pytorch 常见API实践
文章目录
- 1. torch.bernouli
- 2. Tensor.masked_fill_(mask, value)
- 3. torch.NLLLOSS
- 4. nn.Conv2d
- 5. torch.randint
- 6. tensor.to
- 7. tensor.ge()&torch.masked_select
- 8. torch.triu
- 9. torch.tile
- 10. torch.flip
- 11. torch.chunk
- 12. torch.roll
- 13. torch.sum
- 14. torch.argmax()
- 15. torch.nn.functional.softmax
- 16. torch.nn.LSTM & torch.nn.LSTMCELL
- 17. torch.any&torch.all
- 18.torch.stack & torch.cat
1. torch.bernouli
torch.bernoulli(input, *, generator=None, out=None) → Tensor
input : 表示的是一个概率值组成的矩阵
output:表示的是一个跟input同等大小的矩阵,输出矩阵是来自伯努利分布
从伯努利分布中绘制二进制随机数(0或1)。
- 举例:
假设我们input矩阵如下:
input_rand=tensor([[0.5564, 0.0900, 0.8406, 0.7404],
[0.9572, 0.7736, 0.4841, 0.6658],
[0.7223, 0.0511, 0.8271, 0.8581]])
[0.5564,0.0900,0.8406,0.7404]表示:
0.5565 概 率 抽 到 1 0.5565概率抽到\qquad1 0.5565概率抽到1
0.0900 概 率 抽 到 1 0.0900概率抽到\qquad1 0.0900概率抽到1
0.8406 概 率 抽 到 1 0.8406概率抽到\qquad1 0.8406概率抽到1
0.7404 概 率 抽 到 1 0.7404概率抽到\qquad1 0.7404概率抽到1
- 测试代码如下:
import torch
from torch import nn
# draw the sample from [0,1),shape is (3,4);
# input_rand is probability to get the value 1
input_rand = torch.rand((3,4))
# draw the sample from bernoulli distribution;the probability is input_rand
output_rand = torch.bernoulli(input_rand)
# get a tensor filled all the value ones
input_ones = torch.ones((3,4))
# the probability is 1 ; so the output is all 1
output_ones = torch.bernoulli(input_ones)
# get a tensor filled all the value zeros
input_zeros = torch.zeros((3,4))
# the probability is 0 ; so the output is all 0
output_zeros = torch.bernoulli(input_zeros)
print(f"input_rand={input_rand}")
print(f"output_rand={output_rand}")
print("*"*50)
print(f"input_zeros={input_zeros}")
print(f"output_zeros={output_zeros}")
print("*"*50)
print(f"input_ones={input_ones}")
print(f"output_ones={output_ones}")
input_rand=tensor([[0.3222, 0.4630, 0.8227, 0.6225],
[0.3587, 0.6961, 0.6875, 0.9904],
[0.4817, 0.5500, 0.9436, 0.0660]])
output_rand=tensor([[0., 0., 1., 1.],
[0., 1., 0., 1.],
[1., 1., 1., 0.]])
**************************************************
input_zeros=tensor([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
output_zeros=tensor([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
**************************************************
input_ones=tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
output_ones=tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
2. Tensor.masked_fill_(mask, value)
使用mask为True的值填充自张量的元素。掩模的形状必须与潜在张量的形状一致。
将一个张量中的元素根据mask值为真去替换,替换成value值,False值保持不变
import torch
# input tensor x
x = torch.arange(12.).reshape((3,4))
# get a tensor filled with 0,1 with the same shape to input
prob = torch.bernoulli(torch.rand(3,4))
# if the value in the prob is equal to 1 ,replace 888 to it ;
# the others keep the same
y = x.masked_fill(prob==1,value=888)
print(f"x={x}")
print(f"prob={prob}")
print(f"y={y}")
x=tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
prob=tensor([[1., 1., 1., 1.],
[1., 0., 1., 0.],
[0., 1., 1., 1.]])
y=tensor([[888., 888., 888., 888.],
[888., 5., 888., 7.],
[ 8., 888., 888., 888.]])
