基于Python的医疗花费预测
资源下载地址:https://download.csdn.net/download/sheziqiong/85837039
资源下载地址:https://download.csdn.net/download/sheziqiong/85837039
医疗花费预测
方法介绍
分别通过全手写不调包实现随机森林、全手写不调包实现线性回归、借助 scikit-learn 包实现 GBDT、SVR、LassoRegression、决策树模型来求解该问题,使用 randomizedSearchCV、GridSearchCV、手动调参三种方式进行模型调参,并对 RandomForest、GBDT、DecisionTree、SVR、LinerRegression 模型进行了模型融合,模型融合时尝试使用了直接平均法、加权平均法、stacking 堆叠法进行,同时使用 K 折交叉验证、留一法等多种方法进行模型评判。
方法实现细节和模型结构
数据处理和特征工程
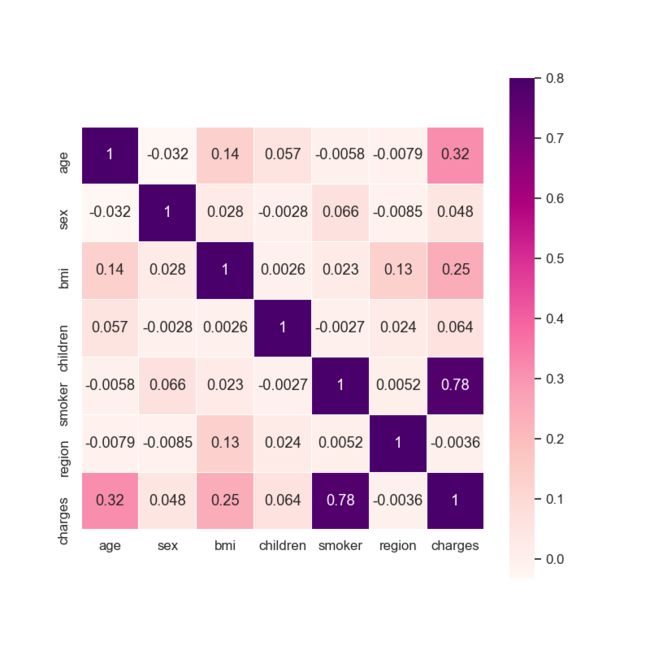
读入数据集以后,通过 describe 方法观察是否数据的大概情况,使用 isnull().sum()方法观察发现数据中不存在空值。测试集较小,仅 1070 行,由于需要尽可能地利用数据,无需舍去数据、无需采样。但在进行检查时发现,数据中存在相同值。通过将数据中 sex、smoker、bmi、age、region、children 属性均相同,且 charges 不同的数据输出如下:

![]()
![]()
通过训练一个准确率较高的基本模型(此处选取随机森林),使用模型来对这些重复数据的特征进行训练。将 charges 与模型预测结果差别较大的值当做异常值舍去。
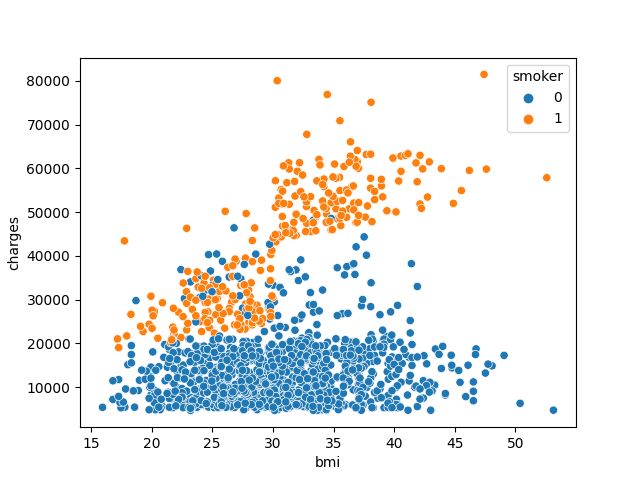
对数据做一些可视化容易得知,bmi 对于 charges 的影响大小,与是否吸烟密切相关。吸烟与否,bmi 对于是否 charges 的影响不同,不吸烟时 charges 整体较小,吸烟时,当 bmi 小于 30 时 charges 较小,当 bmi 大于 30 时 charges 较大。由于该题特征较少数据量也并不大,故考虑将 bmi 与 smoker 融合生成一个新的特征 smoker_bmi。当 smoker 为 0 时,smoker_bmi 也为 0;当 smoker 为 1,bmi 小于 30 时,smoker_bmi 为 1;当 smoker 为 1,bmi 大于 30 时,smoker_bmi 为 2。
将 sex、region、smoker 的标签值转为 int 型,便于训练。

