C++侯捷STL标准库与泛型编程笔记
C++STL
本篇博文参考与侯捷老师的STL泛型编程课程,将其中比较重要的部分记录来下,方便今后的复习。十分推荐侯捷老师的C++系列,真的是圣经一样的存在!
1.STL六大部件Component
-
容器(
Containers) -
分配器(
Allocators) -
算法(
Alogorithms) -
迭代器(
Iterators) -
适配器(
Adapters) -
仿函数(
Functors)

2.分配器
allocator以::operator new 和::operator delete完成allocate()和deallocate()。
在VC6.0的版本下分配器的定义如下,可以看出只是对operator new和operator delete进行了一层封装:
template<class _Ty>
class allocator
{
public:
typedef _SIZT size_type; // size_t
typedef _PDFT difference_type; // ptrdff_t
typedef _Ty _FARQ pointer;
typedef _Ty value_type;
pointer allocate(size_type _N,const void*)
{
return (_Allocate((difference_type)_N,(pointer)0));
}
void deallocate(void _FARQ *_P, size_type) {
operator delete(_P);
};
private:
inline _Ty _FARQ*_Allocate(_PDFT _N, _Ty _FARQ *)
{
if(_N<0)_N=0;
return ((_Ty _FARQ *) operator new((_SIZT) _N * sizeof(_Ty)));
}
};
//我们自己使用的话需要这样调用
//分配512int
//可以发现这样在分配的时候,我们需要知道我们自己需要多少空间,在释放的时候也相应的释放多少空间,这样很不方便
int *p = allocator<int>().allocate(512,(int*)0);
allocator<int>().deallocate(p,512);
但在gcc2.9的版本中,allocator并非gcc2.9的默认分配器,而是std::alloc
class alloc
{
protected:
enum { _S_align = 8 };
enum { _S_max_bytes = 128 };
enum { _S_free_list_size = (size_t) _S_max_bytes / (size_t) _S_align };
union _Obj {
union _Obj *_M_free_list_link;
char _M_client_data[1]; // The client sees this.
};
...
}
gcc4.9以后,默认分配器变为allocator,变回了对::operator new和::operator delete的简单封装.alloc更名为__gnu_cxx::__pool_alloc.
3.容器
容器符合前闭后开区间 []()[) 即c.begin()指向头,c.end()则指向尾元素的下一个。
Container<T>c
...
Container<T>::iterator ite = c.begin();
for(;ite!=c.end();++ite)
...
在C++11中可以换成range-base for statement重写以上程序
for(auto elem:c){
...
}
容器结构和分类

- Sequence Container
- Array C++11
- Vector
- Deque
- List
- Forward-List C++11
- Associative Container
- Set/Multiset
- Map/Multimap
- Unordered Set/MultiSet C++11
- Unordered Map/MultiMap C++11
SequenceContainer: Arry大小是固定的不可扩充,Vector可以自动扩充,Deque双向扩充,List(双向链表),Forward-List(单向链表)。
AssociativeContainer:Set(Key==Value),Map(Key,Value)。因为存储结构是随机而不是连续的,所以迭代器不满足RandomAccessIterator(随机访问迭代器),由红黑树实现。Unordered的数据结构是HashTable实现。
3.1 List深度探索
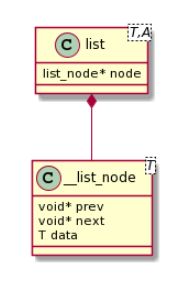
list是一个双向链表,普通指针已经不能满足list迭代器的需求,因为list的空间是不连续的,所以list的迭代器需要具备前移和后退的功能,所以list迭代器的类型是Bidirectionallterator。
template<class T,class Alloc=alloc>
class list
{
protected:
typedef __list_node<T> list_node;
public:
typedef list_node* link_type;
typedef __list_iterator<T,T&,T*>iterator;
protected:
link_type node;
...
}
template<class T>
struct __list_node
{
typedef void* void_pointer;
void_pointer prev;
void_pointer next;
T data;
}
list(双向链表),在GNU2.9源码中,list类中维护了node这个属性,这个属性就是一个包含两个指针prev、next和当前data的结构体。基于容器都要满足前闭后开的原则,在list的头部会添加一个灰部地带,begin()获得灰部地带下一个节点,end()获得灰部地带。

// __list_iterator源码
template<class T,class Ref,class Ptr>
struct __list_iterator
{
typedef __list_iterator<T,Ref,Ptr> self;
typedef bidirectional_iterator_tag iterator_category;
typedef T value_type;
typedef Ptr pointer;
typedef Ref reference;
typedef __list_node<T>* link_type;
typedef ptrdiff_t difference_type;
link_type node;
reference operator*()const{return *(node).data;}
pointer operator->()const{return &(operator*());}
self& operator++(){
node = (link_type)(*node).next;
return *this;
}
self operator++(int){
self temp = *this;
++*this;
return temp;
}
...
};
__list_iterator其中定义了5种参数,这五种参数是为了Iterator traits做准备:
-
bidirectional_iterator_tag -
T(value_type) -
ptr(pointer) -
Ref(reference) -
ptrdiff_t(difference_type)
同时list的iterator是一个class,主要是因为list的内部数据结构是随机存储,所以需要一个足够聪明的iterator来模拟出list能够支持随机访问的功能。为了做到这点,iterator中重载operator*,operator->,operator++,operator++(int)等操作符。
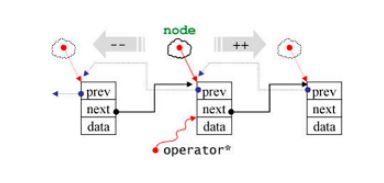
在上述源码中,在重载operator++(int)函数中需要注意的是,self temp = *this不会调用operator*(),因为在这之前已经调用了拷贝构造。
在STL的算法中,需要传入容器的迭代器,然后根据推断判断出迭代器的类型。
3.2 Iterator traits
iterator是container和algorithms之间的桥梁,container想要使用algorithms中的算法,iterator是必不可少的,但每个container的iterator特性不一致,怎样才能有效的让算法知道调用的是哪个iterator并且知道需要做怎样的处理呢?
template<typename _ForwardIterator>
inline void rotate(_ForwardIterator __first,_ForwardIterator __middle,_ForwardIterator __last){
...
std::__rotate(__first,__middle,__last,std::__iterator_category(__first));
}
template<typename _Iter>
inline typename iterator_traits<_Iter>::iterator_category __iterator_category(const _Iter&){
return typename iterator_traits<_Iter>::iterator_category();
}
如上述所示为算法rotate的部分代码,可知算法内部还需要做Iterator类型获取操作。
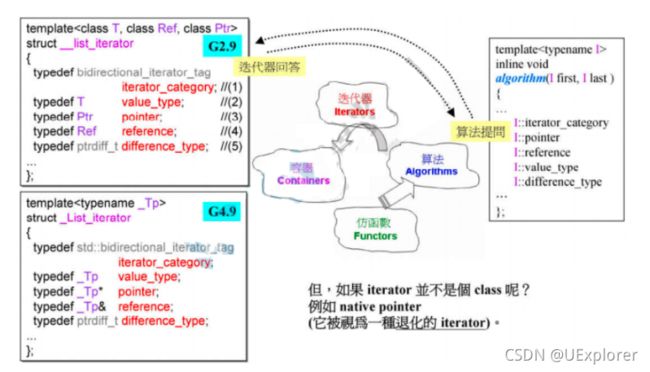
同时算法中为了得到迭代器的类型也声明了迭代器的5个关联类型,为了回答algorithms的提问,在iterator(前提该iterator是一个class)中就必须要提供:
1.Iterator_category
2.value_type
3.pointer
4.reference
5.diffrence_type
同时为了考虑兼容性的问题,就在迭代器和算法之间加了一中间层"萃取机"(traits),同时也是为了用它来辨别iterator是class类型还是non-class(指针)类型