3. torch.NLLLOSS
4. nn.Conv2d
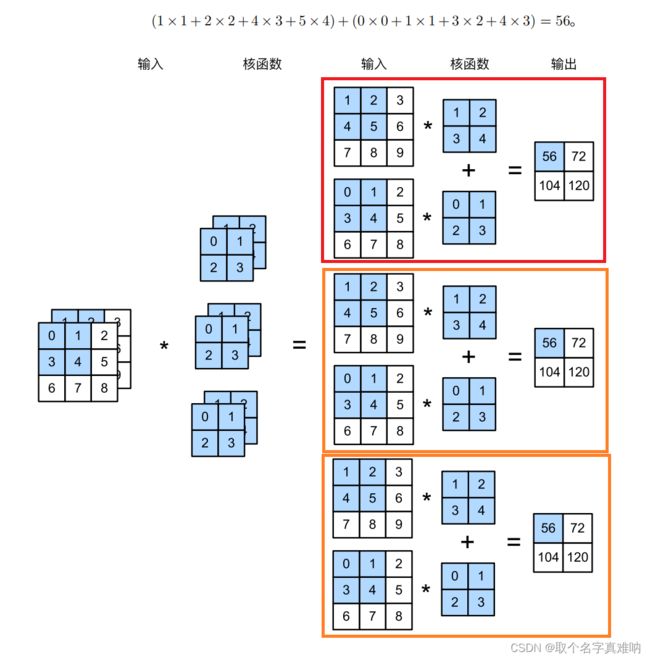
import torch
from torch import nn
# 目标:将一个输入为input = (1,2,3,3)
# 经过卷积my_conv = nn.Conv2d(2, 3, 2);
# 输出output = (1,3,2,2)
# 步骤如下:
# 将卷积变成形状为(in_channel=2,weight=2,height=2),跟输入的(in_channel=2,weight=3,height=3)匹配
# 为了满足输出的通道数out_channel=3,那么我们只需要将卷积核复制3次 (2,2,2) -> (3,2,2,2)
# 也是就是得到my_conv2d.weights.shape=(3,2,2,2);
# 同理 my_conv2d.bias.shape = (3)
input = torch.Tensor([[[[1, 2, 3], [4, 5, 6], [7, 8, 9]], [[0, 1, 2], [3, 4, 5], [6, 7, 8]]]])
print(f"input.shape={input.shape}")
# input.shape=torch.Size([batch_size=1, in_channel=2, weight=3, height=3])
print(f"input={input}")
# my_conv = nn.Conv2d(in_channel=2, ou_channel=3, kernel_size=2x2)
my_conv = nn.Conv2d(2, 3, 2)
weight = torch.Tensor([[[[1,2],[3,4]],[[0,1],[2,3]]]])
weight = torch.repeat_interleave(weight,3,dim=0)
my_conv.weight = nn.Parameter(weight)
bias = torch.Tensor([0])
bias = torch.repeat_interleave(bias,3,dim=0)
print(f"my_conv.weight.shape={my_conv.weight.shape}")
print(f"my_conv.bias.shape={my_conv.bias.shape}")
print(f"my_conv.weight={my_conv.weight}")
print(f"my_conv.bias={my_conv.bias}")
my_conv.bias = nn.Parameter(bias)
output = my_conv(input)
print(f"output.shape={output.shape}")
print(f"output={output}")
input.shape=torch.Size([1, 2, 3, 3])
input=tensor([[[[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]],
[[0., 1., 2.],
[3., 4., 5.],
[6., 7., 8.]]]])