全手写不调包实现随机森林
首先定义一个决策树的结点类,便于随机森林中建树。决策树结点类共包含五个属性,分别表示该结点的分割特征、分割的阈值、左孩子和右孩子、叶子结点的值(仅当该结点为叶子结点时有效)。同时定义一个方法用于查询某个数据对应的叶子结点值。

接下来定义随机森林类,该类使用了和 sklearn 里 RandomForestRegressor 库一样的接口,便于使用。共包含 7 个参数、tree 属性和 feature_importances 属性,fit 方法用于训练模型,build_tree 方法用于在训练模型时建立决策树,choose_best_feature 用于在建立决策树时选择最合适的特征进行分裂,predict 为模型预测。参数一共包含 7 个,其中 n_estimators 为决策树的数量,默认为 100;max_depth 为决策树最大深度限制,默认为-1,即不限制决策树最大深度;min_samples_split 为决策树分裂时所需要的最小样本数,默认为 2;min_samples_leaf 为叶子结点的最少样本数,默认为 1;max_features 为特征的采样方式,有 None,sqrt,log2 三种,当选择 sqrt 时,选择的特征数为 int(len(X.columns) ** 0.5);当选择 log2 时,选择的特征数为 int(math.log(len(X.columns)))。默认为 None,即使用所有特征,不采样。mRadio 为行采样比例,默认为 0.8。random_state 为随机数种子,默认为 None。
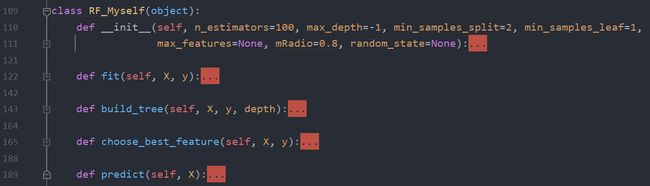
在 fit 方法中,在行采样和列采样后,进行循环建树。通过调用 build_tree 方法,循环建立 n_estimators 棵决策树,并加决策树加入 tree 队列中。在 build_tree 方法中,只要满足分裂条件(即当前样本数量大于 min_samples_split、分裂后叶子结点样本数量大于 min_samples_leaf,决策树深度小于 max_depth),就调用 choose_best_feature 方法选择最合适的特征并选取分裂阈值进行分裂,同时继续递归调用 build_tree。在 choose_best_feature 方法中,通过计算信息增益,选择信息增益最大的特征及阈值并返回,同时会记录选择的特征,并使该特征的重要程度加一,便于记录特征的重要性。
模型建立完成以后,可通过调用 predict 方法进行预测。在 predict 方法中,会对 tree 序列中的每一个决策树进行调用,将每一棵树的结果取平均值,作为随机森林的预测结果。
通过循环遍历参数,选择出合适的参数后,手写实现的随机森林最高能达到 0.845 的评分。
![]()
全手写不调包实现线性回归
模型表达式为:
![]()
参数的迭代更新公式为:
![]()
![]()
对模型进行 5000 次迭代,同时将学习率设置为 0.05。

