没有配置直连时。

使用参数配置直连。

结果:
![]()
直连调用成功。
十分不建议在线上使用点对点直连的方式处理服务间的依赖,因为依赖多、复杂起来时,将会导致维护噩梦,应该使用注册中心维护服务之间的依赖关系。
只订阅
为方便开发测试,经常会在线下共用一个所有服务可用的注册中心,这时,如果一个正在开发中的服务提供者注册,可能会影响消费者不能正常运行。
比如Dubbo服务提供者A在开发一个新的功能服务,但是他的消费者可能会依赖该提供者的已存在的旧服务,此时如果正在开发的新服务进行注册到注册中心的话,可能会影响消费者对已有旧服务功能的使用。
可以让服务提供者开发方,对新开发的服务,只进行订阅服务(新服务可能也会依赖其他服务提供者),而不注册正在开发的服务,然后通过直连测试正在开发的服务。
配置方式:
可以通过:
没有优先级之分,只要有一个为false就不会注册。
只注册
这是在多注册中心的场景下,有服务S,有注册中心A、B,注册中心A的服务S1和S2依赖服务S,注册中心B的服务S3、S4依赖服务S,但是服务S只在注册中心A有部署,在注册中心B还没来得及部署,此时可以让服务S1、S2、S3、S4在注册中心A中注册和定义服务,在注册中心B中只注册服务,不订阅服务。
通过设置subscribe=false实现。
//
<dubbo:registry id="ARegistry" address="10.20.153.10:9090" />
<dubbo:registry id="BRegistry" address="10.20.141.150:9090" subscribe="false" />
多协议
Dubbo常用协议之Dubbo协议与Hessian协议解析
多注册中心
Dubbo 支持同一服务向多注册中心同时注册,或者不同服务分别注册到不同的注册中心上去,甚至可以同时引用注册在不同注册中心上的同名服务。 。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd">
<dubbo:application name="world" />
<!-- 多注册中心配置 -->
<dubbo:registry id="hangzhouRegistry" address="10.20.141.150:9090" />
<dubbo:registry id="qingdaoRegistry" address="10.20.141.151:9010" default="false" />
<!-- 向多个注册中心注册 -->
<dubbo:service interface="com.alibaba.hello.api.HelloService" version="1.0.0" ref="helloService" registry="hangzhouRegistry,qingdaoRegistry" />
</beans>
多注册中心引用:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd">
<dubbo:application name="world" />
<dubbo:registry id="chinaRegistry" address="10.20.141.150:9090" />
<dubbo:registry id="intlRegistry" address="10.20.154.177:9010" default="false" />
<dubbo:reference id="chinaHelloService" interface="com.alibaba.hello.api.HelloService" version="1.0.0" registry="chinaRegistry" />
<dubbo:reference id="intlHelloService" interface="com.alibaba.hello.api.HelloService" version="1.0.0" registry="intlRegistry" />
</beans>
多版本
当一个接口实现,出现不兼容升级时,可以用版本号过渡,版本号不同的服务相互间不引用。
比如某APP需要新版本的迭代,并且版本间不兼容,如果直接在原服务上修改,就会导致用户未升级的APP客户端不兼容。使得用户必须升级客户端才能继续使用服务。
如果用版本号来区分,保留原版本,新增新版本并打上新的版本号,新客户端引用新版本,老客户端引用就版本。就不会导致旧客户端不兼容的情况。
使用version属性来指定版本号。
老版本服务提供者:
<dubbo:service interface="com.foo.BarService" version="1.0.0" />
新版本服务提供者:
<dubbo:service interface="com.foo.BarService" version="2.0.0" />
老版本服务消费者(老客户端)
<dubbo:reference id="barService" interface="com.foo.BarService" version="1.0.0" />
新版本服务消费者(新客户端)
<dubbo:reference id="barService" interface="com.foo.BarService" version="2.0.0" />
服务分组
当一个接口有多种实现时,可以用 group (组)区分。
比如:
服务提供者

服务消费者

结果:
![]()
![]()
不同实现的输出不一样。
参数验证
参数验证功能是基于 JSR303 实现的,用户只需标识 JSR303 标准的验证 annotation。
所需依赖:
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-servlet</artifactId>
<version>9.4.28.v20200408</version>
</dependency>
<dependency>
<groupId>javax.validation</groupId>
<artifactId>validation-api</artifactId>
<version>1.0.0.GA</version>
</dependency>
@Data
public class DoOrderRequestWrapper implements Serializable{
private static final long serialVersionUID = -6533746694955013108L;
//非null验证
@NotNull
private String name;
}

validation = "true"开启参数验证。
消费者引用服务:(消费者提供者都要添加依赖)