my_conv.weight.shape=torch.Size([3, 2, 2, 2])
my_conv.bias.shape=torch.Size([3])
my_conv.weight=Parameter containing:
tensor([[[[1., 2.],
[3., 4.]],
[[0., 1.],
[2., 3.]]],
[[[1., 2.],
[3., 4.]],
[[0., 1.],
[2., 3.]]],
[[[1., 2.],
[3., 4.]],
[[0., 1.],
[2., 3.]]]], requires_grad=True)
my_conv.bias=Parameter containing:
tensor([ 0.0517, 0.2091, -0.1445], requires_grad=True)
output.shape=torch.Size([1, 3, 2, 2])
output=tensor([[[[ 56., 72.],
[104., 120.]],
[[ 56., 72.],
[104., 120.]],
[[ 56., 72.],
[104., 120.]]]], grad_fn=<ThnnConv2DBackward>)
5. torch.randint
返回一个张量,张量来自于[low,high)中,size为最后行程张量的大小
torch.randint(low=0, high, size, \*, generator=None, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor
import torch
# 创建一个3行4列的矩阵,矩阵的值取值[2,5)的整数值
x = torch.randint(low=2, high=5, size=(3, 4))
print(f"x={x}")
# x=tensor([[4, 4, 3, 2],
# [4, 4, 2, 4],
# [4, 3, 2, 2]])
6. tensor.to
主要作用是对张量的精度进行转换
# torch.Tensor 默认是float32的精度
m = torch.Tensor([2,4])
# 将张量的精度转换成torch.int32
n = m.to(torch.int32)
print(f"m={m.dtype}")
# m=torch.float32
print(f"n={n.dtype}")
# n=torch.int32
7. tensor.ge()&torch.masked_select
- tensor.ge();
input.ge(x) 将input里面的所有元素跟x进行比较,input_value>=x返回True,否则False - torch.masked_select
torch.masked_select(input,mask):根据mask中True值,将对应于input位的数据抽取出来,返回到一维张量中 - 代码
import torch
# 从一个均值为0,方差为1的正太分布中抽取数据得到一个3行4列矩阵
input = torch.randn((3, 4))
print(f"x_input={input}")
# 将 矩阵X中的值跟0.5比较,大于等于0.5返回True,小于0.5返回False
mask = input.ge(0.5)
print(f"mask={mask}")
# 根据mask矩阵中的True,将对应True的input里面的值抽取出来,返回一维张量
output = torch.masked_select(input,mask)
print(f"output={output}")
- 结果
x_input=tensor([[-2.0118, -0.4704, 2.7249, 1.6469],
[-2.1512, 0.6178, 2.4700, 0.1588],
[ 0.2585, -0.1287, 0.6908, -0.5606]])
mask=tensor([[False, False, True, True],
[False, True, True, False],
[False, False, True, False]])
output=tensor([2.7249, 1.6469, 0.6178, 2.4700, 0.6908])
8. torch.triu
torch.triu(input,diagonal)
input表示一个需要进行上三角矩阵处理的输入矩阵input
diagonal默认为0,默认从主对角线上所有的上三角,diagonal=k表示对角线向上走多少,k为正数向上,k为负数向下
x = torch.randn((4,4))
x_tri = torch.triu(x)
x_tri_1 = torch.triu(x,diagonal=1)
x_tri_2 = torch.triu(x,diagonal=2)
x_tri_f1 = torch.triu(x,diagonal=-1)
x_tri_f2 = torch.triu(x,diagonal=-2)
print(f"x={x}")
print(f"x_tri={x_tri}")
print(f"x_tri_1={x_tri_1}")
print(f"x_tri_2={x_tri_2}")
print(f"x_tri_f1={x_tri_f1}")
print(f"x_tri_f2={x_tri_f2}")
x=tensor([[-0.8635, -0.0673, 0.9718, 0.8746],
[-1.7199, -1.0076, 0.5058, -0.1469],
[-0.6094, 1.3910, 0.1160, 0.0928],
[ 1.9978, -1.6106, -0.0179, -0.2358]])
x_tri=tensor([[-0.8635, -0.0673, 0.9718, 0.8746],
[ 0.0000, -1.0076, 0.5058, -0.1469],
[ 0.0000, 0.0000, 0.1160, 0.0928],
[ 0.0000, 0.0000, 0.0000, -0.2358]])
x_tri_1=tensor([[ 0.0000, -0.0673, 0.9718, 0.8746],
[ 0.0000, 0.0000, 0.5058, -0.1469],
[ 0.0000, 0.0000, 0.0000, 0.0928],
[ 0.0000, 0.0000, 0.0000, 0.0000]])
x_tri_2=tensor([[ 0.0000, 0.0000, 0.9718, 0.8746],
[ 0.0000, 0.0000, 0.0000, -0.1469],
[ 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000]])
x_tri_f1=tensor([[-0.8635, -0.0673, 0.9718, 0.8746],
[-1.7199, -1.0076, 0.5058, -0.1469],
[ 0.0000, 1.3910, 0.1160, 0.0928],
[ 0.0000, 0.0000, -0.0179, -0.2358]])
x_tri_f2=tensor([[-0.8635, -0.0673, 0.9718, 0.8746],
[-1.7199, -1.0076, 0.5058, -0.1469],
[-0.6094, 1.3910, 0.1160, 0.0928],
[ 0.0000, -1.6106, -0.0179, -0.2358]])
9. torch.tile
通过重复输入的元素构造一个张量。dims参数指定每个维度的重复次数
import torch
x = torch.Tensor([1,2,3])
# 将输入 x 按行复制到3遍,列复制到4遍
x_dim_3_4 = torch.tile(x,(3,4))
y = torch.tensor([[4,5,6],[7,8,9]])
# 将输入 y 按行复制到2遍,列复制到3遍
y_dim_2_3 = torch.tile(y,(2,3))
print(f"x={x}")