此外,还需要对数据进行归一化:
![]()
对数据进行了归一化以后,整个数据集上的梯度分布能得到改良,有利于进行线性回归建模。在进行调参以后,手写实现线性回归能达到的最佳分数为 0.746
![]()
借助 scikit-learn 包实现 GBDT、SVR、LassoRegression、决策树
sklearn 包实现 GBDT、SVR、LassoRegression、决策树模型,均只需要直接调用模型即可,实现过程较为简单。
对于 GBDT 而言,调用 sklearn 包中的 GradientBoostingRegressor 库进行训练,在经过调参以后 GBDT 模型准确率能达到 0.860。
![]()
对于 SVR 而言,调用 sklearn 包中的 SVR()库进行训练,在经过调参以后 SVR 模型准确率能达到 0.848。
![]()
对于 LassoRegression 而言,调用 sklearn 包中的 Lasso()模型后,在经过调参以后准确率能达到 0.742,模型准确率并不高。
![]()
对于决策树模型,调用 sklearn 包中的 DecisionTreeRegresso 方法进行训练,在经过调参以后准确率能达到 0.848。
![]()
模型融合——直接平均
在各个模型实现以后,几个主要模型验证集上预测结果的均方误差如下所示:
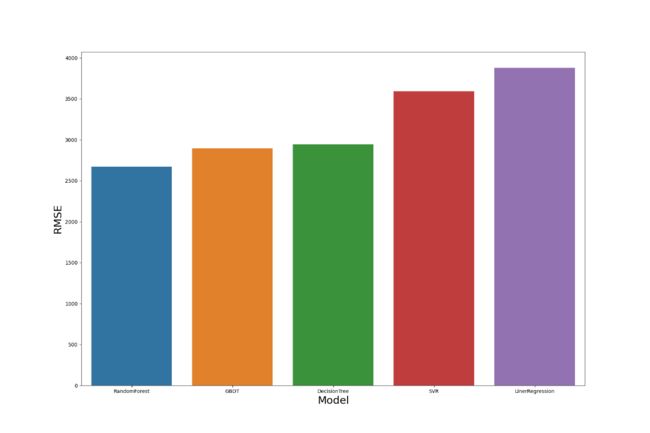
故在进行模型融合时,融合 RandomForest、GBDT、DecisionTree、SVR、LinerRegression。取上述模型评分最高的一次预测结果,进行直接平均后输出。出人意料地,最终结果评分仅有 0.82。
模型融合——加权平均及改进尝试
按照加权平均的思想,把各个模型按照性能排名,分别为 RandomForest、GBDT、DecisionTree、SVR、LinerRegression 模型赋予 5、4、3、2、1 的权重,对各个模型进行加权平均,输出结果,而该结果仍旧低于五个模型中评分最高的 randomforest 模型,仅有 0.85 左右的评分。
对原因进行探究时发现,相似的模型家家相似,而不同的模型非常不同。如果某个模型预测值与正确值相差过大,则会导致整个预测结果受其影响,虽然进行了加权平均,但也依旧无法抵消这种影响。例如,其余四个模型的预测结果均为 8000 左右,但另一个模型预测结果为 20000,则会导致结果误差较大。
故尝试对模型融合进行改进,根据查阅得到的方法知,对于五个模型融合时,如果某一个模型的预测结果与五个模型预测结果均值的差异在自身 25% 以上时,就舍去该值不进行模型融合,并重新计算均值结果。

模型融合——stacking 堆叠法
将模型分为两层,第一层初级学习器包括 GBDT、线性回归、支持向量机和决策树四种模型,使用这四种模型分别去训练,并将这四种模型在训练集上的输出作为次级学习器的输入,将训练集的 charges 作为次级学习器的结果,去训练次级学习器,其中次级学习器为 randomforest。在进行测试时,分别用上述四个模型去跑测试集的输入,并将其预测结果作为随机森林的输入进行预测。最终随机森林的预测结果即为输出。通过 stacking 模型融合的效果是最好的。