那么问题来了,traits是如何分辨class和non-class类型的iterator呢?答案是partial specialization(模板的偏特化)。
// iterator为class类型,直接取默认泛型
template<class I>
struct iterator_traits {
typedef typename I::iterator_category iterator_category;
typedef typename I::value_type value_type;
typedef typename I::difference_type difference_type;
typedef typename I::pointer pointer;
typedef typename I::reference reference;
};
// iterator为指针
template<class T>
struct iterator_traits<T *> {
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef ptrdiff_t difference_type;
typedef T* pointer;
typedef T& reference;
};
// iterator为常量指针
template<class T>
struct iterator_traits<const T *> {
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef ptrdiff_t difference_type;
typedef const T* pointer;
typedef const T& reference;
};
其中value_type的主要目的是用来声明变量,而声名一个无法被赋值的变量没什么用,所以iterator(即使是const iterator)的value_type不应加上const。
3.3 Vector深度探索

// vector源码
template<class T,class Alloc=alloc>
class vector
{
public:
typedef T value_type;
typedef value_type* iterator;
typedef value_type& reference;
typedef size_t size_type;
protected:
iterator start;
iterator finish;
iterator end_of_storage;
public:
iterator begin(){return start;}
iterator end(){return finish;}
size_type size()const{return (size_type)end_of_storage-begin();}
bool empty()const{return begin()==end();}
reference operator[](size_type n){
return *(begin()+n);
}
reference front(){return *begin();}
reference back(){return *(end()-1);}
...
};
vector容器的迭代器start指向第一个元素,finish指向最后一个元素的下一个元素,满足了前闭后开特性,end_of_storage是vector的容量。vector在使用上是连续的,在实现上也是连续的,所以迭代器采用non-class类型。
vector.push_back()的方法,首先会判断end_of_storage是不是满了,满了的话就会扩容2倍再进行添加元素。注意:扩充的过程重并不是在原有空间后面追加容量,而是重新申请一块连续的内存空间,将原有的数据拷贝到新空间中,再释放原来空间中内存。所以扩充之后,原有的迭代器将会失效!
void push_back(const T& x){
if(finish!=end_of_storage){
construct(finish,x);
++finish;
}else
insert_aux(end(),x);
}
insert_aux是vector容器用来在内部任意位置插入元素,内存不足的情况下会扩容。
template<class T, class Alloc>
void vector<T, Alloc>::insert_ux(iterator position, const T &x) {
if (finish != end_of_storage) { // 尚有备用空间,则将插入点后元素后移一位并插入元素
construct(finish, *(finish - 1)); // 以vector最后一个元素值为新节点的初值
++finish;
T x_copy = x;
copy_backward(position, finish - 2, finish - 1);
*position = x_copy;
} else {
// 已无备用空间,则先扩容,再插入
const size_type old_size = size();
const size_type len = old_size != 0 ?: 2 * old_size:1; // 扩容后长度为原长度的两倍
iterator new_start = data_allocator::allocate(len);
iterator new_finish = new_start;
try {
new_finish = uninitialized_copy(start, position, new_start); // 拷贝插入点前的元素
construct(new_finish, x); // 插入新元素并调整水位
++new_finish;
new_finish = uninitialized_copy(position, finish, new_finish); // 拷贝插入点后的元素
}
catch (...) {
// 插入失败则回滚,释放内存并抛出错误
destroy(new_start, new_finish) :
data_allocator::deallocate(new_start, len);
throw;
}
// 释放原容器所占内存
destroy(begin(), end());
deallocate();
// 调整迭代器
start = new_start;
finish = new_finish;
end_of_storage = new_start + len;
}
};
3.4 Array、ForwardList深度探索
array容器
在C++11中,新增的一种容器std::array,和我们平常所使用的array操作类似,和vector动态可扩容不同它是静态不可扩容的。
template<typename _Tp,std::size_t _Nm>
struct array
{
typedef _Tp value_type;
typedef _Tp* pointer;
typedef value_type* iterator;
// Support for zero-sized arrays mandatory
value_type _M_instance[_Nm?_Nm:1];
iterator begin(){return iterator(_M_instance[0]);}
iterator end(){return iterator(_M_instance[_Nm]);}
...
};
// 测试
array<int,10>arrayins;
auto iter = arrayins.begin();
// array::iterator ite = iter+3;
cout<<*iter<<endl;
forward_list容器
forward_list 也是C++11提供的容器,和list容器不同,它是单项链表,比起需要每个Node节点需要存储next和pre节点的list。forward_list只需要存储next节点,forward_list会更加轻量级。

3.5 Deque深度探索

deque容器(双端队列)
deque是一种双向开口的连续线性空间。deque支持从头尾两端进行元素的插入和删除。deque没有容量的概念,因为它是动态地以分段连续空间组合而成的。随时可以增加一段新的空间并连接起来。
template<class T,class Alloc=alloc,size_t BufSiz=0>
class deque
{
public:
typedef T value_type;
typedef __deque_iterator<T,T&,T*,BufSiz> iterator;
protected:
typedef pointer* map_pointer; //T**
iterator start;
iterator finish;
map_pointer map;
size_type map_size;
public:
iterator begin(){return start;}
iterator end(){return end;}
size_type size(){return finish-start;}
...
};

为了维护这种整体连续的假象,带价就是迭代器的类型会比较复杂。即采用map(类型为T**)作为主控。map实际上是一块大小连续的空间,其中每一个元素,我们称之为node,每个node都指向了另一端连续线性的空间(上图的buffer),buffer才是deque真正存储空间的地方。
其中buffer大小的确定:
/*
n不为0,传回n,buffersize由user确定
n为0,buffersize使用预设值,如果sz(sizeof(value_type))小于512,传回512/sz,否则就传回1
*/
inline size_t __deque_buf_size(size_t n,size_t sz)
{
return n!=0?n:(sz<512?size_t(512/sz):size_t(1));
}
关于deque的iterator设计:
template<class T,class Ref,class Ptr,size_t BufSiz>
struct __deque_iterator
{
typedef random_access_iterator_tag iterator_category; //1
typedef T value_type; //2
typedef Ptr pointer; //3
typedef Ref reference; //4
typedef size_t size_type;
typedef ptrdiff_t difference_type; //5
typedef T** map_pointer;
typedef __deque_iterator self;
T* cur;
T* first;
T* last;
map_pointer node;
...
};
deque的iterator有四个部分,cur指向buffer当前元素,first指向buffer的头,last指向尾,node指向map(主控中心)。
deque插入函数首先判断传入迭代器的位置是处于容器前半部分还是后半部分,再插入进比较短的那一段。
iterator inset(iterator position,const value_type& x)
{
if(position.cur==start.cur){
push_front(x);
return start;
}else if(position.cur==finish.cur){
push_back(x);
return finish
}else{
return insert_aux(position,x);
}
}
若插入位置是容器首部,则直接push_front,位置是容器尾部,则直接push_back。其他情况则调用insert_aux方法:
template<class T,class Alloc,size_t BufSize>
typename deque<T,Alloc,BufSize>::iterator
deque<T,Alloc,BufSize>::insert_aux(iterator pos,const value_type& x){
difference_type index = pos-start; //安插点之前的元素个数
value_type x_copy = x;
if(index<size()/2){ //如果安插点之前的元素个数较少
push_front(front()); //在最前端加入和第一元素同值的元素
...
copy(front2,pos1,front1); //元素搬移
}else{ //安插点之后较少
push_back(back()); //在尾端加入和最末元素同值的元素
...
copy_backward(pos,back2,back2); //元素搬移
}
*pos = x_copy;
return pos;
}
deque如何模拟连续的空间:
reference operator[](size_type n){
return start[difference_type(n)];
}
reference front(){
return *start;
}
reference back(){
iterator tmp = finish;
--temp;
return *temp;
}
size_type size()const{
return finish-start;
}
bool empty()const{
return finish==start;
}
重要的操作符重载:
reference operator*()const{
return *cur;
}
pointer operator->()const{
return &(operator*());
}
//两根iterator之间的距离相当于 两根iterators之间的buffers的总长度+it1至其buffer尾部长度+it2至其buffer头部的长度
difference_type operator-(const self& x)const{
return difference_type(buffer_size())*(node-x.node-1)+(cur-first)+(x.last-x.cur);
}
self& operator++(){
++cur;
if(cur==last){
set_node(node+1); //跳到下一节点的起始节点
cur = first;
}
return *this;
}
self operator++(int){
self tmp = *this;
++*this;
return temp;
}
self& operator--(){
--cur;
if(cur==first){
set_node(node-1); //跳到上一节点的尾节点
cur = last;
}
return *this;
}
self operator--(int){
self tmp = *this;
--*this;
return temp;
}
void set_node(map_pointer new_node){
node = new_node;
first = *node;
last = first+difference_type(buffer_size());
}
self& operator+=(difference_type n)
{
difference_type offset = n+(cur-first);
if(offset>=0&&offset<difference_type(buffer_size()))
// 目标在同一buffer内
cur +=n;
else{
// 目标不在同一buffer内
difference_type node_offset = offset>0?offset/difference_type(buffer_size()):-difference_type((-offset-1)/buffer_size())-1;
// 切换至正确的buffer内
set_node(node+node_offset);
// 切换至正确的元素
cur = first+(offset-node_offset*difference_type(buffer_size()));
}
return *this;
}
self operator+(difference_type n){
self tmp = *this;
return temp+=n;
}
3.6 Queue、Stack深度探索
容器queue、stack在STL的实现中有相似之处,都以deque作为适配器(adapter),其内部均默认封装了一个deque作为底层容器,上层容器的API大部分通过操作deque的API进行实现。queue是先进先出,stack是先进后出,进出都有严格要求,所以两个容器不允许遍历,所以它们没有迭代器。
queue