# x=tensor([1., 2., 3.])
print(f"x.shape={x.shape}")
# x.shape=torch.Size([3])
print(f"x_dim_3_4={x_dim_3_4}")
# x_dim_3_4=tensor([[1., 2., 3., 1., 2., 3., 1., 2., 3., 1., 2., 3.],
# [1., 2., 3., 1., 2., 3., 1., 2., 3., 1., 2., 3.],
# [1., 2., 3., 1., 2., 3., 1., 2., 3., 1., 2., 3.]])
print(f"x_dim_3_4.shape={x_dim_3_4.shape}")
# x_dim_3_4.shape=torch.Size([3, 12])
print(f"y={y}")
# y=tensor([[4, 5, 6],
# [7, 8, 9]])
print(f"y.shape={y.shape}")
# y.shape=torch.Size([2, 3])
print(f"y_dim_2_3={y_dim_2_3}")
# y_dim_2_3=tensor([[4, 5, 6, 4, 5, 6, 4, 5, 6],
# [7, 8, 9, 7, 8, 9, 7, 8, 9],
# [4, 5, 6, 4, 5, 6, 4, 5, 6],
# [7, 8, 9, 7, 8, 9, 7, 8, 9]])
print(f"y_dim_2_3.shape={y_dim_2_3.shape}")
# y_dim_2_3.shape=torch.Size([4, 9])
10. torch.flip
作用:将输入张量指定的维度进行倒序处理。
import torch
# 定义输入 x
x = torch.arange(24).reshape((2, 3, 4))
# 将第0维进行倒序
x_0 = torch.flip(x, [0])
# 将第1维进行倒序
x_1 = torch.flip(x, [1])
# 将第2维进行倒序
x_2 = torch.flip(x, [2])
# 将第0,1维同时进行倒序
x_0_1 = torch.flip(x, [0, 1])
print(f"x={x}")
print(f"x_0={x_0}")
print(f"x_1={x_1}")
print(f"x_2={x_2}")
print(f"x_0_1={x_0_1}")
- 结果
x=tensor([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
x_0=tensor([[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]],
[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]]])
x_1=tensor([[[ 8, 9, 10, 11],
[ 4, 5, 6, 7],
[ 0, 1, 2, 3]],
[[20, 21, 22, 23],
[16, 17, 18, 19],
[12, 13, 14, 15]]])
x_2=tensor([[[ 3, 2, 1, 0],
[ 7, 6, 5, 4],
[11, 10, 9, 8]],
[[15, 14, 13, 12],
[19, 18, 17, 16],
[23, 22, 21, 20]]])
x_0_1=tensor([[[20, 21, 22, 23],
[16, 17, 18, 19],
[12, 13, 14, 15]],
[[ 8, 9, 10, 11],
[ 4, 5, 6, 7],
[ 0, 1, 2, 3]]])
11. torch.chunk
主要作用是将张量分割成指定份数;dim可以指定维度;此函数方便切割张量
# -*- coding: utf-8 -*-
# @Project: zc
# @Author: zc
# @File name: chunk_new_test
# @Create time: 2022/5/3 14:48
import torch
x11 = torch.arange(11)
x12 = torch.arange(12)
x13 = torch.arange(13)
# 将张量切割成6份
# 11/6=1.83 --> n = 2 每2个元素组成一组
# 12/6=2 --> n = 2 每2个元素组成一组
# 13/6=2.16 --> n = 3 每3个元素组成一组
y11 = torch.chunk(x11, 6)
y12 = torch.chunk(x12, 6)
y13 = torch.chunk(x13, 6)
print(f"x11={x11}")
