A Survey of the Usages of Deep Learning for Natural Language Processing2019综述学习
A Survey of the Usages of Deep Learning for Natural Language Processing2019综述学习
- 1.介绍
- 2.自然语言处理和深度学习
-
- 2.1自然语言处理
- 2.2神经网络和深度学习
-
- 2.2.1 CNN
- 2.2.2递归神经网络
- 2.2.3循环神经网络和LSTM
- 2.2.4注意力机制和transformer
- 2.2.5 残差连接和dropout
- 3.深度学习用于NLP的核心领域
-
- 3.1语言模型
-
- 3.1.1 神经语言模型
- 3.1.2评估LM
- 3.1.3LM中的记忆网络和注意力机制
- 3.1.4 CNN用于LM
- 3.1.5 Character Aware Neural Language Models
- 3.1.6 词嵌入的发展
- 3.1.7最近发展和挑战
- 3.2 形态学
- 3.3 句法解析
-
- 3.3.1 Early Neural Parsing
- 3.3.2Transition-Based Dependency Parsing
- 3.3.3 Generative Dependency and Constituent Parsing生成依赖与主成分分析
- 3.3.4 Universal Parsing
- 3.3.5存在的挑战
- 3.4 语义学
-
- 3.4.1 Semantic Comparison
- 3.4.2 句子模型
- 3.4.3 语义学挑战
- 3.5 总结核心问题
- 4.在NLP领域应用DL
-
- 4.1 信息检索
- 4.2 信息抽取
-
- 4.2.1Named Entity Recognition(NER)
- 4.2.2 Event Extraction
- 4.2.3 Relationship Extraction
- 4.3 文本分类
- 4.4 文本生成
-
- 4.4.1 Poetry Generation
- 4.4.2 Joke and Pun Generation
- 4.4.3 Story Generation
- 4.4.4 Text Generation with GANs
- 4.4.5 Text Generation with VAEs
- 4.4.6 Summary of Text Generation
- 4.5 总结
- 4.6 问答系统
- 4.7 机器翻译
- 4.8 总结深度学习在NLP领域中的应用
- 5.总结
这篇论文的特点在于将NLP的领域分类较好,算法都是讲的怎么用的(都是CNN、RNN变形和bert),没有讲原理,没有一个公式。作为NLP入门了解一些专业词汇很好。
摘要
在过去的几年里,随着深度学习模型的大量使用,自然语言处理领域得到了极大的发展。本调查对该领域进行了简要介绍,并简要概述了深度学习体系结构和方法。然后,它筛选了大量最近的研究,并总结了大量相关的贡献。分析的研究领域除了计算语言学的一些应用外,还包括几个核心的语言处理问题。并对今后的研究提出了建议。
关键词
深度学习,神经网络,自然语言处理,计算语言学,机器学习
1.介绍
以前方法:统计学、概率论、机器学习
有了GPU之后
现在方法:深度学习
本文主要介绍NLP和深度学习。第二章AL和NLP理论;
第三章NLP的四个主要问题:语言模型、形态学、句法分析、语义,以及DL在其中的应用;
第四章NLP的应用领域:信息检索、信息抽取、文本分类、文本生成、总结、问答系统、机器翻译;
第五章结论,未来展望。
2.自然语言处理和深度学习
2.1自然语言处理
NLP两个大的子领域:核心领域和应用
核心领域:语言模型、形态学、句法分析、语义(+一句话介绍每部分是干什么的)注意:很多有交叉
应用:信息检索、信息抽取、文本分类、文本生成、总结、问答系统、机器翻译
以前机器学习的方法:朴素贝叶斯、KNN、隐马尔可夫、条件随机场、决策树、随机森林、支持向量机。
最近几年用于NLP的方法:transformer。
2.2神经网络和深度学习
神经网络、随机梯度下降、反向传播、前馈神经网络(FFNN)、深度神经网络(DNN)
2.2.1 CNN
CNN被用于图片处理、视频处理、语音处理和自然语言处理
池化可以减小
2.2.2递归神经网络
递归神经网络Recursive Neural Networks
CNN同一层之间共享权重,而RNN是不同层之间共享权重
2.2.3循环神经网络和LSTM
循环神经网络: Recurrent Neural Networks
LSTM:Long Short-Term Memory Networks
循环神经网络是递归神经网络的一种
因为RNN是单向的,而单词之间的关系是双向的,因此有了 双向RNN(bidirectional RNN)
工程化应用广泛的一种RNN是LSTM
一种轻量化的LSTM变体是GRU( Gated Recurrent Unit)
2.2.4注意力机制和transformer
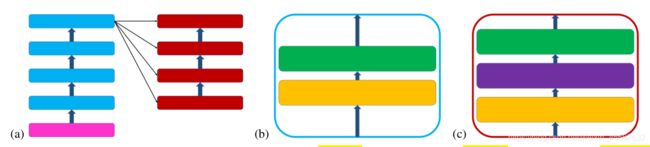 上图是transformer模型。其中a图中,四个蓝色编码器和四个红色解码器,编码器前面有一个positional encoder(粉红色)。b 图和c图对应的是a图内部结构,其中b是编码器内部结构,c 是解码器内部结构。编码器中一个self-attention layer,一个feed forward layer。解码器中一个 self-attention layer,一个attentional encoder-decoder layer,一个feed forward layer。
上图是transformer模型。其中a图中,四个蓝色编码器和四个红色解码器,编码器前面有一个positional encoder(粉红色)。b 图和c图对应的是a图内部结构,其中b是编码器内部结构,c 是解码器内部结构。编码器中一个self-attention layer,一个feed forward layer。解码器中一个 self-attention layer,一个attentional encoder-decoder layer,一个feed forward layer。
原来RNN的问题:不关注哪个重要哪个不重要,全部从编码器到解码器。
因此有了attention机制。