template<class T, class Sequence=deque<T>>
class queue {
public:
typedef typename Sequence::value_type value_type;
typedef typename Sequence::size_type size_type;
typedef typename Sequence::reference reference;
typedef typename Sequence::const_reference const_reference;
protected:
Sequence c; // 底层容器,默认是dequestack

template<class T, class Sequence=deque<T> >
class stack {
public:
typedef typename Sequence::value_type value_type;
typedef typename Sequence::size_type size_type;
typedef typename Sequence::reference reference;
typedef typename Sequence::const_reference const_reference;
protected:
Sequence c;// 底层容器,默认是deque 也可以指定其他容器,例如list、vector作为stack和queue的底层容器,因为它们内部也实现了对应所需要的方法。
queue<int, list<int>> q1;
for (long i = 0; i < 10; ++i) {
q1.push(rand());
}
stack<int, list<int>> s1;
for (long i = 0; i < 10; ++i) {
s1.push(rand());
}
stack<int, vector<int>> s2;
for (long i = 0; i < 10; ++i) {
s2.push(rand());
}
但如果指定了错误的容器(该容器没有实现对应的方法),编译并不会报错,表明了编译器在处理模板时不会做全面的检查,所以最好还是使用默认的模板作为它们的底层容器。
3.7 Rb_Tree 深度探索