# x11=tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
print(f"x12={x12}")
# x12=tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
print(f"x13={x13}")
# x13=tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
print(f"y11={y11}")
# y11=(tensor([0, 1]), tensor([2, 3]), tensor([4, 5]), tensor([6, 7]), tensor([8, 9]), tensor([10]))
print(f"y12={y12}")
# y12=(tensor([0, 1]), tensor([2, 3]), tensor([4, 5]), tensor([6, 7]), tensor([8, 9]), tensor([10, 11]))
print(f"y13={y13}")
# y13=(tensor([0, 1, 2]), tensor([3, 4, 5]), tensor([6, 7, 8]), tensor([ 9, 10, 11]), tensor([12]))
x = torch.arange(24).reshape((2,3,4))
print(f"x={x}")
# 将 x 按照第0维分成2份
x0 = torch.chunk(x,2,dim=0)
# 将 x 按照第1维分成2份
x1 = torch.chunk(x,2,dim=1)
# 将 x 按照第2维分成2份
x2 = torch.chunk(x,2,dim=2)
print(f"x0={x0}")
# x0=(tensor([[[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]]]), tensor([[[12, 13, 14, 15],
# [16, 17, 18, 19],
# [20, 21, 22, 23]]]))
print(f"x1={x1}")
# x1=(tensor([[[ 0, 1, 2, 3],
# [ 4, 5, 6, 7]],
#
# [[12, 13, 14, 15],
# [16, 17, 18, 19]]]), tensor([[[ 8, 9, 10, 11]],
#
# [[20, 21, 22, 23]]]))
print(f"x2={x2}")
# x2=(tensor([[[ 0, 1],
# [ 4, 5],
# [ 8, 9]],
#
# [[12, 13],
# [16, 17],
# [20, 21]]]), tensor([[[ 2, 3],
# [ 6, 7],
# [10, 11]],
#
# [[14, 15],
# [18, 19],
# [22, 23]]]))
12. torch.roll
沿着给定的维滚动张量。移动到最后一个位置以外的元素会在第一个位置重新引入。如果没有指定尺寸,则在滚动前将张量压平,然后恢复到原始形状;相当于按位移动
torch.roll(input, shifts, dims=None) → Tensor
input:输入的张量shifts:移动的步数dims:移动的维度
# 创建一个3行4列矩阵
x = torch.arange(12).reshape(3,4)
print(f"x={x}")
# x=tensor([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])
# 整体行向下移动一行,最后一行跑到第一行
x_1_d = torch.roll(x, 1, dims=0)
# x_1_d=tensor([[ 8, 9, 10, 11],
# [ 0, 1, 2, 3],
# [ 4, 5, 6, 7]])
# 整体行向上移动一行,第一行跑到最后一行
x_1_u = torch.roll(x, -1, dims=0)
# x_1_u=tensor([[ 4, 5, 6, 7],
# [ 8, 9, 10, 11],
# [ 0, 1, 2, 3]])
# 整体列向左移动一列,第一列跑到最后一列
x_1_l = torch.roll(x, -1, dims=1)
# x_1_l=tensor([[ 1, 2, 3, 0],
# [ 5, 6, 7, 4],
# [ 9, 10, 11, 8]])
# 整体列向有移动一列,最后一列跑到第一列
x_1_r = torch.roll(x, 1, dims=1)
# x_1_r=tensor([[ 3, 0, 1, 2],
# [ 7, 4, 5, 6],
# [11, 8, 9, 10]])
print(f"x_1_d={x_1_d}")
