【Ryo】MySQL:刷题训练牛客篇(一)
数据库是进行数据分析的“源泉”,对冗杂的数据进行整理和编排是数据分析的首要任务。同时将来职业生活中,对数据库系统进行DB操作也会是重要任务之一,因此掌握数据库语言刷题刷起来,至少对语言运用和数据库管理有所了解是题中之义。
本篇为牛客题霸的SQL训练题目练习记录(一),由于前面刷题还未写文故题目略有倒序。
| 研究内容 | 语言 | 日期 |
|---|---|---|
| 数据库 | sql | 2021年1月20日 |
1. 视图view
题目描述:
针对actor表创建视图actor_name_view,只包含first_name以及last_name两列,并对这两列重新命名,first_name为first_name_v,last_name修改为last_name_v:
CREATE TABLE actor (
actor_id smallint(5) NOT NULL PRIMARY KEY,
first_name varchar(45) NOT NULL,
last_name varchar(45) NOT NULL,
last_update datetime NOT NULL);
个人解答:
create view actor_name_view as
select first_name as first_name_v,last_name as last_name_v
from actor
注:本题在牛客后台OJ存在bug,解答代码应该是可以通过的
2. 强制索引搜索
题目描述:
针对salaries表emp_no字段创建索引idx_emp_no,查询emp_no为10005, 使用强制索引。
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
create index idx_emp_no on salaries(emp_no);
个人解答:
SELECT *
FROM salaries
FORCE INDEX (idx_emp_no)
WHERE emp_no = '10005'
3. 增添列
题目描述:
现在在last_update后面新增加一列名字为create_date, 类型为datetime, NOT NULL,默认值为’2020-10-01 00:00:00’
CREATE TABLE actor (
actor_id smallint(5) NOT NULL PRIMARY KEY,
first_name varchar(45) NOT NULL,
last_name varchar(45) NOT NULL,
last_update datetime NOT NULL);
个人解答:
alter table actor
add create_date datetime NOT NULL default'2020-10-01 00:00:00'
注:MySQL中default后不需要加括号。
4. 触发器
题目描述:
构造一个触发器audit_log,在向employees_test表中插入一条数据的时候,触发插入相关的数据到audit中。
CREATE TABLE employees_test(
ID INT PRIMARY KEY NOT NULL,
NAME TEXT NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR(50),
SALARY REAL
);
CREATE TABLE audit(
EMP_no INT NOT NULL,
NAME TEXT NOT NULL
);
个人解答:
create trigger audit_log
after insert on employees_test
for each row
begin
insert into audit values(new.id,new.name);
end
大佬的注释:在MySQL中,创建触发器语法如下:
Create trigger trigger_name
trigger_time trigger_event ON tbl_name
for each row
trigger_stmt
其中:
trigger_name:标识触发器名称,用户自行指定;
trigger_time:标识触发时机,取值为 BEFORE 或 AFTER;
trigger_event:标识触发事件,取值为 INSERT、UPDATE 或 DELETE;
tbl_name:标识建立触发器的表名,即在哪张表上建立触发器;
trigger_stmt:触发器程序体,可以是一句SQL语句,或者用 BEGIN 和 END 包含的多条语句,每条语句结束要分号结尾。
5. 删除记录
题目描述:
删除emp_no重复的记录,只保留最小的id对应的记录。
CREATE TABLE IF NOT EXISTS titles_test (
id int(11) not null primary key,
emp_no int(11) NOT NULL,
title varchar(50) NOT NULL,
from_date date NOT NULL,
to_date date DEFAULT NULL);
insert into titles_test values ('1', '10001', 'Senior Engineer', '1986-06-26', '9999-01-01'),
('2', '10002', 'Staff', '1996-08-03', '9999-01-01'),
('3', '10003', 'Senior Engineer', '1995-12-03', '9999-01-01'),
('4', '10004', 'Senior Engineer', '1995-12-03', '9999-01-01'),
('5', '10001', 'Senior Engineer', '1986-06-26', '9999-01-01'),
('6', '10002', 'Staff', '1996-08-03', '9999-01-01'),
('7', '10003', 'Senior Engineer', '1995-12-03', '9999-01-01');
个人解答:
DELETE FROM titles_test
WHERE id NOT IN (
SELECT *
FROM(
SELECT MIN(id)
FROM titles_test
GROUP BY emp_no
) AS a);
大佬的注释:本题高赞答案在MySQL中会出错。抛出异常:ERROR 1093 (HY000): You can’t specify target table ‘titles_test’ for update in FROM clause。经查询,MySQL的UPDATE或DELETE中子查询不能为同一张表,可将查询结果再次SELECT。即以下为错误解答:
DELETE FROM titles_test WHERE id NOT IN
(SELECT MIN(id) FROM titles_test GROUP BY emp_no)
6. 子查询
题目描述:
获取所有部门中员工薪水最高的相关信息,给出dept_no, emp_no以及其对应的salary,按照部门编号升序排列
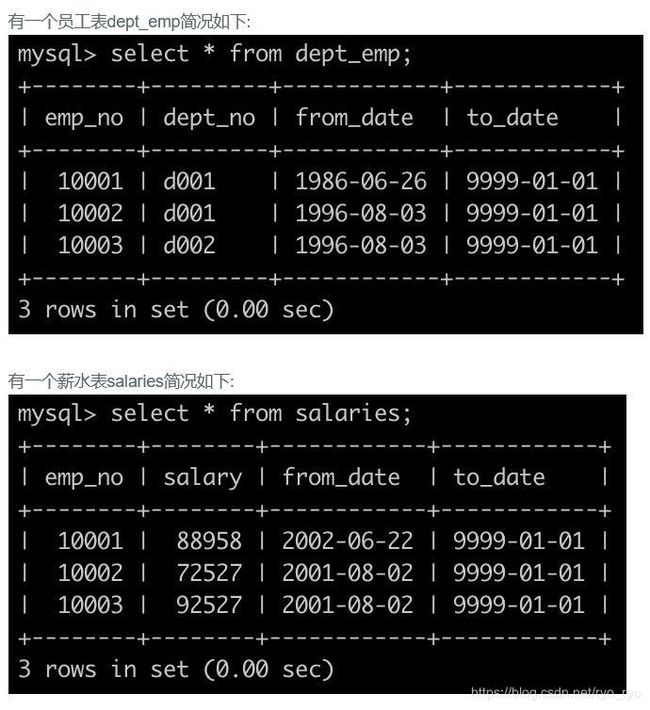
个人解答:
SELECT d1.dept_no, d1.emp_no, s1.salary
FROM dept_emp as d1
INNER JOIN salaries as s1
ON d1.emp_no=s1.emp_no
AND d1.to_date='9999-01-01'
AND s1.to_date='9999-01-01'
WHERE s1.salary in (SELECT MAX(s2.salary) #第二张表:最高工资,光有max是不行的,非聚合什么的不明白
FROM dept_emp as d2
INNER JOIN salaries as s2
ON d2.emp_no=s2.emp_no
AND d2.to_date='9999-01-01'
AND s2.to_date='9999-01-01'
AND d2.dept_no = d1.dept_no
)
ORDER BY d1.dept_no;
大佬说的一个点,聚合函数的问题一直没搞懂:MAX(SALARY) 和 emp_no 不一定对应!GROUP BY 默认取非聚合的第一条记录!!!!!!