基于kubernetes-1.23.1搭建EFK
Elasticsearch
概述:
Elasticsearch 是一个实时的,分布式的,可扩展的搜索引擎,它允许进行全文本和结构化搜索以及对日志进行分析。它通常用于索引和搜索大量日志数据,也可以用于搜索许多不同种类的文档。elasticsearch 具有三大功能,搜索、分析、存储数据。
特点:
1、分布式的文档存储引擎
2、分布式的搜索引擎和分析引擎
3、可以横向扩展至数百甚至数千个服务器节点,同时可以处理 PB 级数据。
常见的日志收集组件对比分析
1、Logstash
Logstash 是一个开源数据收集引擎,具有实时管道功能。Logstash 可以动态地将来自不同数据源的数据统一起来,并将数据标准化输出到你所选择的目的地。logstash 具有 filter 功能,能过滤分析日志
优势:
Logstash 主要的优点就是它的灵活性,主要因为它有很多插件,我们基本上可以在网上找到很多资源,几乎可以处理任何问题。
劣势:
Logstash 的问题是它的性能以及资源消耗(默认的堆大小是 1GB)。另一个问题是它目前不支持缓存,目前的典型替代方案是将 Redis 或 Kafka 作为中心缓冲池。
2、Filebeat
Filebeat 是一个轻量级的日志传输工具,它的存在正弥补了 Logstash 的缺点:Filebeat 作为一
个轻量级的日志传输工具可以将日志推送到中心 Logstash。
在版本 5.x 中,Elasticsearch 具有解析的能力(像 Logstash 过滤器)— Ingest。这也就意味着可
以将数据直接用 Filebeat 推送到 Elasticsearch,并让 Elasticsearch 既做解析的事情,又做存
储的事情。
不需要使用缓冲,因为 Filebeat 也会和 Logstash 一样记住上次读取的偏移,如果需要缓冲(例
如,不希望将日志服务器的文件系统填满),可以使用 Redis/Kafka,因为 Filebeat 可以与它们进
行通信。
优势:
Filebeat 只是一个二进制文件没有任何依赖。它占用资源极少。
一般结构都是 filebeat 采集日志,然后发送到消息队列,redis,kafaka。然后 logstash 去获取,利用 filter 功能过滤分析,然后存储到 elasticsearch 中。
3、Fluentd
fluentd 是一个针对日志的收集、处理、转发系统。通过丰富的插件系统,可以收集来自于各种系统或应用的日志,转化为用户指定的格式后,转发到用户所指定的日志存储系统之中。
fluentd 常常被拿来和 Logstash 比较,我们常说 ELK,L 就是这个 agent。fluentd 是随着Docker,和 es 一起流行起来的 agent。
优势:
fluentd 比 logstash 更省资源。
EFK日志处理流程
filebeat从各个节点的Docker容器提取日志信息,并转发到ElasticSearch
ElasticSearch进行索引和保存
Kibana负责分析和可视化日志信息
在k8s中安装EFK组件
1. 安装elasticsearch组件
kubectl create ns kube-logging #创建名称空间
kubectl get namespaces | grep kube-logging #查看是否创建成功
创建headless service,yaml文件内容如下:
cat elasticsearch_svc.yaml
apiVersion: v1
metadata:
name: elasticsearch
namespace: kube-logging
labels:
app: elasticsearch
spec:
selector:
app: elasticsearch
clusterIP: None
ports:
- port: 9200
name: rest
- port: 9300
name: inter-node
kubectl apply -f elasticsearch_svc.yaml #应用yaml文件
kubectl get services --namespace=kube-logging #查看是否创建成功
创建storageclass,yaml文件内容如下(需提前准备好nfs、nfsprovisioner环境):
cat es_class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: do-block-storage
provisioner: example.com/nfs
kubectl apply -f es_class.yaml
使用statefulset部署es集群,yaml文件内容如下:
cat elasticsearch-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-cluster
namespace: kube-logging
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: elasticsearch:7.12.1
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.seed_hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
- name: cluster.initial_master_nodes
value: "es-cluster-0,es-cluster-1,es-cluster-2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
initContainers:
- name: fix-permissions
image: busybox
imagePullPolicy: IfNotPresent
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
imagePullPolicy: IfNotPresent
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
imagePullPolicy: IfNotPresent
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: do-block-storage
resources:
requests:
storage: 10Gi
kubectl apply -f elasticsearch-statefulset.yaml
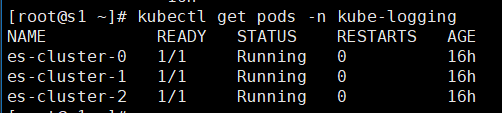
kubectl get pods -n kube-logging #查看pod情况
kubectl get svc -n kube-logging

pod 部署完成之后,可以通过 REST API 检查 elasticsearch 集群是否部署成功,在管理节点使用下面的命令将本地端口 9200 转发到 Elasticsearch 节点(如 es-cluster-0)对应的端口:
kubectl port-forward es-cluster-0 9200:9200 --namespace=kube-logging
打开一个新的控制节点的终端,执行如下请求:
curl http://localhost:9200/_cluster/state?pretty
第一次请求结果可能为空,之后有数据,输出如下:

看到上面的信息就表明我们名为 k8s-logs 的 Elasticsearch 集群成功创建了 3 个节点:escluster-0,es-cluster-1,和 es-cluster-2,当前主节点是 es-cluster-2。
2. 安装kibana组件
编写deployment和service的yaml文件,内容如下:
cat kibana.yaml
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: kube-logging
labels:
app: kibana
spec:
ports:
- port: 5601
selector:
app: kibana
type: NodePort
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: kube-logging
labels:
app: kibana
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: kibana:7.12.1
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch:9200
ports:
- containerPort: 5601
kubectl apply -f kibana.yaml
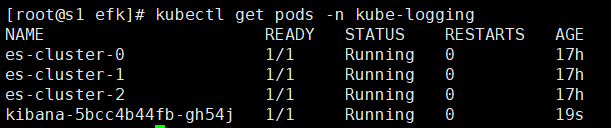
kubectl get pods -n kube-logging #查看pod情况
kubectl get svc -n kube-logging #查看svc情况

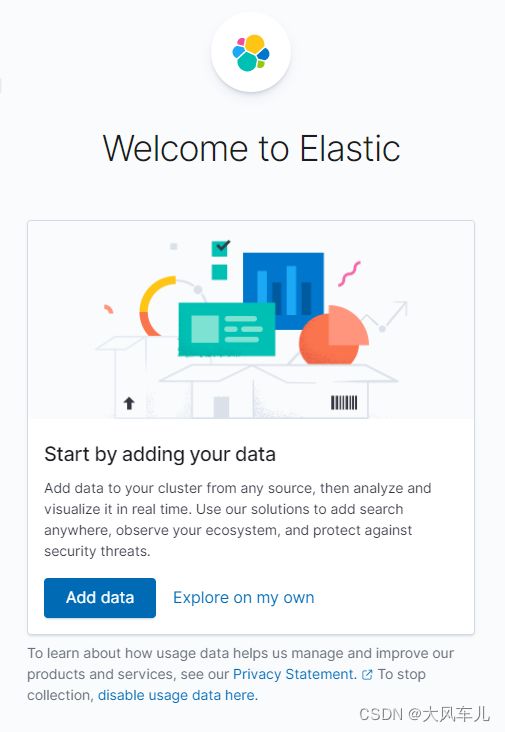
在浏览器打开http://
3. 安装fluentd组件
使用daemonset安装fluentd组件,保证集群中每个节点运行同样的pod副本来收集对应节点的日志。在 k8s 集群中,容器应用程序的输入输出日志会重定向到 node 节点里的 json 文件中,fluentd 可以 tail 和过滤以及把日志转换成指定的格式发送到 elasticsearch 集群中。除了容器日志,fluentd 也可以采集 kubelet、kube-proxy、docker 的日志。
下面是yaml文件内容:
cat fluentd.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
labels:
app: fluentd
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: kube-logging
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-logging
labels:
app: fluentd
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
serviceAccount: fluentd
serviceAccountName: fluentd
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: fluentd:v1.9.1-debian-1.0
imagePullPolicy: IfNotPresent
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.kube-logging.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENTD_SYSTEMD_CONF
value: disable
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
kubectl apply -f fluentd.yaml
kubectl get pods -n kube-logging
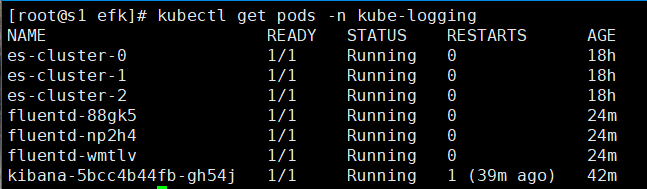
到这里fluentd安装完成,接下来到kibana web界面进行配置。
点击Explore on my own
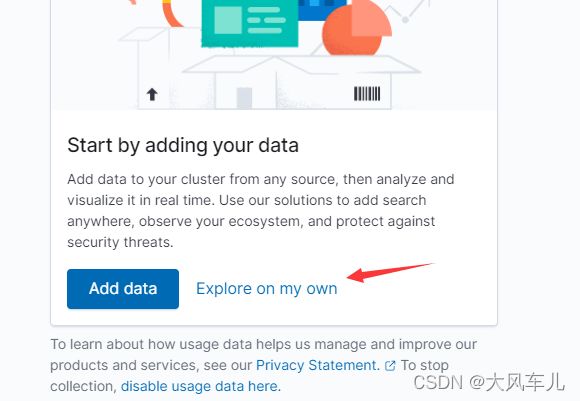
按照下图所示,找到创建索引界面。


在这里可以配置我们需要的 Elasticsearch 索引,前面 Fluentd 配置文件中我们采集的日志使用的是 logstash 格式,这里只需要在文本框中输入 logstash-*即可匹配到 Elasticsearch 集群中的所有日志数据,然后点击下一步,进入以下页面:
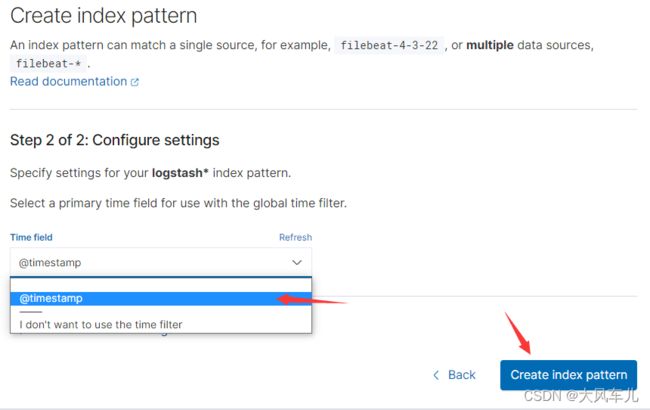
选择@timestamp,创建索引。
点击左侧的 discover,可看到如下:

至此EFK环境搭建成功!
注意
用到的相关镜像可提前下载,以提高部署速度。
相关配置已封装到镜像里,docker工作目录必须是/var/lib/docker ,否则会出现创建不了索引的情况。