print(f"x_1_u={x_1_u}")
print(f"x_1_l={x_1_l}")
print(f"x_1_r={x_1_r}")
13. torch.sum
作用:对输入的张量进行求和,dim可以指定维度进行求和
torch.sum(input, *, dtype=None) → Tensor
import torch
x = torch.arange(24).reshape(2,3,4)
# 按照第0维度进行求和;每一个batch批次求和
# x[0]=[[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]]
# x[1]=[[12, 13, 14, 15],
# [16, 17, 18, 19],
# [20, 21, 22, 23]]
# 按照第0维度进行求和,即行与行之间求和
x_sum_0 = torch.sum(x,dim=0)
# x_sum_0=tensor([[12, 14, 16, 18],
# [20, 22, 24, 26],
# [28, 30, 32, 34]])
# 按照第1维度进行求和,[2,0,4]+[2,1,4]+[2,2,4]
x_sum_1 = torch.sum(x,dim=1)
# x=tensor([[[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]],
#
# [[12, 13, 14, 15],
# [16, 17, 18, 19],
# [20, 21, 22, 23]]])
# x_sum_1=tensor([[12=0+4+8, 15=1+5+9, 18=2+6+10, 21=3+7+11],
# [48=12+16+20, 51=13+17+21, 54=14+18+22, 57=15+19+23]])
# 按照第2维进行求和,即列与列之间求和
x_sum_2 = torch.sum(x,dim=2)
# x=tensor([[[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]],
#
# [[12, 13, 14, 15],
# [16, 17, 18, 19],
# [20, 21, 22, 23]]])
# x_sum_2=tensor([[ 6=0+1+2+3, 22=4+5+6+7, 38=8+9+10+11],
# [54=12+13+14+15, 70=16+17+18+19, 86=20+21+22+23]])
print(f"x={x}")
# x=tensor([[[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]],
#
# [[12, 13, 14, 15],
# [16, 17, 18, 19],
# [20, 21, 22, 23]]])
print(f"x.shape={x.shape}")
# x.shape=torch.Size([2, 3, 4])
print(f"x_sum_0={x_sum_0}")
# x_sum_0=tensor([[12, 14, 16, 18],
# [20, 22, 24, 26],
# [28, 30, 32, 34]])
print(f"x_sum_0.shape={x_sum_0.shape}")
# x_sum_0.shape=torch.Size([3, 4])
print(f"x_sum_1={x_sum_1}")
# x_sum_1=tensor([[12, 15, 18, 21],
# [48, 51, 54, 57]])
print(f"x_sum_1.shape={x_sum_1.shape}")
# x_sum_1.shape=torch.Size([2, 4])
print(f"x_sum_2={x_sum_2}")
# x_sum_2=tensor([[ 6, 22, 38],
# [54, 70, 86]])
print(f"x_sum_2.shape={x_sum_2.shape}")
# x_sum_2.shape=torch.Size([2, 3])
14. torch.argmax()
返回输入张量中所有元素最大值的索引;主要做分类用;
import torch
torch.manual_seed(100)
# 随机生成一个矩阵[2,3,4],里面的值不能超过10
x = torch.randint(10,size=(2,3,4))
# x=tensor([[[0, 2, 5, 9],
# [5, 1, 2, 8],
# [8, 0, 4, 3]],
#
# [[8, 8, 4, 4],
# [1, 0, 4, 3],
# [8, 7, 4, 6]]])
# 按照第0维进行比较,批次与批次之间对比;返回值比较大的批次序号
x_0 = torch.argmax(x,dim=0)