调参过程与模型评判
randomizedSearchCV、GridSearchCV 进行自动调参
使用 randomizedSearchCV、GridSearchCV 进行自动调参。
例如使用 randomizedSearchCV 对 GBDT 进行调参时,调节的参数有 n_estimators、max_depth、min_samples_split、min_samples_leaf,调节的范围如下所示:
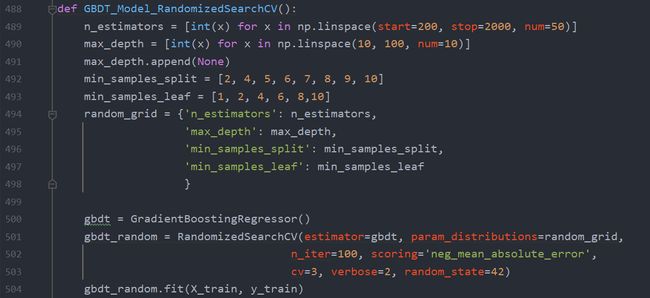
使用 GridSearchCV 对 GBDT 调参,调节的参数有 n_estimators,learning_rate,max_depth,min_samples_split,min_samples_leaf,调节的范围如下:
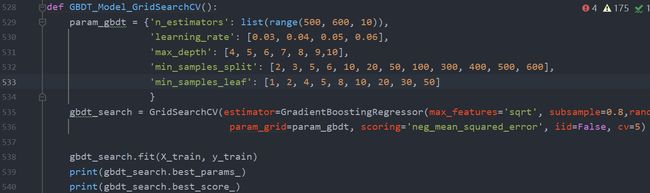
调参结束以后,可以通过输出 best_estimator_属性来查看最佳参数。
折交叉验证和留一法
由于本题采用了很多个模型,故对于模型的评判至关重要。采用 k 折交叉验证(k 取 5)和留一法进行模型的评判,通过记录模型预测结果的均方根误差,取所有预测结果均方根误差的平均值。
因为这题数据量比较小,运行时间并不会很长,所以可直接使用留一法进行验证。因为验证次数很多,所以留一法相对比较准确,但是计算量很大。
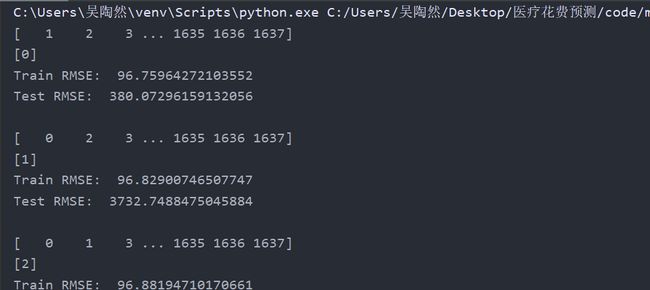
遇到的问题和解决方法
遇到的问题一:手写实现随机森林时若建立决策树较多,随机森林运行速率较慢
解决方法:通过学习 sklearn 库的 RandomForestRegressor 源代码可知,可以将循环建立决策树更改为使用 parallel 进行并行建立决策树,在一定情况下能大幅提高效率。
遇到的问题二:手写实现线性回归,运行结果的方差过大,结果不准确
解决方法:线性回归的学习率不能设置得过大,当学习率设置得过大时,会出现震荡现象,使得误差越来越大。
遇到的问题三:手写实现线性回归,结果误差较大。
解决方法:对数据进行归一化。在使用线性回归时,数据需要进行归一化处理,才能保证准确率。因为数据做了归一化后,整个数据集上的梯度分布得到了改良,此时也可以适当调大学习率。
遇到的问题四:模型融合结果比不融合还低
解决方法:模型不满足“好而不同的特点”。不能直接使用直接平均法,根据模型的性能排名,为模型赋予一定的权重,按加权平均的方式,并对模型部分异常值进行剔除,不参与模型融合。
遇到的问题五:调参时出现过拟合

解决方法:模型预测结果里,训练集的误差很小很小,而测试集的误差很大很大,甚至在训练集误差的十倍以上时,大概率为过拟合。此时需要注意重新调节参数,特别是学习率等参数。决策树容易出现过拟合的现象,而随机森林和 GBDT 等不容易过拟合。
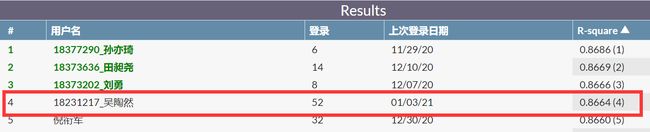
评测分数和排名
截止 2021 年 1 月 3 日晚 20:00,最终评分为 0.8664,排名为第 4 名。
![]()
IMDB 评论情感判断
方法介绍
使用 stopwords、WordNetLemmatizer、Tokenizer 进行数据预处理。使用 Keras 中的 Sequential 模型进行训练,共包含 Embedding 层、LSTM 层、池化层、激活函数为 relu 的隐藏层和激活函数为 sigmoid 层。
数据处理、方法实现细节和模型结构
通过 pd.read_csv 读入数据后,对’sentiment’特征调用 value_counts()方法观察得知数据 positive 和 negative 大概分布均衡。
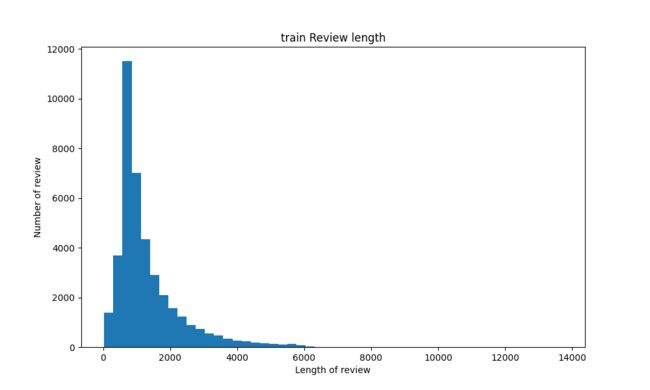
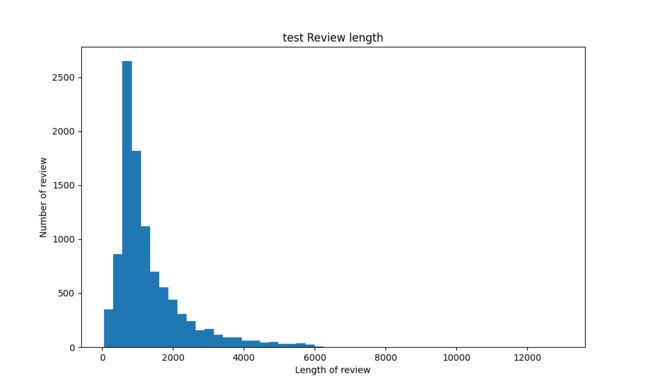
同时训练集和测试集的大部分评论的长度均在 6000 以下。
使用 LabelEncoder 函数将数据集中的 positive 转换为 1,negative 转换为 0,便于模型的训练。通过观察数据集可以得知,评论中存在
等 HTML 字符,需要将其剔除。可使用正则表达式匹配,直接将其删去。并将所有评论字符转换为小写。
数据还需进行 stop words(停用词)的预处理,这些词应用十分广泛、对情感分析并无太大意义,可能自身并无明确的意义,例如语气助词、副词、介词、连接词等。为节省存储空间和提高搜索效率,在进行建模时需要忽略 stopwords。故引入 nltk.corpus 库中的 stopword,删除评论中的所有停用字符。
由于单词存在不同形式,例如 have 单词可能有 having 或 has 等形式,故使用 nltk.stem 中的 WordNetLemmatizer 进行词干提取。
随后使用 Keras 的分词器 Tokenizer,将文本转换为序列。由于通过分析数据得知,训练集和测试集的评论大部分在 6000 以下,故将 Tokenizer 的 num_words 属性设置为 6000。使用 pad_sequences 对序列进行预处理,maxlen 参数设置为 None。
建立 Sequential 模型,使用 Embedding 加入 Embedding 层,加入 LSTM 网络,使用 GlobalMaxPool1D()加入池化层,加入一层激活函数为 relu 的隐藏层,维数为 20。并引入 Dropout()防止过拟合,参数设置为 0.05,最终输出层激活函数为 sigmoid,维数为 1。
使用 compile 方法和 fit 方法对模型进行训练,其中 loss 参数设置为’binary_crossentropy’,optimizer 参数设置为’adam’, metrics 参数设置为[‘accuracy’],batch_size 设置为 200,共迭代 5 次。
最终,该模型包含 Embedding 层、LSTM 层、池化层、激活函数为 relu 的隐藏层和 sigmoid 层。参数设置如下:

由于模型训练较为耗时,故使用 Kera 的 save 方法将训练得到的模型进行保存。对测试集进行相同的测试处理后,使用 predict 方法进行训练以后即可得到结果。
调参过程
由于该问题中需要调节的参数很少,且进行极少的调整后就能得到不错的结果,故直接手动尝试调参。
Tokenizer 方法的 num_words,由于通过数据可视化可以直观感受到数据集中大部分评论的长度均在 6000 以下,故 num_words 直接设置为 6000.
pad_sequences 里,为 maxlen 设置一定限制能大幅提高训练速度,根据观察处理后的数据可知,将 maxlen 设置为 150 较为合适。但由于为了追求极致的正确率,此处将 maxlen 设置为 None。
embed_size 最终设置为 128。初始时忽视了 batch_size 参数的设置,以至于在训练过程中所有的训练数据直接输入到网络,导致泛化能力差,计算量庞大。最终 batch_size 设置为 200,epochs 设置为 5。
遇到的问题和解决方法
遇到的问题一:模型训练效率过低,训练一次需要耗费几天的时间
解决方法:引入 stopwords 停用词集,删除停用词,减少不相关单词的空间占用和时间占用;加入 batch_size 参数限制,初始时设置为 100,调参后更改为 200;加入 maxlen 参数限制,将过长的序列截断。优化后效率大幅提升。
遇到的问题二:nltk 里的 stopwords 始终无法正确调用和配置。
解决方法:不通过 pip install 或者 pycharm 的环境按照 nltk,而是在 GitHub 上找到完整的 nltk 数据包,根据调用时的错误提示安装在合适的位置即可。
评测分数和排名
截止 1 月 3 日下午 17:00,最终评分为 0.9296,排名为第 8 名。
![]()

解决方法:不通过 pip install 或者 pycharm 的环境按照 nltk,而是在 GitHub 上找到完整的 nltk 数据包,根据调用时的错误提示安装在合适的位置即可。
资源下载地址:https://download.csdn.net/download/sheziqiong/85837039
资源下载地址:https://download.csdn.net/download/sheziqiong/85837039