不设置name值,让他为空。
结果:
![]()
第一个服务没有开启参数验证,所以执行成功。

第二个服务开启了参数非空验证,但是传去空值,所以抛出异常。
结果缓存
结果缓存 ,用于加速热门数据的访问速度,Dubbo 提供声明式缓存,以减少用户加缓存的工作量 。
以调用参数为key,缓存返回结果。
这种缓存如果没有加特殊处理的话,是会读到脏数据的,所以如果数据经常变化或者对数据的实时性要求高的话不太适用于这种方法。
配置方式:
优先级从高到低。
缓存的种类:
lru 基于最近最少使用原则删除多余缓存,保持最热的数据被缓存。
threadlocal :当前线程缓存,每个线程的缓存是使用ThreadLocal副本隔离的。
示例:
服务提供者:
![]()
服务消费者:
![]()
消费方法:
public class OrderConsumer {
public static void main(String[] args) throws InterruptedException, IOException {
//使用order-consumer.xml配置文件创建容器并初始化
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("order-consumer.xml");
//获取orderService bean
OrderService orderService = (OrderService) context.getBean("orderService");
DoOrderRequestWrapper requestWrapper = new DoOrderRequestWrapper();
requestWrapper.setName("YeHaocong");
//调用远程服务
//第一次调用
DoOrderResponseWrapper responseWrapper = orderService.doOrder(requestWrapper);
System.out.println(responseWrapper);
//修改参数进行第二次调用
TimeUnit.SECONDS.sleep(5);
requestWrapper.setName("YeHaoxian");
DoOrderResponseWrapper wrapper1 = orderService.doOrder(requestWrapper);
System.out.println(wrapper1);
//把参数改回来进行第三次调用
TimeUnit.SECONDS.sleep(5);
requestWrapper.setName("YeHaocong");
DoOrderResponseWrapper wrapper2 = orderService.doOrder(requestWrapper);
System.out.println(wrapper2);
System.in.read();
}
}
结果:
提供方:

消费方:

消费者发送了三个请求,其中第一个与第三个的参数一样,第二个不一样,提供方只打印了两个请求,原因是两个参数一样的请求,第二个时直接使用缓存,而实际上没有再次调用提供方服务。
回声测试
回声测试用于检测服务是否可用,回声测试按照正常请求流程执行,能够测试整个调用链是否通畅,可用于监控。
所有服务自动实现 EchoService 接口,只需将任意服务引用强制转型为 EchoService,即可使用。
//使用order-consumer.xml配置文件创建容器并初始化
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("order-consumer.xml");
//获取orderService bean
OrderService orderService = (OrderService) context.getBean("orderService");
EchoService echoService = (EchoService) orderService;
String status = (String) echoService.$echo("ok");
System.out.println("status====" + status);
![]()
上下文信息
上下文中存放的是当前调用过程中所需的环境信息。所有配置信息都将转换为 URL 的参数。
RpcContext 是一个 ThreadLocal 的临时状态记录器,当接收到 RPC 请求,或发起 RPC 请求时,RpcContext 的状态都会变化。比如:A 调 B,B 再调 C,则 B 机器上,在 B 调 C 之前,RpcContext 记录的是 A 调 B 的信息,在 B 调 C 之后,RpcContext 记录的是 B 调 C 的信息。
也就是说RpcContext 上下文信息是线程隔离的,实时记录着当前线程上下文信息状态,这个状态信息会随着该线程接收RPC请求或者发起RPC请求而变化。
例子:
public DoOrderResponseWrapper testRPCContext() {
//缓存当前线程的RPC上下文信息
RpcContext context = RpcContext.getContext();
//输出一些信息
System.out.println("当前RPC状态是否为调用端:" + context.isConsumerSide());
System.out.println("当前RPC状态是否为提供方端:" + context.isProviderSide());
System.out.println("当前RPC上下文的服务方法名:" + context.getMethodName());
System.out.println("当前RPC上下文的URL:" + context.getUrl());
//调用user提供者
userService.getUser("Yehaocong");
//输出调用后的一些信息
System.out.println("调用服务后RPC状态是否为调用端:" + context.isConsumerSide());
System.out.println("调用服务后RPC状态是否为提供方端:" + context.isProviderSide());
System.out.println("调用服务后RPC上下文的服务方法名:" + context.getMethodName());
System.out.println("调用服务后RPC上下文的URL:" + context.getUrl());
return new DoOrderResponseWrapper();
}
结果:

当调用user服务前,该服务为服务提供方,所以服务调用端输出为false,是否为服务提供方为true。
调用了user服务后,相应的上下文信息变为order服务调用user服务的信息。
当然RPCContext能获取的信息和能做的事情远不止这些。
提供端异步执行:
Provider端异步执行将阻塞的或者执行时间长业务从Dubbo内部线程池切换到业务自定义线程,避免Dubbo线程池的过度占用,有助于避免不同服务间的互相影响。假如dubbo线程池有300个线程,被执行时间较长的业务长时间占用了200个线程,那该Dubbo服务接收处理其他业务的线程实际上只有100个。将这些业务分离出来有助于不让阻塞或者执行时间长的业务影响普通业务的执行性能。
但是如果是执行时间较快的服务,不建议使用自定义线程来执行,因为线程的切换需要开销。
异步执行无益于节省资源或提升RPC响应性能,因为如果业务执行需要阻塞,则始终还是要有线程来负责执行。
实现:使用CompletableFuture签名的接口:
服务接口定义:
CompletableFuture<DoOrderResponseWrapper> doOrderAsync(DoOrderRequestWrapper param);
服务实现定义:
@Override
public CompletableFuture<DoOrderResponseWrapper> doOrderAsync(DoOrderRequestWrapper param) {
RpcContext rpcContext = RpcContext.getContext();
return CompletableFuture.supplyAsync(()->{
System.out.println(param.getName() + "异步创建了新订单(OrderServiceImpl)");
Integer orderId = 1002;
DoOrderResponseWrapper responseWrapper = new DoOrderResponseWrapper();
responseWrapper.setCode("30000");
responseWrapper.setData(orderId);
responseWrapper.setMsg("异步创建新建订单成功(OrderServiceImpl->doOrderAsync)");
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
return responseWrapper;
});
}
消费者调用:
public static void main(String[] args) throws InterruptedException, IOException {
//使用order-consumer.xml配置文件创建容器并初始化
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("order-consumer.xml");
//获取orderService bean
OrderService orderService = (OrderService) context.getBean("orderService");
DoOrderRequestWrapper requestWrapper = new DoOrderRequestWrapper();
requestWrapper.setName("YeHaocong");
//这一步是异步执行的
CompletableFuture<DoOrderResponseWrapper> future = orderService.doOrderAsync(requestWrapper);
//执行完成的回调
future.whenComplete((result,e)->{
if (e != null){
//异常不为空时代表调用抛出了异常
e.printStackTrace();
}else {
System.out.println("结果是:" + result);
}
});
System.out.println("这里会比回调函数先执行");
System.in.read();
这里使用了JDK公用线程池, 但是建议为supplyAsync提供自定义线程池,避免使用JDK公用线程池。

因为在服务实现里面把线程睡眠了5秒,所以在服务发布或者引用时要把超时时间设为5秒以上。
通过return CompletableFuture.supplyAsync(),业务执行已从Dubbo线程切换到业务线程,避免了对Dubbo线程池的阻塞。
消费端异步调用
从v2.7.0开始,Dubbo的所有异步编程接口开始以CompletableFuture为基础。需要服务提供者定义CompletableFuture返回值的服务。
基于 NIO 的非阻塞实现并行调用,客户端不需要启动多线程即可完成并行调用多个远程服务,相对多线程开销较小。
比如你在一个服务消费者中要调用多个服务。
比如在消费者方法中:
调用服务A。
调用服务B。
调用服务C。
如果让其串行执行的话,会性能低下,一个解决办法是开三个线程并行执行调用这三个服务。但是基于 NIO 的非阻塞实现并行调用,相对多线程开销较小。可以让服务A、B、C异步调用。
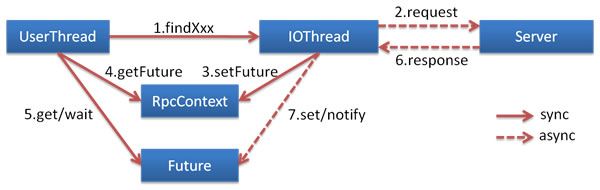
- 消费端发起服务调用。
- 提供方IO线程接收请求后派发给其他线程调用。
- IO线程设置Future到RPC上下文,然后立即返回给调用方。
- 调用方等待请求执行完成。
- 提供方执行完成返回响应给IO线程。
- IO线程设置Future并唤醒Future。
- 调用方获得数据。
实现消费端异步调用的方式:
第一种:提供方提供提供端异步执行的服务,服务端调用就是异步调用。具体参看上一个标题。
第二种:使用RpcContext:
服务实现是一个普通的同步服务。
服务实现:
public DoOrderResponseWrapper doOrder(DoOrderRequestWrapper param) {
System.out.println(param.getName() + "创建了新订单(OrderServiceImpl)");
Integer orderId = 100;
DoOrderResponseWrapper responseWrapper = new DoOrderResponseWrapper();
responseWrapper.setCode("30000");
responseWrapper.setData(orderId);
responseWrapper.setMsg("新建订单成功(OrderServiceImpl)");
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
return responseWrapper;
}
服务引用时把async属性设置为true,表示异步调用:

消费者调用服务:
//使用order-consumer.xml配置文件创建容器并初始化
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("order-consumer.xml");
//获取orderService bean
OrderService orderService = (OrderService) context.getBean("orderService");
DoOrderRequestWrapper requestWrapper = new DoOrderRequestWrapper();
requestWrapper.setName("YeHaocong");
//因为引用服务是async属性设置为true。所以这一步是异步调用的,因为返回的值是null值,所以这里就干脆不接收了
orderService.doOrder(requestWrapper);
CompletableFuture<DoOrderResponseWrapper> future = RpcContext.getContext().getCompletableFuture();
//执行完成的回调
future.whenComplete((result,e)->{
if (e != null){
//异常不为空时代表调用抛出了异常
e.printStackTrace();
}else {
System.out.println("结果是:" + result);
}
});
System.out.println("这里会比回调函数先执行");
System.in.read();
}
结果:

延迟暴露
如果你的服务需要预热时间,比如初始化缓存,等待相关资源就位等,可以使用 delay 进行延迟暴露。我们在 Dubbo 2.6.5 版本中对服务延迟暴露逻辑进行了细微的调整,将需要延迟暴露(delay > 0)服务的倒计时动作推迟到了 Spring 初始化完成后进行。你在使用 Dubbo 的过程中,并不会感知到此变化,因此请放心使用。
2.6.5版本前:
2.6.5版本及之后:
所有服务都将在 Spring 初始化完成后进行暴露,如果你不需要延迟暴露服务,无需配置 delay。
并发控制
//未完待续
连接控制
//未完待续
延迟连接
延迟连接用于减少长连接数。当有调用发起时,再创建长连接。
当有调用发起时,才建立长连接。
该配置只对使用长连接的 dubbo 协议生效。
粘带连接
粘滞连接用于有状态服务,尽可能让客户端总是向同一提供者发起调用,除非该提供者挂了,再连另一台。
所谓有状态服务是指你的调用在服务的集群的某个节点上做了一个缓存、标记啥的,其他节点是没有的,如果你之后被负载均衡到了其他节点,就获取不到该标记。
粘滞连接将自动开启延迟连接,以减少长连接数。
Dubbo 支持方法级别的粘滞连接,如果你想进行更细粒度的控制,还可以这样配置。
令牌验证
通过令牌验证在注册中心控制权限,以决定要不要下发令牌给消费者,可以防止消费者绕过注册中心访问提供者,另外通过注册中心可灵活改变授权方式,而不需修改或升级提供者。
设置方法:
应用级别:
<!--随机token令牌,使用UUID生成-->
<dubbo:provider interface="com.foo.BarService" token="true" />
<!--固定token令牌,相当于密码-->
<dubbo:provider interface="com.foo.BarService" token="123456" />
服务级别:
<!--随机token令牌,使用UUID生成-->
<dubbo:service interface="com.foo.BarService" token="true" />
<!--固定token令牌,相当于密码-->
<dubbo:service interface="com.foo.BarService" token="123456" />
服务级别的配置优先级高于应用级别。
例子:
服务提供者(设置固定token密码123456):
<dubbo:service group="Impl1" interface="study.dubbostudy.orderapi.service.OrderService"
ref="orderService" protocol="dubbo" token="123456"/>
服务消费者(使用url属性直连提供者):
<dubbo:reference group="Impl1" id="orderService" interface="study.dubbostudy.orderapi.service.OrderService" protocol="dubbo"
url="dubbo://10.8.0.174:20880">
结果:
![]()
可以看到验证失败。
其实只要在URL参数里面拼接正确的token,依然可以绕过注册中心直连提供者。
![]()
结果:
![]()
成功访问。
优雅停机
Dubbo 是通过 JDK 的 ShutdownHook 来完成优雅停机的,所以如果用户使用 kill -9 PID 等强制关闭指令,是不会执行优雅停机的,只有通过 kill PID 时,才会执行。