attention 机制的一些变体:convolutional , intra-temporal , gated , and self-attention
Self-attention in particular has become widely used in a state-of-the-art encoder-decoder model called Transformer。
2.2.5 残差连接和dropout
防止梯度爆炸和梯度消失的方法:
1.选择合适的激活函数,推荐relu
2.残差连接,网络举例: residual network (ResNet)
一些变体: Highway Networks and DenseNets .
3.dropout:防止训练数据过拟合
3.深度学习用于NLP的核心领域
主要分为四个部分:语言模型、形态学、句法分析、语
义学
语言模型决定哪个词与哪个词连接
形态学研究词本身的结构,词根前缀后缀,性别数字等。
句法分析词怎么构成句子
语义学研究每个词的意思以及怎么构成句子。

3.1语言模型
Language modeling (LM)
3.1.1 神经语言模型
可以识别同义词和词汇表外词
3.1.2评估LM
目前没有完美的方法,有一个度量指标是困惑度(perplexity)
困惑度的一个缺点是只能在同一个数据集上进行比较,多个数据集之间没有意义。
这个领域常用数据集:Penn Treebank (PTB) [54], and the Billion Word Benchmark
3.1.3LM中的记忆网络和注意力机制
1.运用注意力机制的网络变形三次递进尝试
1) a single value to predict the next token, to encode information for the attentional unit, and to decode the information in the attentional unit hinders a network
问题:difficult to train a single parameter to perform three distinct tasks simultaneously
2)designed each node to have two outputs: one to encode and decode the information in the attentional unit, and another to predict the next tokens explicitly
3)further separated the outputs, using separate values to encode the information entering the attentional unit and decode the information being retrieved from it
It was found that this network also provided results comparable to many larger RNNs and LSTMs, suggesting that reasonable results can be achieved using simpler networks.
2.近期 residual memory networks (RMNs) for LM
注意:residual connections skipping two layers were most effective
It was found that RMNs are capable of outperforming LSTMs of similar size.
3.1.4 CNN用于LM
A CNN used recently in LM replaced the pooling layers with fully-connected layers
Three different architectures were implemented:
1)a multilayer perceptron CNN (MLPConv)
2) a multilayer CNN (ML-CNN)
3) a combination of these networks called COM
this study showed that CNNs can be used to capture long term dependencies in sentences.
3.1.5 Character Aware Neural Language Models
unlike previous networks , accepted only character level input, rather than combining it with word embeddings.
1.CNN
2.LSTM, 19 million trainable parameters
Since the network focused on morphological similarities produced by character level analysis, it was more capable than previous models of handling rare words.
The analysis also showed that the network was capable of identifying prefixes, roots, and suffixes, as well as understanding hyphenated words, making it a robust model.
这个模型不仅仅是应用于LM,还可以形态学分析。
3.很多人在小数据集上验证比较不同模型。这个实验在 Billion Word Benchmark大数据集上验证, The best performance,however, was achieved using an ensemble of ten LSTMs。
3.1.6 词嵌入的发展
Not only do neural language models allow for the prediction of unseen synonymous words, they also allow for modeling the relationships between words.