# 举例,0<8返回1,2<8返回1,5>4返回0,9>4返回0;
# 所以x_0的第一行返回为[1,1,0,0]
# x_0=tensor([[1, 1, 0, 0],
# [0, 0, 1, 0],
# [0, 1, 0, 1]])
# x[0]= [[0, 2, 5, 9],
# [5, 1, 2, 8],
# [8, 0, 4, 3]]
# X[1]= [[8, 8, 4, 4],
# [1, 0, 4, 3],
# [8, 7, 4, 6]]
# 按照第1维进行比较,行与行之间对比,返回每个批次中值最大的行号
x_1 = torch.argmax(x,dim=1)
# 举例我们在0,5,8中, 最大的是8,返回序列2;
# 在2,1,0中; 最大的是2,返回序列0;
# 在5,2,4中; 最大的是5,返回序列0;
# 在9,8,3中; 最大的是9,返回序列0;
# 所以x_1的第一行为[2,0,0,0]
# x=tensor([[[0, 2, 5, 9],
# [5, 1, 2, 8],
# [8, 0, 4, 3]],
#
# [[8, 8, 4, 4],
# [1, 0, 4, 3],
# [8, 7, 4, 6]]])
# x_1=tensor([[2, 0, 0, 0],
# [0, 0, 0, 2]])
# 按照第2维进行比较,列与列之间对比,返回每行中每列值最大的列号
x_2 = torch.argmax(x,dim=2)
# 举例:
# 在[0,2,5,9]中,最大的是9,返回序号3
# 在[5,1,2,8]中,最大的是8,返回序号3
# 在[8,0,4,3]中,最大的是8,返回序号0
# 所以x_2中结果为[3,3,0]
# x=tensor([[[0, 2, 5, 9],
# [5, 1, 2, 8],
# [8, 0, 4, 3]],
#
# [[8, 8, 4, 4],
# [1, 0, 4, 3],
# [8, 7, 4, 6]]])
# x_2=tensor([[3, 3, 0],
# [0, 2, 0]])
print(f"x={x}")
# x=tensor([[[0, 2, 5, 9],
# [5, 1, 2, 8],
# [8, 0, 4, 3]],
#
# [[8, 8, 4, 4],
# [1, 0, 4, 3],
# [8, 7, 4, 6]]])
print(f"x.shape={x.shape}")
# x.shape=torch.Size([2, 3, 4])
print(f"x_0={x_0}")
# x_0=tensor([[1, 1, 0, 0],
# [0, 0, 1, 0],
# [0, 1, 0, 1]])
print(f"x_0.shape={x_0.shape}")
# x_0.shape=torch.Size([3, 4])
print(f"x_1={x_1}")
# x_1=tensor([[2, 0, 0, 0],
# [0, 0, 0, 2]])
print(f"x_1.shape={x_1.shape}")
# x_1.shape=torch.Size([2, 4])
print(f"x_2={x_2}")
# x_2=tensor([[3, 3, 0],
# [0, 2, 0]])
print(f"x_2.shape={x_2.shape}")
# x_2.shape=torch.Size([2, 3])
15. torch.nn.functional.softmax
torch.nn.functional.softmax(input, dim=None, _stacklevel=3, dtype=None)
input:输入的张量dim:指定维度
s o f t m a x ( x i ) = exp x i ∑ j exp x j softmax(x_i)=\frac{\exp{x_i}}{\sum_j\exp{x_j}} softmax(xi)=∑jexpxjexpxi
import torch
from torch.nn import functional as F
# 随机生成一个张量x
x = torch.randn(3,4)
# 沿着dim=0求概率分布
x_0 = F.softmax(x,dim=0)
# 沿着dim=1求概率分布
x_1 = F.softmax(x,dim=1)
# 沿着dim=0求和,确认是否和为1
x_0_sum = torch.sum(x_0,dim=0)
# 沿着dim=1求和,确认是否和为1
x_1_sum = torch.sum(x_1,dim=1)
print(f"x_0_sum={x_0_sum}")
# x_0_sum=tensor([1., 1., 1., 1.])
print(f"x_1_sum={x_1_sum}")
