机器学习(1)——BP神经网络
神经网络
神经网络是由具有适应性的简单单元组成的广泛并行互联的网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交互反应。
神经网络中最基本的成分是神经元模型。下图为“M-P神经元模型”
在神经元模型中,神经元接受来自其他神经元传递过来的信号,并通过带权重的连接进行传递,神经元接收到的总输入值与神经元的阈值比较后经过“激活函数”处理输出。
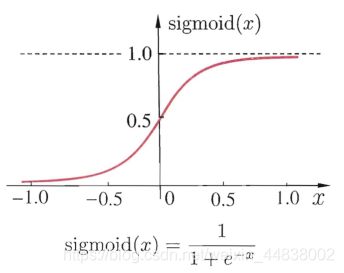
常用的激活函数为Sigmoid函数,它可把在较大范围内变化的输入值转换为在(0,1)区间范围内的输入值。Sigmoid函数如下图所示
把多个神经元模型按一定的层次结构连接起来,就得到了神经网络。
感知机是由两层神经元组成的,只有输出层神经元进行激活函数处理。只能解决线性可分问题。要解决非线性可分问题,需要使用多层功能神经元。
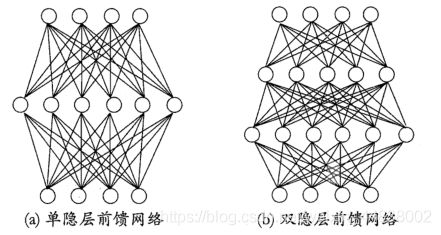
常见的神经网络是如下图所示的层级结构,每层神经元与下一层神经元全部互连,不存在同层连接也不存在跨层连接。此神经网络结构被称为“多层前馈神经网络”。输入层神经元仅接受输入,不进行函数处理,隐层与输出层包含功能神经元。只需包含隐层就可称为多层结构。神经网络的过程就是根据数据调整各层神经元之间的权重以及每个功能神经元的阈值。
BP算法
欲训练多层神经网络,可使用BP算法即误差逆传播算法。BP算法不仅可用于多层前馈神经网络,还可用于其他类型的神经网络。但大多数情况下,介绍“BP网络”时,指的是用BP算法训练的多层前馈神经网络。
给定训练集

即输入为d个属性,输出为 l 维实值向量。
如下图所示

图中拥有d个输入神经元,l 个输出神经元,q个隐层神经元。其中,输入层第 i 个神经元与隐层第h个神经元之间的权重为vih,隐层第h个神经元与输出层第j个神经元之间的权重为whj。假设隐层和输出层神经元使用的激活函数都是Sigmoid函数。
神经网络的输出为:

神经网络的均方误差为:
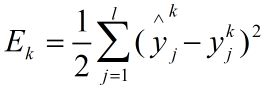
上图中输入层到隐层的dq个权重,隐层到输出层的ql个权重,q个隐层神经元的阈值, l 个输出层神经元的阈值。这些参数需要确定。
BP算法的工作流程:
对每个训练样例,先将输入示例提供给输入层神经元,然后逐层将信号前传,直到产生输出层结果,再计算输出层的误差,再将误差逆向传播至隐层神经元,最后根据隐层神经元的误差对权重和阈值进行调整。该迭代过程循环进行,直到训练误差达到很小值时停止。
BP算法的目标是使训练集上的累积误差最小,累积误差为
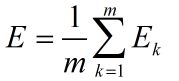
标准BP算法是针对每一个训练样例更新连接权重和阈值,若类似的推导出累积误差最小化的更新就得到了累积BP算法。标准BP算法针对单个样例,需要多次迭代,累积BP算法直接针对累积误差,其参数更新的频率低得多。
全局最小与局部最小
若用E表示神经网络在训练集上的误差,则它显然是关于连接权重和阈值的函数,此时,神经网络的训练过程可看作在参数空间中,寻找一组最优参数使得E最小。
误差函数具有局部最小值和全局最小值,每次迭代中,先计算误差函数在当前的梯度,再根据梯度确定搜索方向。若误差函数在当前的梯度为0,则已达局部最小,故参数的迭代过程停止。若函数仅有一个局部最小,那么该局部最小就是全局最小,但是,若误差函数有多个局部最小值,那么就不能保证该局部最小值就是全局最小值。这时参数陷入了局部极小。
遗传算法常被用来训练神经网络逼近全局最小。
BP神经网络设计
1、对数据进行归一化即标准化处理
2、BP神经网络最多只需要俩个隐层,在设计的时候一般先只考虑设一个隐层,当一个隐层的节点数很多但是依然不能改善网络情况时,才考虑增加一个隐层。经验表明,如果在第一个隐层较多的节点数,第二个隐层较少的节点数,可以改善网络性能。
3、输入层节点数取决于输入向量的维数。
4、隐层节点数通常是根据公式给出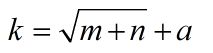
m 和 n 分别为输出层和输入层的神经元个数,根据最低值选取来选取 a 值,a 为 1 到10 的常数。
BP算法实例——基于python
选取UCI数据集中的wine数据,计算Wine 测试集上的分类准确率,代码如下
//
from sklearn import *
import sklearn
import pandas as pd
import numpy as np
# 基于 Wine 数据集(3 个类,13 个解释变量)
# 导入数据
url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data'
da = pd.read_csv(url, header= None)
da.columns = [ 'Class', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity ofash', 'Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols','Proanthocyanins', 'Color intensity', 'Hue',
'OD280/OD315 of diluted wines', 'Proline']#加上每列名称
# 对数据中的解释变量进行标准化处理,得到处理后的数据 data
x=np.array(da.iloc[:, 1:14])
min_max_scaler = preprocessing.MinMaxScaler()
x_minmax = min_max_scaler.fit_transform(x)
print(x_minmax)
y = np.array(da.iloc[:, 0])
y1 = y[:, np.newaxis] # 将一维数组 y 转化为二维数组
data= np.concatenate((x_minmax, y1), axis=1) # 拼接 x、y 两个数组
# 划分训练集和测试集
X, Y = np.split(data, (13,), axis=1)
X_train, X_test, Y_train, Y_test = sklearn.model_selection.train_test_split(X, Y, random_state=1,train_size=0.6)
Xtr = X_train
Xte = X_test
#转换成列表形式
a = Y_train.astype(int)
y_tr = []
for m in range(0, a.shape[0]):
for i in a[m]:
y_tr.append(i)
ytr = [i-1 for i in y_tr]
b = Y_test.astype(int)
y_te = []
for m in range(0, b.shape[0]):
for j in b[m]:
y_te.append(j)
yte = [j-1 for j in y_te]
# 在训练集上训练得到 BP 神经网络分类器
# 随机地初始化参数
D = 13 # 解释变量维度
K = 3 # 类别
h = 100 # 隐藏层大小
W = 0.01 * np.random.randn(D, h)
b = np.zeros((1,h))
W2 = 0.01 * np.random.randn(h, K)
b2 = np.zeros((1,K))
step_size = 1e-0
reg = 1e-3
# 梯度下降循环
num_examples = Xtr.shape[0]
for i in range(10000):
# 计算分类得分
hidden_layer = np.maximum(0, np.dot(Xtr, W) + b)
scores = np.dot(hidden_layer, W2) + b2
# 计算分类概率
exp_scores = np.exp(scores)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims= True)
# 计算损失
correct_logprobs = -np.log(probs[range(num_examples), ytr])
data_loss = np.sum(correct_logprobs)/num_examples
reg_loss = 0.5 * reg * np.sum(W * W) + 0.5 * reg * np.sum(W2 * W2)
loss = data_loss + reg_loss
if i % 1000 == 0:
print( "iteration %d: loss %f" % (i, loss))
# 计算得分上的梯度
dscores = probs
dscores[range(num_examples), ytr] -= 1
dscores /= num_examples
# 反向传递,调整参数
dW2 = np.dot(hidden_layer.T, dscores)
db2 = np.sum(dscores, axis=0, keepdims= True)
dhidden = np.dot(dscores, W2.T)
dhidden[hidden_layer <= 0] = 0
dW = np.dot(Xtr.T, dhidden)
db = np.sum(dhidden, axis=0, keepdims= True)
dW2 += reg * W2
dW += reg * W
# 更新参数
W += -step_size * dW
b += -step_size * db
W2 += -step_size * dW2
b2 += -step_size * db2
# 计算分类精度
hidden_layer2 = np.maximum(0, np.dot(Xte, W) + b)
scores2 = np.dot(hidden_layer2, W2) + b2
predicted_class2 = np.argmax(scores2, axis=1)
print( 'Wine 测试集上的分类准确率 : %.2f' % (np.mean(predicted_class2 ==yte)))
var foo = 'bar';参考
[1]:机器学习-周志华