PCA:Principle Component Analysis
King向量-queen向量 约等于 man向量-woman向量
3.1.7最近发展和挑战
发展:
1.生成性预训练Generative Pre-Training (GPT)
which pretrained a language model based on the Transformer model learning dependencies of words in sentences and longer segments of text, rather than just the immediately surrounding words.
2. bi-directionalism to capture backwards context in addition to the forward context, in their Embeddings from Language Models (ELMo)
captured the vectorizations at multiple levels
3.unsupervised training tasks of random masked neighbor word prediction, and next-sentence-prediction (NSP)。Bidirectional Encoder Representations from Transformers (BERT)
4. Multi-Task Deep Neural Network (MT-DNN)
5.used a stochastic answer network (SAN) ontop of a BERT-like model.
挑战:
When new datasets are created removing such patterns carefully, the models do not perform well.
Additionally, while there has been recent work on cross-language modeling and universal language modeling, the amount and level of work needs to pick up to address low-resource languages.
3.2 形态学
Morphology is concerned with finding segments within
single words, including roots and stems, prefixes, suffixes, and—in some languages—infixes.
1.模型:RvNN,数据集: WordSim-353 dataset
In particular, words with the same stem were clustered together, even if they were antonyms.
2. LSTM-based models、 character aware CNNs
a variety of neural machine translation models.
from English to French, German, Czech, Arabic, or Hebrew.
The study concluded that the use of attention mechanisms decreases the performance of encoders, but increases the performance of decoders.
Furthermore, it was found that character-aware models are superior to others for learning morphology
3.RNN-based model
unsegmented(非分歧) languages such as Japanese
数据集: the Kyoto Text Corpus and the Kyoto University Web Document Leads Corpus
4.最近的工作是通用形态学universal morphology
a single study applying deep learning to this area
apply deep learning to this task
5.形态学嵌入可以很好地应用到多语言处理
3.3 句法解析
主要分为两种形式: constituency parsing and dependency parsing
In constituency parsing, phrasal constituents are extracted from a sentence in a hierarchical fashion.
Dependency parsing looks at the relationships between pairs of individual words.
1.Most recent uses of deep learning in parsing have been in dependency parsing
2. Graph-based parsing constructs a number of parse trees that are then searched to find the correct one.
3. Most graph-based approaches are generative models
4. More popular in recent years than graph-based approaches have been transition-based approaches
5. the standard method of transition-based dependency parsing:1) arc-standard approach
2) arc-eager approach
3) swap-lazy approach
3.3.1 Early Neural Parsing
1.RNNs with probabilistic context-free grammars
(PCFGs)上下文无关文法
2. labeled attachment score (LAS) and unlabeled attachment score (UAS) by using an Inside-Out Recursive Neural Network
3. LSTM with an attention mechanism in a syntactic
constituency parser
4. Embeddings were first used in dependency parsing
数据集: the Wall Street Journal portion of the CoNLL
3.3.2Transition-Based Dependency Parsing
1.简单前馈神经网络
2.简单贪婪搜索——光束搜索
3.深度神经网络
4. using tri-training
5. 另外一种替代简单前馈神经网络方式:LSTM
数据集: the Stanford Dependency Treebank
the CTB5 Chinese dataset
6. a feedforward network with global normalization
7. two new LSTM-based techniques: Bi-LSTM Subtraction and Incremental Tree-LSTM
数据集: SemEval-2015 Task 18(English)
SemEval-2016 Task 9 (Chinese)
3.3.3 Generative Dependency and Constituent Parsing生成依赖与主成分分析
- recurrent neural network
Whereas most approaches take a bottom-up approach to parsing, this took a top-down approach
This allowed the sentence to be viewed as a whole
最佳: in English generative parsing
接近最佳: in Chinese generative parsing. - LSTM to assign probabilities to the parse trees
结论:They found that while using one parser for producing candidate trees and another for ranking them was superior to a single parser approach, combining two parsers explicitly was preferable.
数据集: Penn Treebank - a self-attentive network
- active learning
3.3.4 Universal Parsing
While current parsing varies drastically from language to language, this attempts to make it uniform between them.
任务: a CoNLL shared task
这个任务对应的方法:deep transition parsing [127], graphbased neural parsing [128], and a competitive model .
bidirectional LSTM
3.3.5存在的挑战
挑战:building of syntactic structures without the use of treebanks for training
3.4 语义学
词嵌入的一些方法:Word2Vec、 GloVe
3.4.1 Semantic Comparison
One way to test the efficacy of an approach to computing semantics is to see if two similar phrases, sentences or documents, judged by humans to have similar meaning also are judged similarly by a program.