在Java程序中可以通过添加关闭钩子,实现在程序退出时关闭资源、平滑退出的功能。
使用Runtime.addShutdownHook(Thread hook)方法,可以注册一个JVM关闭的钩子,这个钩子可以在以下几种场景被调用:
- 程序正常退出
- 使用System.exit()
- 终端使用Ctrl+C触发的中断
- 系统关闭
- 使用Kill pid命令干掉进程
dubbo提供的钩子函数:
@Override
public void run() {
if (logger.isInfoEnabled()) {
logger.info("Run shutdown hook now.");
}
doDestroy();
}
/**
* Destroy all the resources, including registries and protocols.
* 这个是真正关闭资源的方法。
*/
public void doDestroy() {
if (!destroyed.compareAndSet(false, true)) {
return;
}
// destroy all the registries
AbstractRegistryFactory.destroyAll();
// destroy all the protocols
destroyProtocols();
}
如果 ShutdownHook 不能生效,可以自行调用,使用tomcat等容器部署的场景,建议通过扩展ContextListener等自行调用以下代码实现优雅停机:
DubboShutdownHook.doDestroy();
服务提供方的优雅停机:
- 停止时,先标记为不接收新请求,新请求过来时直接报错,让客户端重试其它机器。
- 然后,检测线程池中的线程是否正在运行,如果有,等待所有线程执行完成,除非超时,则强制关闭。
消费方的优雅停机:
- 停止时,不再发起新的调用请求,所有新的调用在客户端即报错。
- 然后,检测有没有请求的响应还没有返回,等待响应返回,除非超时,则强制关闭。
优雅停机的方式:
设置优雅停机超时时间,缺省超时时间是 10 秒,如果超时则强制关闭。
设置超时方法:(单位毫秒)
-Ddubbo.service.shutdown.wait=15000
或者:
<dubbo:application>
<dubbo:parameter key="shutdown.timeout" value="15000" />
</application>
如果用 Main.main(args);启动的dubbo。
也可以配置启动参数-Ddubbo.shutdown.hook=true 。
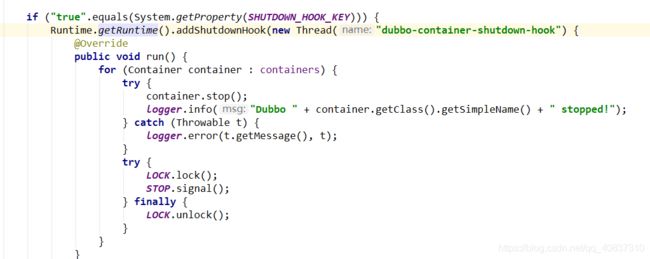
如果设置为true后,Main.main(args);方式启动过程中会添加一个关闭钩子函数。
日志适配
自 2.2.1 开始,dubbo 开始内置 log4j、slf4j、jcl、jdk 这些日志框架的适配,也可以通过以下方式显式配置日志输出策略:
命令行:
java -Ddubbo.application.logger=log4j
属性文件:
dubbo.application.logger=log4j
xml文件:
<dubbo:application logger="log4j" />
默认使用log4j日志适配。
访问日志
如果你想记录每一次请求信息,可开启访问日志,类似于apache的访问日志。注意:此日志量比较大,请注意磁盘容量。
或者将日志输出到制定文件:
启用Kryo和FST
使用Kryo和FST非常简单,只需要在dubbo RPC的XML配置中添加一个属性即可:
<dubbo:protocol name="dubbo" serialization="kryo"/>
<dubbo:protocol name="dubbo" serialization="fst"/>
要让Kryo和FST完全发挥出高性能,最好将那些需要被序列化的类注册到dubbo系统中,例如,我们可以实现如下回调接口:将将来需要用到的需要序列化的类在dubbo启动时预加载到JVM中,提高效率。
public class SerializationOptimizerImpl implements SerializationOptimizer {
public Collection<Class> getSerializableClasses() {
List<Class> classes = new LinkedList<Class>();
classes.add(BidRequest.class);
classes.add(BidResponse.class);
classes.add(Device.class);
classes.add(Geo.class);
classes.add(Impression.class);
classes.add(SeatBid.class);
return classes;
}
}
由于注册被序列化的类仅仅是出于性能优化的目的,所以即使你忘记注册某些类也没有关系。事实上,即使不注册任何类,Kryo和FST的性能依然普遍优于hessian和dubbo序列化。