模型性能评估——Python代码实现
性能度量的作用:衡量模型的泛化能力,评价模型的好坏。
但是不同的任务需求需要不同的性能度量,而导致不同的评估结果,因此好坏是相对的。
一、二分类
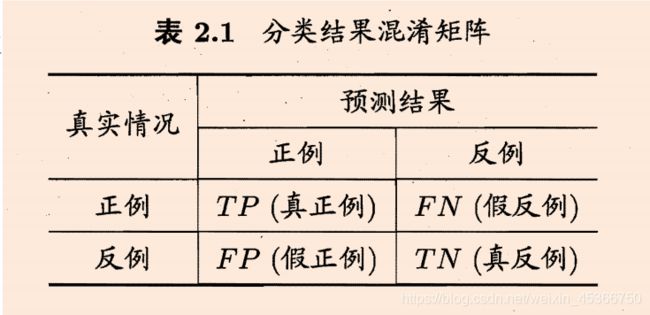
from sklearn import metrics
print(metrics.confusion_matrix(y_train,lr_y_train))
print(metrics.confusion_matrix(y_test,lr_y_test))
1.accuracy准确率
- acc是预测准确占所有预测结果的比例
- acc=(TP+TN)/(TP+TN+FP+FN)
- 优点:计算简单,常用
- 缺点:容易收到样本量及正负样本不均衡的影响
from sklearn import metrics
print('训练集准确率:',round(metrics.accuracy_score(y_train,lr_y_train)*100,2),'%') # 训练集
print('测试集准确率:',round(metrics.accuracy_score(y_test,lr_y_test)*100,2),'%')# 预测集
2.Precision精确率、Recall召回率、F1score
仅在二分类情况下适用
(1)Precision表示预测是正样本中确实是正样本的比例。
Precision=TP/(TP+FP)
(2)Recall表示确实是正样本中被预测是正的比例。
Recall=TP/(TP+FN)
(3)F1是精确率和召回率的加权调和平均数。P(精确率)与R(召回率)是此消彼长的,F1是由此构建的综合指标。

from sklearn.metrics import precision_score, recall_score, f1_score
p = precision_score(y_true, y_pred, average='binary') # 二分零
r = recall_score(y_true, y_pred, average='binary')
f1score = f1_score(y_true, y_pred, average='binary')
3.ROC-AUC
- ROC曲线的计算指标是灵敏度和特异度。灵敏度(TPR):本质上是正样本召回,特异度(TNR):本质上是负样本的召回率
- 优点:不受样本不均衡问题的影响
from sklearn import metrics
from sklearn.metrics import roc_curve,auc
fpr,tpr,threshold=roc_curve(y_train,y_pred_train)
fpr,tpr,threshold=roc_curve(y_test,lr_y_predict)
auc(fpr,tpr) # 0.5~1,越大表示模型性能越好
二、多分类
1.accuracy准确率
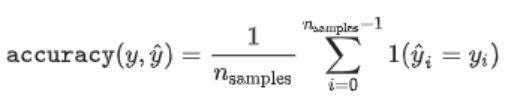
metrics.accuracy_score(y_true=y_true, y_pred=y_pred)
2.平均准确率
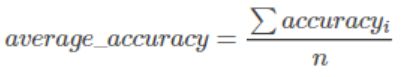
metrics.average_precision_score(y_true=y_true, y_score=y_pred)
3.基于相似度的评价指标
https://blog.csdn.net/weixin_37801695/article/details/86496595
4.混淆矩阵
metrics.confusion_matrix(y_true, y_pred) # 对角线值越大说明分类越正确
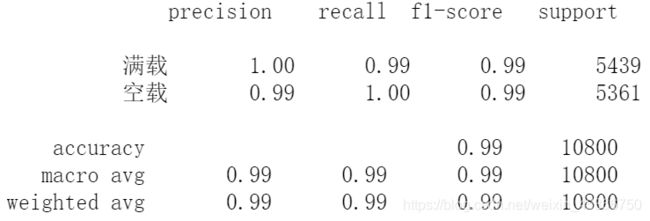
5.分类报告
from sklearn.metrics import classification_report
print(classification_report(y_true, y_pred, target_names=[' ',' ']))
# precision:本分类的结果中准确的比例
# recall:本该属于本分类的情况中正确分类的比例。recall越大,表示对本分类的识别效果越好,错分到其他类的比例越小。
三、回归
1.MAE
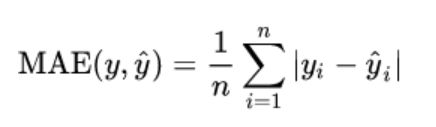
from sklearn.metrics import mean_absolute_error
mean_absolute_error(y_true, y_pred)
2.MSE
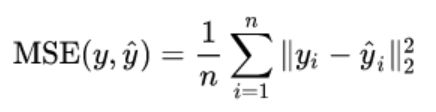
from sklearn.metrics import mean_squared_error
mean_squared_error(y_true, y_pred)
3.RMSE
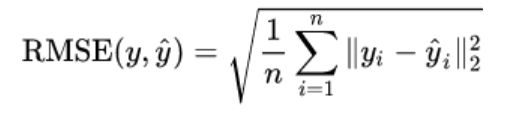
from sklearn.metrics import mean_squared_error
np.sqrt(mean_squared_error(y_true,y_pred))