- two CNNs,The approach outperformed a number of existing models in tasks in English and Chinese.
- Bi-CNN-MI(MI for multigranular interaction features)
- Dynamic CNNs
数据集: Microsoft Research Paraphrase Corpus (MSRP)
4.using a “similarity measurement layer” followed by a fully-connected layer and then a log-softmax output layer within a CNN
数据集: MSRP, the Sentences Involving Compositional Knowledge (SICK) dataset [138], and the Microsoft Video Paraphrase Corpus (MSRVID)
5.RvNN with LSTM-like nodes called a Tree-LSTM
数据集: SICK dataset and Stanford Sentiment Treebank
6.The model formed a matrix of the two sentences before applying a “similarity focus layer” and then a nineteen-layer CNN followed by dense layers with a softmax output.
数据集:MSRVID, SemEval 2014 Task 10
, WikiQA , and TreeQA datasets.
3.4.2 句子模型
- attempt to model paragraphs or larger bodies of text in this way
- dynamic convolutional neural network (DCNN)
数据集:Stanford Sentiment Treebank、tweets、 TREC database - typical encoder–decoder structure they use, neural machine translation (NMT) systems.
数据集:Multi-NLI 、JHU Decompositional Semantics Initiative
None of the results were particularly strong, although they were strongest in SPR
4.training semantic parsers on a single domain, as is often done, is less effective than training across many domains.
5.three LSTM-based models:
一对一、一对多、多对多
数据集:” OVERNIGHT ” dataset
6.several LSTM-based encoder–decoder networks
数据集: EuroParl dataset
结论:1)adding more decoders led to more correct and more definitive clusters.
2)can it be performed on sentence embeddings.
3.4.3 语义学挑战
可以很好的完成任务并不代表真正的理解
整合深度神经网络和general word-graphs (e.g. WordNet )or knowledge-graphs (e.g. DBPedia)可能对理解有帮助。
图嵌入是活跃的研究领域,整合语言模型和图模型将对更好的机器理解有帮助。
3.5 总结核心问题
虽然用上了DL,但是很多问题都不是很明确
4.在NLP领域应用DL
注意:这里的NLP只是文本的处理,不包括声学处理
4.1 信息检索

Publication Volume for Applied Areas of NLP
1.Deep learning models for ad-hoc retrieval match texts of queries to texts of documents to obtain relevance scores.
A.representation-focused approaches
match the representations straightforwardly
B.interaction-focused approaches
first build local interactions directly, and then use deep neural networks to learn how the two pieces of text match based on word interactions
2.DRMM
3.SNRM_PRF
learned sparse representations(稀疏) for both queries and documents
In particular, an n-gram representation for queries and documents was used.
TF-IDF and BM25
数据集:measured by MAP, P@20, nDCG@20, and Recall、 Robust and ClueWeb
4.目的:extracted query term representations
ELMo and BERT、 DRMM、CEDR (Contextualized Embeddings for Document Ranking)(基于文档排序的上下文嵌入)
4.2 信息抽取
主要有三种类型:命名实体和关系、事件及参与者、时态信息和事实元组
4.2.1Named Entity Recognition(NER)
1.a simple feedforward network
difficult to capture long-distance relations between words
2.LSTMs
a deep neural network architecture, known as CharWNN, which jointly used word-level and character-level inputs to perform sequential classification.
数据集: HAREM I annotated Portuguese corpus、 SPA CoNLL2002 annotated Spanish corpus
结论:This revalidated a fact long-known: Joint use of word-level and character-level features is important to effective NER performance.
3.bidirectional LSTM with a character-level CNN
数据集:CoNLL-2003、OntoNotes
4.based on bidirectional LSTMs and conditional random fields (CRFs)(条件随机场)
5. a pre-trained bidirectional character language model
4.2.2 Event Extraction
four sub-tasks:
1)identifying event mentions
2) identifying event triggers事件触发器
3) identifying arguments of the events确定事实论据
4)identifying arguments’ roles确定论点在事件中作用
1.CNNs
缺点: capture only the most important information in
a sentence
改进:divided the feature map into three parts,
and instead of using one maximum value, kept the maximum value of each part.