red-black tree(红黑树)是平衡二元搜索树(balanced binary tree)。其特征:排列规则有利于Search和Insert,并保持适度平衡—无任何节点过深。rb_tree提供两种插入操作:inset_unique和insert_equal。前者需要key在树是独一无二的(multimap/set不适用),后者key可以重复存在。
template<class Key,class Value,class KeyOfValue,class Compare,class Alloc=alloc>
class rb_tree
{
protected:
typedef __rb_tree_node<Value> rb_tree_node;
public:
typedef rb_tree_node* link_type;
protected:
size_type node_count; //rb_tree的节点数量
link_type header; //头节点
Compare Key_compare; //Key排序方式
};
rb_tree在使用中需要你提供4个参数:Key、Value、KeyofValue(提取Key的方法)、Compare(比较key的大小的方法)。
template <class T>
struct identity:public unary_function<T,T>{
const T& operator()(const T& ref)const
{
return ref;
}
}
template <class T>
struct less:public binary_function<T,T,bool>{
bool operator()(const T&x,const T&y){
return x<y;
}
}
void RbTreeTest(){
_Rb_tree<int,int,identity<int>,less<int>> tree;
cout << itree.empty() << endl; //1
cout << itree.size() << endl; //0
itree._M_insert_unique(3);
itree._M_insert_unique(8);
itree._M_insert_unique(5);
itree._M_insert_unique(9);
itree._M_insert_unique(13);
itree._M_insert_unique(5); //no effect, since using insert_unique().
cout << itree.empty() << endl; //0
cout << itree.size() << endl; //5
cout << itree.count(5) << endl; //1
itree._M_insert_equal(5);
itree._M_insert_equal(5);
cout << itree.size() << endl; //7, since using insert_equal().
cout << itree.count(5) << endl; //3
}
3.8 Set、Multiset深度探索
set/multiset以rb_tree为底层结构,因此有元素自动排序的功能,排序的依据是key,而set/multiset元素的value和key合一(Value就是Key)。
注意:我们无法使用set/multiset的iterator改变元素值(因为key有其严谨的排列规则)。set/multiset的iterator是其底部rbtree的const-iterator。
set的insert()用的是rb_tree的inset_unique()。
multiset的insert()用的是rb_tree 的inset_equal()。
template<class Key,
class Compare = less<Key>,
class Alloc = alloc>
class set {
public:
typedef Key key_type;
typedef Key value_type;
typedef Compare key_compare;
typedef Compare value_compare;
private:
typedef rb_tree <key_type,
value_type,
identity<value_type>,
key_compare,
Alloc> rep_type;
rep_type t; // 内部rb_tree容器
public:
typedef typename rep_type::const_iterator iterator;
};
从set的源码可以看出,set的大部分核心操作其实都扔给了rbtree,set这里可以看成一个container adapter。
3.9 Map、Multimap深度探索
Map/multimap以rb_tree为底层结构,因此有元素自动排序的功能,排序的依据是key。
注意:我们无法使用map/multimap的iterator改变元素值(因为key有其严谨的排列规则),但可以用它来该改变元素的data。map/multimap内部自动将user指定的keytype设定为const,以便禁止user对元素的key赋值。
map的insert()用的是rb_tree的inset_unique()。
multimap的insert()用的是rb_tree 的inset_equal()。
template<class key,Class T,class Compare=less<key>,class Alloc=alloc>
class map{
public:
typedef key key_type;
typedef T data_type;
typedef T mapped_type;
typedef pair<const key,T> value_type // 这里指定const key防止user修改key
typedef Compare key_compare;
private:
typedef rb_tree<key_type,value_type,select1st<value_type>,key_compare,Alloc> rep_type
rep_type t; //rb_tree
public:
typedef typename rep_type::iterator iterator;
}
template<class Pair>
struct select1st:public unary_function<Pair,typename Pair::first_type>
{
const typename Pair::first_type& operator()(const Pair& x){
return x.first;
}
}
map中特别的符号重载operator[]
operator[](const key_type& _k)
如果k存在,返回该iterator,不存在就在合适的位置创造该k
mapped_type& operator[](const key_type& _k){
iterator _i = lower_bound(_k);
if(_i=end()||key_comp()(_k,(*_i).first))
_i = insert(_i,value_type(_k,mapped_type()));
return(*_i).second;
}
multimap中无法使用operator[]。
3.10 HashTable深度探索
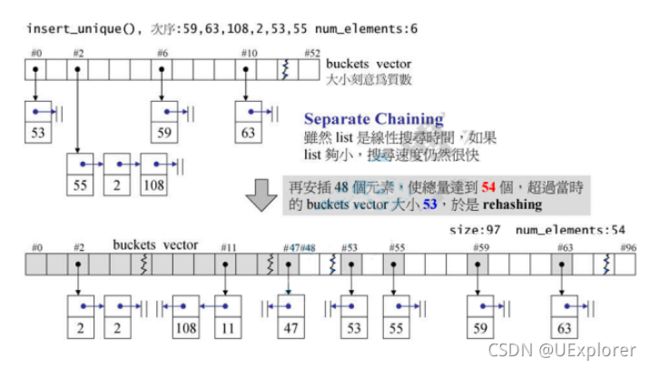
当元素个数大于buckets时,进行rehashing。成长倍数(在GNUC下)为两倍,成长完成后所有元素重新排列,实现元素的散列分布。
hashtable源码:
//HashFcn 确定Hashtable中元素编号的方法,通常为函数对象
//Extractkey 如果元素是一对pair,需要告诉提取key的方法
//Equalkey 比较key大小的方法
template<class value,
class key,
class HashFcn,
class Extrackey,
class EqualKey,
class Alloc=alloc>
class hashtable{
public:
typedef HashFnc hasher;
typedef EqualKey key_equal;
typedef size_t size_type;
private:
hasher hash;
key_equal equals;
Extrackey get_key;
typedef _hashtable_node<value> node;
vector<node*,Alloc> buckets;
size_type num_elements;
public:
size_type bucket_count()const{return buckets.size();}
...
}
template<class value>
struct _hashtable_node{
_hashtable_node* next;
value val;
...
}
template<class value,class key,class HashFcn,class Extrackey,class EqualKey,class Alloc=alloc>
struct _hashtable_iterator{
...
node* cur;
hashtable* ht;
}
void hashtableTest(){
hashtable<const char*,
const char*,
hash<const char*>,
identity<const char*>,
eqstr>
ht(50,hash<const char*>(),eqstr());
ht.insert_unique("zsas");
ht.insert_unique("asdfs");
}
struct eqstr{
bool operator()(const char*s1,const char*s2)const{
return strcmp(s1,s2)==0;
}
}
怎样使用hashfunction?
hashfun源码:
template<class key>struct hash{};
_STL_TEMPLATE_NULL struct hash<char>{size_t operator()(const char x)const (return x;)};
_STL_TEMPLATE_NULL struct hash<short>{size_t operator()(const short x)const (return x;)};
_STL_TEMPLATE_NULL struct hash<unsigned short>{size_t operator()(const unsigned short x)const (return x;)};
_STL_TEMPLATE_NULL struct hash<int>{size_t operator()(const int x)const (return x;)};
_STL_TEMPLATE_NULL struct hash<unsigned int>{size_t operator()(const unsigned int x)const (return x;)};
_STL_TEMPLATE_NULL struct hash<long>{size_t operator()(const long x)const (return x;)};
_STL_TEMPLATE_NULL struct hash<unsigned long>{size_t operator()(const unsigned long x)const (return x;)};
_STL_TEMPLATE_NULL struct hash<char*>{size_t operator()(const char* s)const (return _stl_hash_string(s);)};
_STL_TEMPLATE_NULL struct hash<const char*>{size_t operator()(const char* s)const (return _stl_hash_string(s);)};
inline size_t _stl_hash_string(const char* s){
unsigned long h=0;
for(;*s;++s){
h=5*h+*s;
}
return size_t(h);
}
//注意stl中没有提供string类型的hashfunc模板特化版本,需要自己提供
3.11 Unordered容器使用
C++11引入的容器unordered_set、unordered_multiset、unordered_map和unordered_multimap更名自GCC2.9的下 容器hash_set、hash_multiset、hash_map和hash_multimap,其底层封装了hashtable.用法与set、multiset、map和multimap类似。
void UnorderedSetCompare() {
unordered_multiset<string>s;
char buf[10];
for (long i = 0; i < INPUTSIZE; i++) {
try
{
snprintf(buf, 10, "%d", rand());
s.insert(string(buf));
}
catch (const std::exception& p)
{
cout << "i= " << i << " " << p.what() << endl;
abort();
}
}
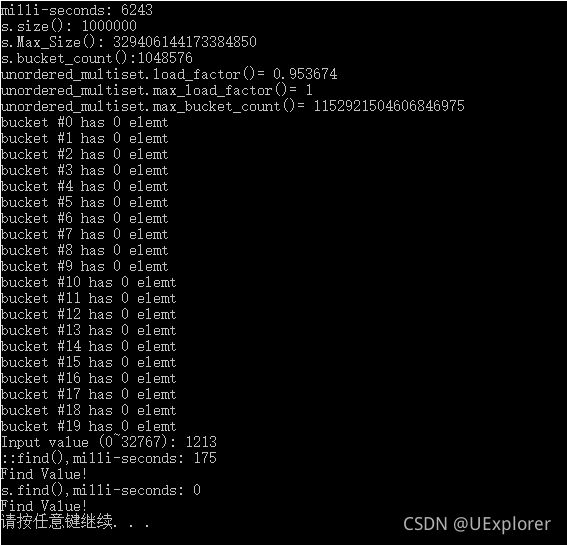
cout << "milli-seconds: " << clock() << endl;
cout << "s.size(): " << s.size() << endl;
cout << "s.Max_Size(): " << s.max_size() << endl;
cout << "s.bucket_count():" << s.bucket_count() << endl;
cout << "unordered_multiset.load_factor()= " << s.load_factor() << endl;
cout << "unordered_multiset.max_load_factor()= " << s.max_load_factor() << endl;
cout << "unordered_multiset.max_bucket_count()= " << s.max_bucket_count() << endl;
for (unsigned i = 0; i < 20; i++) {
cout << "bucket #" << i << " has " << s.bucket_size(i) << " elemt " << endl;
}
string target = get_a_string_target();
Clock_Time start_time = clock();
auto ite = ::find(s.begin(), s.end(), target);
cout << "::find(),milli-seconds: " << (clock() - start_time) << endl;
if (ite != s.end()) {
cout << "Find Value!" << endl;
}
else {
cout << "Not Find Value" << endl;
}
start_time = clock();
ite = s.find(target); //比全局::sort函数快很多
cout << "s.find(),milli-seconds: " << (clock() - start_time) << endl;
if (ite != s.end()) {
cout << "Find Value!" << endl;
}
else {
cout << "Not Find Value" << endl;
}
}
4.算法
4.1 算法的一般结构
algorithm看不见container,所以它所需要的一切信息都必须从iterator获取,而iterator(由container提供)必须要回答algorithm的所有提问container才能搭配该algorithm的所有操作。
- STL源码中所有算法都遵循以下格式:
template<typename iterator>
Algorithm(iterator itr1,iterator itr2){
...
}
template<typename iterator,typename Cmp>
Algorithm(iterator itr1,iterator itr2,Cmp comp){
...
}
4.2 迭代器分类

迭代器的关联类型iterator_category表示迭代器类型,其分类为以下5种:
1. struct input_iterator_tag{};
2. struct ouput_iterator_tag{};
3. struct forward_iterator_tag:public input_iterator_tag{};
4. struct bidirectional_iterator_tag:public forward_iterator_tag{};
5. struct random_access_iterator_tag:public bidrectional_iterator_tag{};
采用class而非enum来表示迭代器类型,出于以下两个考量:
- 使用类继承可以表示不同迭代器类型的从属关系。
STL算法可以根据传入的迭代器类型调用不同版本的重载函数。
void _displayIteratorCategory(random_access_iterator_tag) {
cout << "random_access_iterator_tag" << endl;
}
void _displayIteratorCategory(forward_iterator_tag) {
cout << "forward_iterator_tag" << endl;
}
void _displayIteratorCategory(bidirectional_iterator_tag) {
cout << "bidirectional_iterator_tag" << endl;
}
void _displayIteratorCategory(input_iterator_tag) {
cout << "input_iterator_tag" << endl;
}
void _displayIteratorCategory(output_iterator_tag) {
cout << "output_iterator_tag" << endl;
}
template<typename T>
void displayIteratorCategory(T iter) {
typename iterator_traits<T>::iterator_category cag;
_displayIteratorCategory(cag);
}
void iteratorCategoryTest() {
displayIteratorCategory(vector<int>::iterator()); //random_access_iterator
displayIteratorCategory(array<int,10>::iterator()); //random_access_iterator
displayIteratorCategory(list<int>::iterator()); //bidirectional_iterator
displayIteratorCategory(forward_list<int>::iterator()); //forward_iterator
displayIteratorCategory(deque<int>::iterator()); //random_access_iterator
displayIteratorCategory(set<int>::iterator()); //bidirectional_iterator
displayIteratorCategory(map<int,int>::iterator()); //bidirectional_iterator
displayIteratorCategory(unordered_set<int>::iterator()); //forward_iterator
displayIteratorCategory(unordered_map<int,int>::iterator()); //forward_iterator
displayIteratorCategory(istream_iterator<int>()); //input_iterator
displayIteratorCategory(ostream_iterator<int>(cout,"")); //output_iterator
}