# x_1_sum=tensor([1., 1., 1.])
# 求和
y_0_sum = torch.sum(torch.exp(x),dim=0,keepdim=True)
y_1_sum = torch.sum(torch.exp(x),dim=1,keepdim=True)
# 按照公式手动计算得到y_0,y_1
y_0 = torch.exp(x)/torch.sum(torch.exp(x),dim=0,keepdim=True)
y_1 = torch.exp(x)/torch.sum(torch.exp(x),dim=1,keepdim=True)
# 比较x_0==y_0,如果flag_0=True表示公式计算和函数计算一致
flag_0 = torch.isclose(x_0,y_0)
# flag_0=tensor([[True, True, True, True],
# [True, True, True, True],
# [True, True, True, True]])
# 比较x_1==y_1,如果flag_1=True表示公式计算和函数计算一致
flag_1 = torch.isclose(x_1,y_1)
# flag_1=tensor([[True, True, True, True],
# [True, True, True, True],
# [True, True, True, True]])
print(f"flag_0={flag_0}")
print(f"flag_1={flag_1}")
print(f"x={x}")
print(f"x.shape={x.shape}")
print(f"x_0={x_0}")
print(f"x_0.shape={x_0.shape}")
print(f"y_0={y_0}")
print(f"y_0.shape={y_0.shape}")
print(f"y_1={y_1}")
print(f"y_1.shape={y_1.shape}")
print(f"x_1={x_1}")
print(f"x_1.shape={x_1.shape}")
print(f"y_0_sum={y_0_sum}")
print(f"y_0_sum.shape={y_0_sum.shape}")
print(f"y_1_sum={y_1_sum}")
print(f"y_1_sum.shape={y_1_sum.shape}")
16. torch.nn.LSTM & torch.nn.LSTMCELL
import torch
from torch import nn
from torch.nn import functional as F
my_lstm_cell = nn.LSTMCell(input_size=10,hidden_size=20)
input = torch.randn(3,10)
h_0 = torch.randn(3,20)
c_0 = torch.randn(3,20)
h_n1, c_n1 = my_lstm_cell(input, (h_0, c_0))
print(f"h_n1={h_n1}")
print(f"h_n1.shape={h_n1.shape}")
print(f"c_n1={c_n1}")
print(f"c_n1.shape={c_n1.shape}")
my_lstm = nn.LSTM(input_size=4,hidden_size=6)
input = torch.randn(2,3,4)
h_0 = torch.randn(1,3,6)
c_0 = torch.randn(1,3,6)
output,(h_n2,c_n2) = my_lstm(input,(h_0,c_0))
print(f"output={output}")
print(f"output.shape={output.shape}")
print(f"h_n2.shape={h_n2.shape}")
print(f"h_n2.shape={h_n2.shape}")
17. torch.any&torch.all
torch.any:表示的是输入input里面只要含一个True,就返回True;全为False才返回Falsetorch.all:表示的是输入input里面只要含一个False,就返回False;全为True才返回True
import torch
a = torch.Tensor([False,False,False])
b = torch.Tensor([True,False,False])
c = torch.Tensor([True,True,True])
# torch.any 表示的是张量input中只要有一个True就返回True,只有所有为False则返回False
# 全为False,故a_any = False
a_any = torch.any(a)
# 有一个True,故b_any = True
b_any = torch.any(b)
# 全为True,故c_any = True
c_any = torch.any(c)
# torch.all 表示的是张量input中全为True,则返回True,否则返回False
# 因为 a 全为False,故 a_all = False
a_all = torch.all(a)
# 因为 b 只有一个True,故 b_all = False
b_all = torch.all(b)
# 因为 c全为True,故c_all = True
c_all = torch.all(c)
# a=tensor([0., 0., 0.])
# b=tensor([1., 0., 0.])
# c=tensor([1., 1., 1.])
# a_any=False
# b_any=True
# c_any=True
# a_all=False
# b_all=False
# c_all=True
print(f"a={a}")
print(f"b={b}")
print(f"c={c}")
print(f"a_any={a_any}")
print(f"b_any={b_any}")
print(f"c_any={c_any}")
print(f"a_all={a_all}")
print(f"b_all={b_all}")
print(f"c_all={c_all}")
18.torch.stack & torch.cat
torch.stack:沿着一个新的维度连接张量序列。torch.cat:沿着指定维度连接张量区别:stack:产生新的维度,cat不产生新的维度
import torch
x = torch.ones(3,4)
y = torch.zeros(3,4)
xy_cat = torch.cat((x,y))
xy_stack = torch.stack((x,y))
print(f"x={x}")
print(f"y={y}")
print(f"xy_cat={xy_cat}")
print(f"xy_cat.shape={xy_cat.shape}")
print(f"xy_stack={xy_stack}")
print(f"xy_stack.shape={xy_stack.shape}")
x=tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
y=tensor([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
xy_cat=tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
# torch.cat不产生新的维度,是在原来的维度上进行叠加
xy_cat.shape=torch.Size([6, 4])
xy_stack=tensor([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]])
# torch.stack在一个新的维度上进行叠加
xy_stack.shape=torch.Size([2, 3, 4])