2. RNN-based encoder–decoder
3. a latent variable neural model
数据集: on a dataset they created and released自己的数据集
4.2.3 Relationship Extraction
这些关系包含:拥有关系、同义关系、反义关系
自然的、家族的、地理的关系
1.a simple CNN
2. a bidirectional LSTM and a CNN
3.attention-based GRU model
4.BERT model with supervised training
数据集:biomedical dataset.生物医学数据集
4.3 文本分类
1.use pretrained word vectors in a CNN
achieve excellent results on multiple benchmarks
using little hyperparameter tuning.超参数调节
结论:
The CNN models proposed were able to improve upon the state of the art on 4 out of 7 different tasks cast as sentence classification, including sentiment analysis and question classification.
2. a large number of convolutional layers
3. a hybrid architecture combining a deep belief network [193] and softmax regression
4. deep neural net with backpropagation and quasi-Newton methods
5.BERT
6. for the task of classifying long full-length books by genre, gradient boosting trees are superior to neural networks, including both CNNs and LSTMs.
4.4 文本生成
文本生成的分类:
1)文本到文本;2)非文本到文本;3)无任何输入(诗歌生成、笑话、故事)
4.4.1 Poetry Generation
while recurrent networks are great at learning
internal language models, they do a poor job of producing structured output or adhering to any single style.
RNN在学习语言模型内部结构中较好,但是在生成结构化输出或坚持单一风格上面较差。
1.addressed the style issue by training using particular
poets and controlling for style in Chinese poetry.
2.generated rhythmic poetry by training the network on only a single type of poem to ensure produced poems
3.今年(2019年)GPT-2 model
又称 774 million parameter GPT-2 model
数据集:
on a large English corpus,可以扩展到其他语种
4.4.2 Joke and Pun Generation
1.a small LSTM
did a poor job of making the puns humorous
其他都是一样的方法,就是在不同数据集实验
结论:
providing more general knowledge of other types
of language, and examples of non-jokes, increased the quality of the jokes produced.
4.4.3 Story Generation
1.RNN
2. LSTMs
3.最近的研究关注点:
focusing on the “events” (or actions) in the stories or on the entities (characters and important objects)
4.“skeleton” based model
build general sentences and fill in important information
缺点: still provided only modest end results in human evaluation
5. a two-tiered network
6. hierarchical approach, based on CNNs
结论:self attention leads to better perplexity.
7. read documents in a hierarchical fashion and reproduced them in hierarchical fashion
4.4.4 Text Generation with GANs
1.GANs (generative adversarial networks)生成对抗网络
RankGAN
2.reinforcement learning
3.textGAN
employing an LSTM generator and a CNN discriminator, achieving a promising BLEU score and a high tendency to reproduce realistic-looking sentences.
总结:Generative adversarial networks have seen increasing use in text generation recently.
4.4.5 Text Generation with VAEs
variational autoencoder (VAE)变分自动编码器
GAN从实际样本中产生输出
VAEs从训练集中产生输出
4.4.6 Summary of Text Generation
1.coherence is still a major problem, especially for longer stories.连贯性是问题,尤其在长故事里面
目前解决: GPT-2 model
2.度量:automatic evaluation of generated text
4.5 总结
There are two primary types of summarization: extractive and abstractive.
注意:这里的总结是NLP的一种方法,不是本章的总结呀!!!
1.deep learning to summarization
a generative beam search decoder
2.attention mechanisms
3.a multiple intra-temporal attention encoder mechanism
4.reinforcement learning
supervised learning
fully convolutional model
5.implemented an attention mechanism for each layer.
6.generated an output sequence based on an input sequence in a two-stage manner.
7.bert
数据集: CNN/Daily Mail and New York Times datasets.
4.6 问答系统
1.a gated attention-based recurrent
network
2.Multicolumn CNNs
3.relational networks (RNs)
4.BERT
数据集: SQuAD 1.1 and SQuAD 2.0 datasets
4.7 机器翻译
neural machine translation (NMT)
1.encoder-decoder models
2.RNN
3.Gated recurrent cells
4. conditional GRU (cGRU)
5.attention mechanisms
6.BERT
对以上一些算法做出如下总结:
1.While neural machine translation models are superior to other forms of statistical machine translation models (as well as rule-based models), they require significantly more data, perform poorly outside of the domain in which they are trained, fail to handle rare words adequately, and do not do well with long sentences (more than about sixty words).
神经机器翻译比其他的统计学机器翻译效果好,但是神经机器翻译需要跟多的数据,超出训练域的表现较为不好,对稀有单词效果也不好,对长的句子效果也不好。
2.Furthermore, attention mechanisms do not perform as well as their statistical counterparts for aligning words, and beam searches used for decoding only work when the search space is small.
此外,注意机制在对齐单词方面的表现不如统计机制,用于解码的波束搜索仅在搜索空间较小时起作用。