容器vector、array、deque对使用者来说空间是连续、可跳跃的,所以迭代器是random_access_iterator。
容器list为双向链表,set、map、multimap、multiset本身是有序的,支持双向移动,所以为bidirectional_iterator。
容器forward_list为单向链表容器unordered_set、unordered_map、unordered_multiset、unordered_map哈希表中的每个桶都是单向链表.因此其迭代器只能单向移动,因此是forward_iterator类型。
迭代器istream_iterator和ostream_iterator本质上是迭代器,后文会提到这两个类的源码。
4.2 迭代器对算法的影响
STL中大部分算法会根据传入的迭代器类型以及其他信息来调用不同的重载函数,针对特定的迭代器调用最优的重载版本。
- STL中
distance根据不同iterator_category执行不同的重载函数
template<class InputIterator>
inline iterator_traits<InputIterator>::difference_type
_distance(InputIterator first,InputIterator last,input_iterator_tag){
iterator_traits<InputIterator>::difference_type n=0;
while(first!=last){
++first;
++n;
}
return n;
}
template<class RandomAccessIterator>
inline iterator_traits<RandomAccessIterator>::difference_type
_distance(RandomAccessIterator first,RandomAccessIterator last,random_access_iterator_tag){
return last-first;}
//这里的iterator_traits::difference_type 为函数的返回类型,只有在运行的时候才确定是何种类型
template<class InputIterator>
inline iterator_traits<InputIterator>::difference_type
distance(InputIterator first,InputIterator last){
iterator_traits<InputIterator>::iterator_category category;
}
- STL中
Advance根据不同iterator_category执行不同的重载函数
templaye<class BidirectionalIterator,class Distance>
inline void _advance(BidirectionalIterator&i,Distance n,bidirectional_iterator_tag){
if(n>=0){
while(n--)
++i;
}
else{
while(n++)
--i;
}
}
templaye<class RandomAccessIterator,class Distance>
inline void _advance(RandomAccessIterator&i,Distance n,random_access_iterator_tag){
i+=n;
}
template<class InputIterator,class Distance>
inline void advance(InputIterator& i,Distance n){
_advance(i,n,iterator_category(i));
}
template<class Iterator>
inline typename iterator_traits<Iterator>::iterator_category
iterator_category(const Iterator&){
typedef typename iterator_traits<Iterator>::iterator_category category;
return category(); //创建temp category object
}
- STL中
copy根据不同iterator_category和type traits执行不同的重载函数

- STL中
destroy根据不同iterator_category和type traits执行不同的重载函数

- STL算法都是模板函数,无法对传入的
iterator_category类型做出限定,但源码中的模板参数名还是对接收的iterator_category做出了一定的暗示。例如在命名模板参数上。
template<class InputIterator>
inline Iterator_traits<InputIterator>::diffrence_type
distance(InputIterator first,InputIterator last){
...
}
template<class ForwardIterator>
inline void rotate(ForwardIterator first,ForwardIterator middle,ForwardIterator last){
...
}
template<class RandomAccessIterator>
inline void sort(RandomAccessIterator first,RandomAccessIterator last){
...
}
template<class InputIterator,class T>
InputIterator find(InputIterator first,InputIterator last,const T&value){
...
}
4.3 算法源码剖析
accumulate累加函数
算法accumulate的默认运算是+,但是重载版本允许自定义运算,支持所有容器,源码如下:
template<class InputIterator,class T>
T accumulate(InputIterator first,InputIterator last,T init){
for(;first!=last;++first)
//将元素累加到init上
init+=*first;
return init;
}
template<class InputIterator,class T,class BinaryOperation>
T accumulate(InputIterator first,Input last,T init,BinaryOperation binary_op){
for(;first!=last;++first)
init = binary_op(*first,init);
return init;
}
测试程序如下:
template<typename T>
T myfuncminus(const T &x,const T& y) {
return x - y;
}
struct myobjectminus {
int operator()(const int& x, const int& y) {
return x - y;
}
};
void accumulateTest() {
int arr[] = { 10,20,30 };
cout << "using default accumulate:";
cout<<accumulate(arr, arr + 3, 100); //160
cout << "\n";
cout << "using functional's minus:";
cout<<accumulate(arr, arr + 3,100,minus<int>()); //40
cout << "\n";
cout << "using custom functino:";
cout<<accumulate(arr, arr + 3,100, myfuncminus<int>); //40
cout << "\n";
cout << "using cunston object:";
cout<<accumulate(arr, arr + 3,100, myobjectminus()); //40
}
for_each遍历函数
for_each源码
template<class InputIterator,class Function>
Function for_each(InputIterator first,InputIterator last,Function f)
{
for(;first!=last;++first){
f(*first);
}
return f;
}
测试程序如下:
template<typename T>
void myforFunc(const T& x) {
cout << " " << x;
}
class myforClass {
public:
void operator()(const int& x)const {
cout << " " << x;
}
};
void foreachTest() {
vector<int>v(5, 10);
for_each(v.begin(), v.end(), myforFunc<int>);
cout << endl;
for_each(v.begin(), v.end(), myforClass());
}
replace、replace_if、replace_copy
replace源码
template<class ForwardIterator,class T>
void replace(ForwardIterator first,ForwardIteratorlast,const T& old_value,const T& new_value){
//范围内所有等同于old_value的元素以new_value取带
for(;first!=last;++first)
if(*first==old_value){
*first=new_value;
}
}
replace_if源码
template<class ForwardIterator,class Predicate,class T>
void replace_if(ForwardIterator first,ForwardIterator last,Predicate pred,const T& new_value){
//范围内所有满足pred()为true的元素都以new_value取代
for(;first!=last;++first){
if(pred(*first))
*first=new_value;
}
}
replace_copy源码
template<class InputIterator,class OutputIterator,class T>
outputIterator replace_copy(InputIterator first,InputIterator last,OutputIterator result,const T& old_value,const T& new_value){
//范围内所有等同于old_value者都以new_value放至新区间,
//不符合者原值放入新区间
for(;first!=last;++first,++result)
*result=*first!=old_value?new_value:*first;
return result;
}
count、count_if
cout源码
template<class InputIterator,class T>
typename iterator_traits<InputIterator>::difference_type
count(InputIterator first,InputIterator last,const T& value){
//定义一个初值为0的计数器n
typename iterator_traits<InputIterator>::differebce_type n =0;
for(;first!=last;++first)
if(*first==value)
++n;
return n;
}
count_if源码
template<class InputIterator,class Predicate>
typename iterator_traits<InputIterator>::difference_type
count(InputIterator first,InputIterator last,Predicate pred){
//定义一个初值为0的计数器n
typename iterator_traits<InputIterator>::differebce_type n =0;
for(;first!=last;++first)
//如果元素带入pred的结果为true,计数器累加1
if(pred(*first))
++n;
return n;
}
不带成员count算法的容器:
array,vector,list,forward_list,deque
带有成员函数count算法的容器(关联式容器有更高效的计数方式)
set\multiset,map\multimap,unordered_set\multi,unordered_map\multi
find、find_if循序式查找算法
find源码
template<class InputIterator,class T>
InputIterator find(InputIterator first,InputIterator last,const T& value)
{
while(first!=last&&*first!=value)
++first;
return first;
}
find_id源码
template<class InputIterator,class Predicate>
InputIterator find(InputIterator first,InputIterator last,Predicate pred)
{
while(first!=last&&!pred(*first))
++first;
return first;
}
不带成员find算法的容器:
array,vector,list,forward_list,deque
带有成员函数find算法的容器(关联式容器有更高效的查找方式)
set\multiset,map\multimap,unordered_set\multi,unordered_map\multi
sort排序算法
算法sort暗示参数为random_access_iterator_tag类型迭代器,因此该算法只支持容器array、vector和deque.
容器list和forward_list含有sort方法.
容器set、map、multiset、multimap本身是有序的,容器unordered_set、unordered_map、unordered_multiset和unordered_map本身是无序的,不需要排序.
template<typename RandomAccessIterator>
inline void sort(RandomAccessIterator first, RandomAccessIterator last)
{
// ...
}
应用:
// 自定义函数
bool myfunc(int i, int j) { return (i < j); }
// 自定义仿函数
struct myclass {
bool operator()(int i, int j) { return (i < j); }
} myobj;
int main() {
int myints[] = {32, 71, 12, 45, 26, 80, 53, 33};
vector<int> myvec(myints, myints + 8); // myvec内元素: 32 71 12 45 26 80 53 33
sort(myvec.begin(), myvec.begin() + 4); // 使用默认`<`运算定义顺序,myvec内元素: (12 32 45 71)26 80 53 33
sort(myvec.begin() + 4, myvec.end(), myfunc); // 使用自定义函数定义顺序,myvec内元素: 12 32 45 71(26 33 53 80)
sort(myvec.begin(), myvec.end(), myobj); // 使用自定义仿函数定义顺序,myvec内元素: (12 26 32 33 45 53 71 80)
sort(myvec.rbegin(), myvec.rend()); // 使用反向迭代器逆向排序,myvec内元素: 80 71 53 45 33 32 26 12
return 0;
}
binary_search
算法binary_search从排好序的区间内查找元素value,支持所有可排序的容器.
算法binary_search内部调用了算法lower_bound,使用二分查找方式查询元素.
算法lower_bound和upper_bound分别返回对应元素的第一个和最后一个可插入位置.

