使用visDrone数据集训练yolov5检测器
yolov5目标检测具备一定的小目标检测能力,但由于参与训练的coco数据集缺少小目标素材,故检测小目标有局限。本文利用无人机采集的小目标数据集,对yolov5权重文件进行再训练,提高小目标检测能力。本文仅记录跑通训练的过程,得到一些启示,没有尝试训练整个数据集。
visDrone数据集训练前后的对比
使用visDrone无人机小目标数据集训练yolov5检测器比较

上图用未训练的yolov5s.pt,下图用经过训练的best.pt权重。

可以看出两种检测的区别,其中visDrone训练图片用了其中69张,epoch=100,简单训练已初见成效。而且并没有改变原来的yolov5s模型结构。此测试图来自评估集val。
组织转换visDrone数据集
利用yolov5训练程序,采用visDrone训练集的过程如下:
下载visDrone训练集:https://github.com/VisDrone/VisDrone-Dataset。其中有百度网盘和google drive两种选择,在百度网盘限速时,google drive的下载速度明显快。
新版yolov5提供了visDrone数据集转yolov5训练数据集的格式变换,见yolov5/data/VisDrone.yaml。将该文件中附带的数据集的处理部分取出,新建visdrone2yolov5.py。
from utils.general import download, os, Path
def visdrone2yolo(dir):
from PIL import Image
from tqdm import tqdm
def convert_box(size, box):
# Convert VisDrone box to YOLO xywh box
dw = 1. / size[0]
dh = 1. / size[1]
return (box[0] + box[2] / 2) * dw, (box[1] + box[3] / 2) * dh, box[2] * dw, box[3] * dh
(dir / 'labels').mkdir(parents=True, exist_ok=True) # make labels directory
pbar = tqdm((dir / 'annotations').glob('*.txt'), desc=f'Converting {dir}')
for f in pbar:
img_size = Image.open((dir / 'images' / f.name).with_suffix('.jpg')).size
lines = []
with open(f, 'r') as file: # read annotation.txt
for row in [x.split(',') for x in file.read().strip().splitlines()]:
if row[4] == '0': # VisDrone 'ignored regions' class 0
continue
cls = int(row[5]) - 1 # 类别号-1
box = convert_box(img_size, tuple(map(int, row[:4])))
lines.append(f"{cls} {' '.join(f'{x:.6f}' for x in box)}\n")
with open(str(f).replace(os.sep + 'annotations' + os.sep, os.sep + 'labels' + os.sep), 'w') as fl:
fl.writelines(lines) # write label.txt
dir = Path('~/project_name/datasets/VisDrone2019') # datasets文件夹下Visdrone2019文件夹目录
# Convert
for d in 'VisDrone2019-DET-train', 'VisDrone2019-DET-val', 'VisDrone2019-DET-test-dev':
visdrone2yolo(dir / d) # convert VisDrone annotations to YOLO labels
如此,用visdrone2yolov5.py产生符合yolov5训练数据格式的labels。VisDrone原数据集中,VisDrone2019-DET-train目录下有两个目录:annotations和images,运行visdrone2yolov5.py后,产生labels目录。在yolov5训练中,仅使用-train和-val目录下的images和labels。
准备好的数据集结构如下,注意datasets目录与yolov5目录同级。

构造数据集配置文件,可从VisDrone.yaml修改而得。
# YOLOv5 by Ultralytics, GPL-3.0 license
# VisDrone2019-DET dataset https://github.com/VisDrone/VisDrone-Dataset by Tianjin University
# Example usage: python train.py --data VisDrone.yaml
# parent
# ├── yolov5
# └── datasets
# └── VisDrone ← downloads here
#Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ~/project_name/datasets/VisDrone2019 # dataset root dir
train: VisDrone2019-DET-train # train images (relative to 'path') 6471 images
val: VisDrone2019-DET-val # val images (relative to 'path') 548 images
#test: VisDrone2019-DET-test-dev # test images (optional) 1610 images
# Classes
nc: 10 # number of classes
names: ['pedestrian', 'people', 'bicycle', 'car', 'van', 'truck', 'tricycle', 'awning-tricycle', 'bus', 'motor']
注:visDrone数据集共有类型11个,此处只用到10个,去除了others,即背景类。
修改yolov5s.yaml,将nc改为10
# Parameters
nc: 10 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
至此,完成visDrone数据集配置修改,可运行train.py。这里需要对命令行做如下修改:
--data ~/project_name/yolov5/data/myvisDrone.yaml
--cfg ~/project_name/yolov5/models/yolov5s.yaml
--weights ~/project_name/yolov5/weights/yolov5s.pt
--workers 4
--batch-size 4
--epochs 100
其中,workers=4,与主机GPU能力有关;batch-size=4,与GPU内存大小有关。
运行train.py
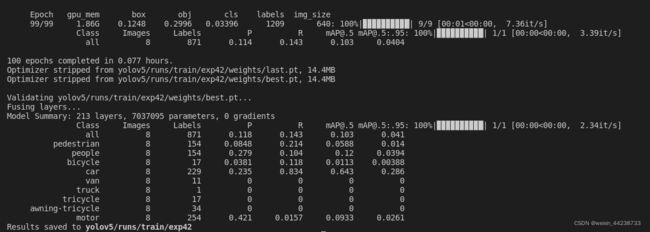
运行结果存放在yolov5/runs/train/exp文件夹中,得到权重best.pt。对visDrone数据集截取图片主要选取包含car图片,故只有类别car精度较好,[email protected]=0.643,小目标car效果不错。
运行detect.py检验权重best.pt的训练效果,得到博文开始的图片。
关于yolov5检测类别
yolov5网站提供的权重文件,如yolov5s.pt由coco数据集训练,其检测类别见coco.yaml,共80个类别,classes 0-79。
# Classes
nc: 80 # number of classes
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush'] # class names
运行detect.py时,选项–classes给出所希望检测的目标。yolov5模型将所有类别检出,过滤则由非极大值抑制non_max_supperssion()执行。
当用VisDrone数据集训练后,以前权重yolov5s.pt所用的类别失效,而服从于VisDrone分类方式。见VisDrone.yaml,此处共10个分类,类别号0-9。
# Classes
nc: 10 # number of classes
names: ['pedestrian', 'people', 'bicycle', 'car', 'van', 'truck', 'tricycle', 'awning-tricycle', 'bus', 'motor']
从另一篇博文yolov5目标框预测
可知,yolov5输出向量中,代表目标类别参数,图中c1,c2,c3,…指定目标类别,类别构成由VisDrone.yaml指定,在本例中共10个类别:c1,c2,…, c10。若采用coco数据集,类别数=80, 则Class labels由c1-c80确定。

通常,在推理检测时,往往指定需要提取的类别class,而过滤掉其他类别,这一过程由非极大值抑制函数完成。
这里要指出,原VisDrone共11个分类,类别号1-11,与coco数据集习惯不同。
所以,从VisDrone标注文件annotations到yolov5格式的labels转换时,类别号-1,这一转换在visdrone2yolov5.py中完成。
因此,运行detect.py时,需注意所选择类别为:
pedestrian : 0
people : 1
bicycle : 2
car : 3
…