Spark结构化流应用编程模式
Spark结构化流应用编程模式
- 一、实验目的
- 二、实验内容
- 三、实验原理
- 四、实验环境
- 五、实验步骤
-
- 5.1 启动Spark集群
- 5.2 应用Spark结构化流处理,读取Socket数据源,实时进行词频统计
- 5.3 应用Spark结构化流处理,读取文件数据源,实时进行词频统计
- 六、 实验知识测试
- 七、实验拓展
申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址
全文共计3663字,阅读大概需要3分钟
一、实验目的
掌握Spark结构化流编程模型。
掌握不同数据源的连接方式。
二、实验内容
1、应用Spark结构化流处理,读取Socket数据源,实时进行词频统计。
2、应用Spark结构化流处理,读取文件数据源,实时进行词频统计。
三、实验原理
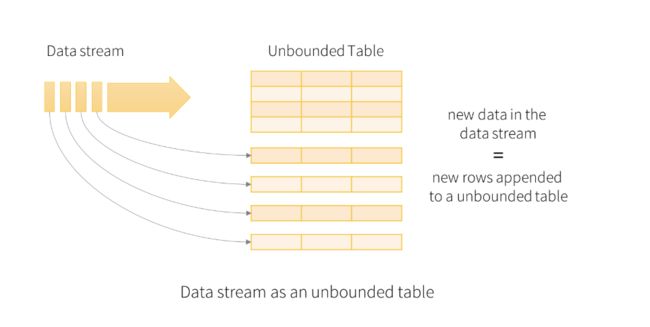
结构化流中的关键思想是将实时数据流视为连续追加的表。这导致新的流处理模型非常类似于批处理模型。您将流式计算表示为静态表上的标准批处理查询,Spark将其作为无界输入表上的增量查询运行。
将输入数据流视为“输入表”。到达流的每个数据项都像一个新行被附加到输入表。
四、实验环境
硬件:x86_64 ubuntu 16.04服务器
软件:JDK 1.8,Spark-2.3.2,Hadoop-2.7.3
五、实验步骤
5.1 启动Spark集群
1、在终端窗口下,执以如下命令,分别启动HDFS集群和Spark集群:
1. $ start-dfs.sh
2. $ cd /opt/spark
3. $ ./sbin/start-all.sh
然后使用jps命令,查看Spark集群是否已经正确启动。
2、在HDFS上创建要用到的目录。在终端窗口中,执行以下命令:
1. $ hdfs dfs -mkdir -p /data/dataset/streaming
3、启动spark-shell。在终端窗口中,执行以下命令:
1. $ spark-shell
5.2 应用Spark结构化流处理,读取Socket数据源,实时进行词频统计
1、读取Socket数据源。在spark-shell窗口下,输入以下代码并执行:
1. val lines = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).load()
2、对读取到的每行数据进行分割。在spark-shell窗口下,输入以下代码并执行:
1. val words = lines.as[String].flatMap(_.split(" "))
3、对分割后的函数进行分组,分组后统计每组的个数。在spark-shell窗口下,输入以下代码并执行:
1. val wordCounts = words.groupBy("value").count()
4、启动nc服务。打开另一个终端窗口,执行以下命令:
1. nc -lp 9999
请勿关闭此终端窗口,保持nc服务处于运行状态。
5、启动流程序,并将计算结果输出到控制台。切换回spark-shell窗口,输入以下代码,并执行:
1. val query = wordCounts.writeStream.format("console").outputMode("complete").start()
6、再切换到nc服务窗口,随意输入一些内容,单词之间以空格分隔。如下所示:
1. scala python java
2. scala java
7、查看计算结果。切换回spark-shell窗口,可以看到以下的计算输出:
1. -------------------------------------------
2. Batch: 0
3. -------------------------------------------
4. +------+-----+
5. | value|count|
6. +------+-----+
7. | scala| 1|
8. | java| 1|
9. |python| 1|
10. +------+-----+
11. -------------------------------------------
12. Batch: 1
13. -------------------------------------------
14. +------+-----+
15. | value|count|
16. +------+-----+
17. | scala| 2|
18. | java| 2|
19. |python| 1|
20. +------+-----+
8、停止流计算。在spark-shell窗口,执行以下代码:
1. query.stop
或者,同时按下【Ctrl + C】键,终止计算。
5.3 应用Spark结构化流处理,读取文件数据源,实时进行词频统计
Spark结构化流支持将目录中写入的文件作为数据流读取。支持的文件格式为text、csv、json、orc、parquet等。请注意,文件必须原子地放置在给定目录中,在大多数文件系统中,可以通过文件移动操作来实现。
1、读取文件数据源。在spark-shell窗口下,输入以下代码并执行:
1. val lines = spark.readStream.format("text").text("hdfs://localhost:9000/data/dataset/streaming")
2、对读取到的每行数据进行分割。在spark-shell窗口下,输入以下代码并执行:
1. val words = lines.as[String].flatMap(_.split(" "))
3、对分割后的函数进行分组,分组后统计每组的个数。在spark-shell窗口下,输入以下代码并执行:
1. val wordCounts = words.groupBy("value").count()
2.
3. val query = wordCounts.writeStream.format("console").outputMode("complete").start()
4. query.awaitTermination()
4、模拟新文件生成。另打开一个终端窗口,执行以下命令,将”/data/dataset/streaming/hello.txt”上传到Spark流程序所监听的目录中:
1. $ hdfs dfs -put /data/dataset/streaming/hello.txt /data/dataset/streaming/
5、查看程序执行结果。切换回spark-shell窗口,可以看到如下输出内容:
1. -------------------------------------------
2. Batch: 0
3. -------------------------------------------
4. +------+-----+
5. | value|count|
6. +------+-----+
7. | scala| 2|
8. | spark| 1|
9. |hadoop| 1|
10. |python| 2|
11. +------+-----+
6、再切换到另一个终端窗口,执行如下命令,再向HDFS的”/data/dataset/streaming/“目录下拷贝另一个文件:
1. $ hdfs dfs -put /data/dataset/streaming/hello1.txt /data/dataset/streaming/
7、查看程序执行结果。切换回spark-shell窗口,可以看到如下输出内容:
1. -------------------------------------------
2. Batch: 0
3. -------------------------------------------
4. +------+-----+
5. | value|count|
6. +------+-----+
7. | scala| 2|
8. | spark| 1|
9. |hadoop| 1|
10. |python| 2|
11. +------+-----+
12.
13. -------------------------------------------
14. Batch: 1
15. -------------------------------------------
16. +------+-----+
17. | value|count|
18. +------+-----+
19. | scala| 4|
20. | spark| 2|
21. |hadoop| 2|
22. |python| 4|
23. +------+-----+
由结果可知,没当有新文件产生时,就会自动进行监控,并对数据进行统计。
六、 实验知识测试
无
七、实验拓展
无