template<class ForwardIterator, class T>
bool binary_search(ForwardIterator first, ForwardIterator last, const T &val) {
first = std::lower_bound(first, last, val); // 内部调用lower_bound
return (first != last && !(val < *first));
}
template<class ForwardIterator, class T>
ForwardIterator lower_bound(ForwardIterator first, ForwardIterator last, const T &val) {
ForwardIterator it;
typename iterator_traits<ForwardIterator>::difference_type count, step;
count = distance(first, last);
while (count > 0) {
it = first;
step = count / 2;
advance(it, step);
if (*it < val) { // or: if (comp(*it,val)) for version (2)
first = ++it;
count -= step + 1;
} else
count = step;
return first;
}
}
5.仿函数
functors是为Algorithm而服务的。functors是一类重载了operator()运算符的class。
让functor可适配(adaptable)的条件,即让functor回答adapter提出的问题,就必须让functor继承自unary_function和binary_function。
template<class Arg,class Result>
struct unary_function{
typedef Arg argument_type
typedef Result result_type
};
template<class Arg1,class Arg2,class Result>
struct binary_function{
typedef Arg1 first_argument_type;
typedef Arg2 second_argument_type;
typedef Result result_type
}
template<class T>
struct greater:public binary_function<T,T,bool>{
bool operator()(const T& x,const T& y)const{
return x>y;
}
}
template<class T>
struct less:public binary_function<T,T,bool>{
bool operator()(const T& x,const T& y)const{
return x<y;
}
}
6.适配器
6.1 容器适配器
- 容器
stack和queue是容器deque的适配器。 - 容器
set、map、multiset、multimap是容器rb_tree的适配器。 - 容器
unordered_set、unordered_map、unordered_multiset、unordered_multimap是容器hashtable的适配器。
6.2 仿函数适配器
binder2nd仿函数适配器可以绑定二元仿函数的第二参数。
测试程序
cout << count_if(vi.begin(),vi.end (),bind2nd(less<int>(), 40));
源代码如下:
template<class Operation,class T>
inline binder2nd<Operation>
bind2nd(const Operation& op,const T& x){
typedef typename Operation::second_argument_type arg2_type //传进来的operation需要基础继承binary_function,才会有second_argument_type
return binder2nd<Operation>(op, arg2_type(x)); //创建binder2nd匿名对象,将op和arg2值存入binder2nd。arg2_type同时也是在发出询问,x与该operation的second_argument_type的类型是否相同。
}
template<class Operation>
class binder2nd:public unary_function<typename Operation::first_argument_type,typename Operation::result_type>
{
protected:
Operation op; //操作
typename Operation::second_argument_type value; //第二实参
public:
//构造函数,记录操作和第二实参
binder2nd(const Operation& x,const typename Operation::second_argument_type& y):op(x),value(y){};
//重载()运算符
typename Operation::result_type
Operator()(const typename Operation::frist_argument_type& x)const{ //在运行时被pred(*first)调用
return op(x,value); //将传入的x作为操作op的第一参数,value作为第二参数,即实现了将bind2nd(op,x)中的x绑定为functor的第二参数的适配操作
}
}
template<class Iterator,class Predicate>
typename iterator_traits<Iterator>::difference_type
count_if(Iterator first,Iterator last,Predicate pred){
typename iterator_traits::difference_type n=0;
for(;first!=last;++first)
if(pred(*first))
++n;
return n;
}
not1取反适配器
测试程序:
//测试程序
cout<<count_if(v1.begin(),v2.end(),not1(bind2nd(less<int>(),50)))
源代码如下:
//辅助函数,使user更方便使用unary_negatebind在C++11中将用于绑定函数参数的类binder1st和binder2nd及其辅助函数bind1st和bind2nd都被替换为功能更强大的bind
函数bind要和命名空间std::placeholders中的占位符_1、_2、_3…等占位符配合使用.bind函数可以绑定:
function、functor(函数和函数对象)member function(成员函数)data member(成员变量)
演示程序如下:
using namespace std::placeholders;
inline double mydividefunc(const double& x, const double& y) {
return x / y;
}
struct mydivideobject {
double a, b;
double operator()() { //member function 有个argument this
return a * b;
}
}myobject;
void bind11Test() {
//binding functions
auto fn_five = bind(mydividefunc, 10, 2); //10/2 5
cout << fn_five()<< "\n";
auto fn_half = bind(mydividefunc, _1, 2); //return x/2
cout << fn_half(10) << "\n"; //5
auto fn_invert = bind(mydividefunc, _2, _1); //return x / y
cout << fn_invert(10, 2) << "\n"; //0.2
auto fn_rounding = bind<int>(mydividefunc, _1, _2); //return int(x/y)
cout << fn_rounding(10, 3) << endl; //3
//binding members
mydivideobject ob{ 10,2 };
auto bound_memfn = bind(&mydivideobject::operator(), _1); //return x.operator()
cout << bound_memfn(ob) << endl; //20
auto bound_memdata = bind(&mydivideobject::a, ob); //return ab.a
cout << bound_memdata() << endl; //10
vector<int>v{ 10,20,30,40,20,10,50,90 };
int n = count_if(v.cbegin(), v.cend(), not1(bind2nd(less<int>(), 50)));
cout << "大于等于50的个数,n=" << n << endl;
auto fn_ = bind(less<int>(), _1, 50);
n = count_if(v.cbegin(), v.cend(), fn_);
cout << "(bind11)小于50的个数,n=" << n << endl;
cout << count_if(v.cbegin(), v.cend(), bind(less<int>(), _1, 50)) << endl;
}
6.3 迭代器适配器
- 逆向迭代器
reverse_iterator

逆向迭代器的方向与原始迭代器相反。逆向迭代器的头(尾)就是正向迭代器的尾(头),所以加减运算也是相反的。
reverse_iterator源码如下:
template<class Iterator>
class reverse_iterator{
protected:
Iterator current //对应的正向迭代器
public:
//逆向迭代器的五种关联类型与正向迭代器相同
typedef typename iterator_traits<Iterator>::iterator_category iterator_category;
typedef typename iterator_traits<Iterator>::value_type value_type;
...
typedef Iterator iterator_type; //正向迭代器类型
typedef reverse_iterator<Iterator> self; //逆向迭代器类型
public:
explicit reverse_iterator(iterator_type x):current(x){};
reverse_iterator(const self& x):current(x.current){};
iterator_type base()const{return current;}
//逆向迭代器取值 : 就是将迭代器视为正向迭代器,退一格再取值
reference operator*()const{
Iterator tmp = current;
return *--tmp;
}
pointer operator->()const{
Iterator tmp = current;
return &(operator*());
}
//逆向迭代其的加运算对应正向迭代器的减运算
self& operator++(){--current;return *this;}
self& operator--(){++current;return *this;}
self operator+(difference_type n){return self(current-n);}
self operator-(difference_type n){return self(current+n);}
}
-
插入迭代器
inserter_interator 用于生成原地插入运算的迭代器,使用
insert_iterator迭代器插入元素时,将原有位置元素向后推。在说到这个迭代器时,我们需要先看一段程序,来引入这个话题。
int myints[] = { 10,20,30,40,50,60,70}; vector<int>myvec(7); copy(myints, myints + 7, myvec.begin());
这里利用
copy函数,将myints中的元素拷贝进myvec中,但通过查看copy源码可知,所谓的拷贝,不过是每次进行赋值。并且这里是预留了7个位置给vector,如果没有预留就进行赋值的话,将会引起一系列的问题。copy源码:template<class InputIterator,class OutputIterator> OutputIterator copy(InputIterator firts,InputIterator last,OutputIterator result) { while(first!=last){ *result=*first; ++result; ++first; } return result; } 所以这里我们引入第二个例子,来说明
insert_iterator的用法:vector<int>foo, bar; for (int i = 1; i <= 5; i++) { foo.push_back(i); bar.push_back(i * 10); } auto ite = foo.begin(); copy(bar.begin(), bar.end(), inserter(foo, ite + 3)); 结果如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4a13KJTE-1638187688131)(C:\Users\zsj\AppData\Roaming\Typora\typora-user-images\image-20210707201552111.png)]](http://img.e-com-net.com/image/info8/731543d0463a42e38079e4cf2eed5922.jpg)
Insert_iterator源码:
//辅助函数,帮助user使用insert_iterator
template<class Container,class Iterator>
inline insert_iterator<Container>
inserter(Container& x,Iterator i){
typedef typename Container::iterator iter;
return insert_iterator<Container>(x,iter(i));
}
template<class Container>
class insert_iterator{
protected:
Container* container; //底层容器
typename Container::iterator iter;//迭代器
public:
typedef output_iterator_tag iterator_type; //迭代器类型
//构造函数,存储容器和迭代器
insert_iterator(Container&x,typename Container::iterator i):container(&x),iter(i){}
insert_iterator<Container>&
operator=(const typename Container::value_type& value){
iter = container->insert(iter,value); //关键 转调用insert()
++iter; //令insert iterator 永远随其target贴身移动
return *this;
}
//重载运算符*和++不做任何动作
insert_iterator<Container> &operator*() { return *this; }
insert_iterator<Container> &operator++() { return *this; }
insert_iterator<Container> &operator++(int) { return *this; }
}
// 所以这里起决定作用的便是重载=运算符
// while(first!=last){
// *result=*first;
// ++result;
// ++first;
- 输出迭代器
ostream_interator
输出流迭代器ostream_iterator常用于封装std::cout.下面程序将容器中元素输出到std::cout中:
vector<int>v;
for (int i = 1; i <= 10; i++)
v.push_back(i * 10);
ostream_iterator<int>out_it(cout, ",");
copy(v.begin(), v.end(), out_it); //10,20,30,40,50,60,70,80,90,100
ostream_iterator源码:
template<class T,
class charT=char,
class traits=char_traits<charT>>
class ostream_iterator:public iterator<output_iterator_tag,void,void,void,void>
{
basic_ostream<charT,traits>* out_stream;
const charT* delim; //间隔符
public:
typedef charT char_type;
typedef traits traits_type;
typedef basic_ostream<charT,traits> ostream_type;
//构造函数
ostream_iterator(ostream_type&s):out_stream(&s),delim(0){}
ostream_iterator(ostream_type&s,const charT* delimiter):out_stream(&s),delim(delimiter){}
ostream_iterator(const ostream_iterator<T,charT,traits>&x):out_stream(x.out_stream),delim(x.delim){}
~ostream_iterator(){}
//operator=重载 关键
ostream_iterator<T,charT,traits>& operator=(const T& value){
*out_stream<<value;
if(delim!=0)
*out_stream<<delim;
return *this;
}
// 重载运算符*和++: 不做任何动作
ostream_iterator<T, charT, traits> &operator*() { return *this; }
ostream_iterator<T, charT, traits> &operator++() { return *this; }
ostream_iterator<T, charT, traits> &operator++(int) { return *this; }
}
- 输入迭代器
istream_interator
输入流迭代器istream_iterator用于封装std::cin,例一:
double val1, val2;
cout << "Please,insert two values:";
istream_iterator<double>eos; //end of string
istream_iterator<double>iit(cin); //相当于cin>>value
if (iit != eos)
val1 = *iit;
++iit;
if (iit != eos)
val2 = *iit;
cout << val1 << "*" << val2 << "=" << (val1 * val2) << endl;
istream_iterator源码:
template<class T,
class charT=char,
class traits=char_traits<charT>,
class Distance=ptrdiff_t>
class istream_iterator:public iterator<input_iterator_tag,T,Distance,const T*,const T&>{
basic_istream<charT,traits>*in_stream;
T value;
public:
typedef charT char_type;
typedef traits traits_type;
typedef basic_istream<charT,traits> istream_type;
//构造函数
istream_iterator():in_stream(0){}
istream_iterator(istream_type&s):in_stream(&s)){++*this;}
istream_iterator(const istream_iterator<T,charT,traits,Distance>&x):in_stream(x.in_stream),valye(x.value){}
~istream_iterator(){};
//operator* ->重载
const T& operator*()const{return value};
const T* operator->()const{return &value};
istream_iterator<T,charT,traits,Distance>&
operator++(){ //一旦创建,便会立即令user输入
if(in_stream&&!(*in_stream>>value))
in_stream=0;
return *this;
}
istream_iterator<T,charT,traits,Distance>
operator++(int){
istream_iterator<T,charT,traits,Distance>temp = *this;
++*this;
return temp;
}
}
例二:
istream_iterator<int>iit(cin),eos;
copy(iit,eos,inserter(c,c.begin()));
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tYqzz1DX-1638187688132)(C:\Users\zsj\AppData\Roaming\Typora\typora-user-images\image-20210707205049571.png)]](http://img.e-com-net.com/image/info8/8366b3648ded41a28054bed706746182.jpg)
7.其他标准库内容
7.1 一个万用的Hash Function
在使用unordered_set\map时我们需要自定义hash function,所谓的hashfunction就是要让生成的hashcode排列越乱越好。那么有没有一种万用的hash function模板呢?
建立hashfunction的方法:
- 1.函数对象
class Customer{
...
}
class CustomerHash{
public:
std:size_t operator()(const Customer& c)const{
return ... //需要自定义
}
}
unordered_set<Customer,CustomerHash> custset
- 2.函数
size_t customer_hash_func(const Customer& c){
return ...//自定义
};
unordered_set<Customer,size_t(*)(const Customer&)>
custset(20,customer_hash_func);
- 3.提供偏特化版本
template< typename T,
typename Hash = hash<t>,
typename Eqpred = equal_to<T>,
typename Allocator = allocator<t>>
class unordered_set;
class MyString{
private:
char* _date;
size_t _len;
...
};
namespace std //必须放在std
{
template<>
struct hash<Mystring> //自己提供的偏特化版本
{
size_t operator()(const Mystring& s)const onexcept
{
return hash<string>()(string(s.get());) //借用hash万能的hashfunction模板
class CustomerHash{
public:
std:size_t operator()(const Customer& c)const{
return hash_val(c.fname,c.lname,c.no);
}
}
//首先被调用的泛化版本
template<typename...Types>
inline size_t hash_val(const Types&...args){
size_t seed = 0;
hash_val(seed,args...);
return seed;
}
template<typename T,typename ...Types>
inline void hash_val(size_t& seed,const T&val,const Types& ...args){
hash_combine(seed,val);
hash_val(seed,args...);
}
template<typename T>
inline void hash_combine(size_t& seed,const T&val){
seed^=std::hash<T>()(val)+0x9e3779b9+(seed<<6)+(seed>>2); //0x9e3779b9为黄金比例
}
template<typename T>
inline void hash_val(size_t& seed,const T& val){
hash_combine(seed,val);
}
7.2 tuple用例
// 创建tuple
tuple<string, int, int, complex<double> > t;
tuple<int, float, string> t1(41, 6.3, "nico"); // 指定初值
auto t2 = make_tuple(22, 44, "stacy"); // 使用make_tuple函数创建tuple
// 使用get<>()函数获取tuple内的元素
cout << "t1:" << get<0>(t1) << "<< get<1>(t1)<<" << get<2>(t1) << endl;
get<1>(t1) = get<1>(t2); // 获取的元素是左值,可以对其赋值
// tuple可以直接进行比较
if (t1 < t2) {
cout << "t1 < t2" << endl;
} else {
cout << "t1 >= t2" << endl;
}
// 可以直接拷贝构造
t1 = t2;
// 使用tie函数将tuple的元素绑定到变量上
tuple<int, float, string> t3(77, 1.1, "more light");
int i1, float f1; string s1;
tie(i1, f1, s1) = t3;
// 推断 tuple 类型
typedef decltype(t3) TupleType; // 推断出 t3 的类型为 tupletuple源码分析
// 定义 tuple类
template<typename... Values>
class tuple;
// 特化模板参数: 空参
template<>
class tuple<> {};
// 特化模板参数
template<typename Head, typename... Tail>
class tuple<Head, Tail...> :
private tuple<Tail...> // tuple类继承自tuple类,父类比子类少了一个模板参数
{
typedef tuple<Tail...> inherited; // 父类类型
protected:
Head m_head; // 保存第一个元素的值
public:
tuple() {}
tuple(Head v, Tail... vtail) // 构造函数: 将第一个元素赋值给m_head,使用其他元素构建父类tuple
: m_head(v), inherited(vtail...) {}
Head head() { return m_head; } // 返回第一个元素值
inherited& tail() { return *this; } // 返回剩余元素组成的tuple(将当前元素强制转换为父类类型)
};
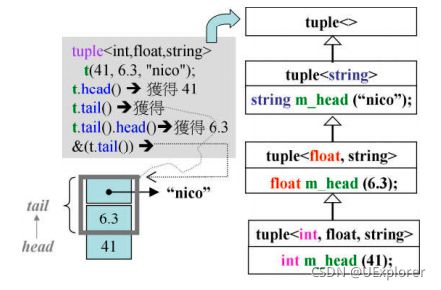
调用head函数返回的是元素m_head的值.
调用tail函数返回父类成分的起点,通过强制转换将当前tuple转换为父类tuple,丢弃了元素m_head所占内存.
7.3 type traits
类型萃取机制type traits获取与类有关的信息,在C++11之前和C++11种分别有不同的实现方式。
C++11之前
在C++11之前,typetraits是由__type_traits实现,我们每创建一个类,就要以该类为模板参数特化一个__type_traits类
template<class type>
struct __type_traits{
typedef __false_type has_trivial_default_constructor; //默认构造函数是否可忽略
typedef __false_type has_trivial_copy_constructor; //拷贝构造函数是否可忽略
typedef __false_type has_trivial_assignment_operator; //赋值函数是否可忽略
typedef __false_type has_trivial_destructor; //析构函数是否可忽略
typedef __false_type is_POD_type //是否为POD(plain old data)类型
};
template<>
struct __type_traits<int>{
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};
template<>
struct __type_traits<double> {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};
C++11
C++11在头文件type_traits中引入了一系列辅助类,这些辅助类能根据传入的模板参数自动进行获取该类的基本信息,实现类型萃取,并不需要我们为自己创建的类手动编写类型萃取信息。
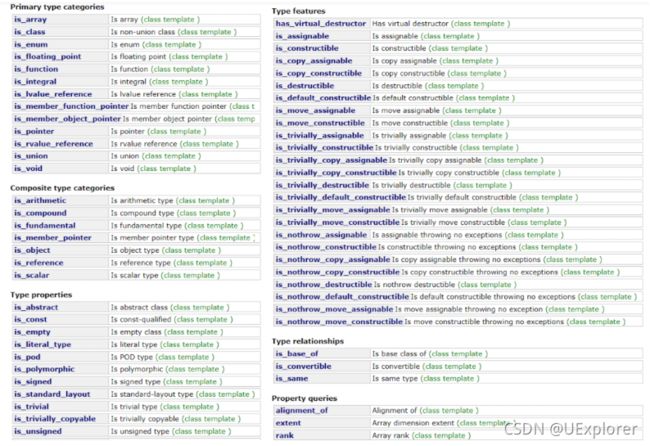
下面例子展示类型萃取机制的应用:
cout << "is_ void\t" << is_void<T>::value << endl;
cout << "is_ integral\t" << is_integral<T>::value << endl;
cout << "is_ floating point\t" << is_floating_point<T>::value << endl;
...
- 源码分析
头文件type_traits中定义了辅助类remove_const和remove_volatile用于除去类型中的const和volatile关键字.
// remove const
template<typename _Tp>
struct remove_const {
typedef _Tp type;
};
template<typename _Tp>
struct remove_const<_Tp const> {
typedef _Tp type;
};
// remove volatile
template<typename _Tp>
struct remove_volatile {
typedef _Tp type;
};
template<typename _Tp>
struct remove_volatile<_Tp volatile> {
typedef _Tp type;
};
is_void类继承自__is_void_helper类,__is_void_helper类使用偏特化的形式判断传入的模板参数是否为void.
template<typename>
struct __is_void_helper
: public false_type {
};
template<>
struct __is_void_helper<void>
: public true_type {
};
template<typename _Tp>
struct is_void
: public __is_void_helper<typename remove_cv<_Tp>::type>::type {
};
is_integral类继承自__is_integral_helper类,同样使用偏特化的方式判断传入的模板参数是否为整数类型
template<typename>
struct __is_integral_helper : public false_type { };
template<> struct __is_integral_helper<bool> : public true_type { };
template<> struct __is_integral_helper<char> : public true_type { };
template<> struct __is_integral_helper<signed char> : public true_type { };
template<> struct __is_integral_helper<unsigned char> : public true_type { };
// ...
template<typename _Tp>
struct is_integral
: public __is_integral_helper<typename remove_cv<_Tp>::type>::type { };
一些type traits辅助类(如is_enum、is_union和is_class等)是由编译器实现的,STL源码中找不到其实现函数.
// is_enum
template<typename _Tp>
struct is_enum
: public integral_constant<bool, __is_enum(_Tp)> // __is_enum函数是由编译器实现的,STL源码中找不到其源码
{ };
// is_union
template<typename _Tp>
struct is_union
: public integral_constant<bool, __is_union(_Tp)> // __is_union函数是由编译器实现的,STL源码中找不到其源码
{ };
// is_class
template<typename _Tp>
struct is_class
: public integral_constant<bool, __is_class(_Tp)> // __is_class函数是由编译器实现的,STL源码中找不到其源码
{ };
7.4 cout
cout为什么能输出多种数据类型?cout是一个类还是一个对象?
G2.9 iostream.h
class _IO_ostream_withassign:public ostream{
public:
_IO_ostream_withassign& operator=(ostream&);
_IO_ostream_withassign& operator=(_IO_ostream_withassign& rhs){
return operator=(static_cast<ostream&>(rhs));
};
extern _IO_ostream_withassign cout; //cout是一个对象
}
class ostream:virtual public ios
{
public:
ostream& operator<<(char c);
ostream& operator<<(unsigned char c){return (*this)<<(char)c;}
ostream& operator<<(signed char c){return (*this)<<(char)c;}
ostream& operator<<(const char* s);
ostream& operator<<(const unsigned char* c){return (*this)<<(const char*)s;}
ostream& operator<<(const signed char* c){return (*this)<<(const char*)s;}
ostream& operator<<(int n);
ostream& operator<<(unsigned int n);
ostream& operator<<(long n);
ostream& operator<<(unsigned long n);
...
}