Spark机器学习--运用逻辑回归分析银行营销数据
Spark机器学习--运用逻辑回归分析银行营销数据
一、介绍
1.1 内容
存款营销是银行吸收存款的主要经营模式,通过现有数据建立模型来判断客户是否订阅存款业务,从而帮助商业银行更好的分配人力资源,提高业务量,以满足现阶段营销活动对提高营销成功率的期望。
本实验会使用spark机器学习中的逻辑回归算法,分析银行营销数据,按照机器学习开发步骤,建立逻辑回归模型,预测客户是否会存款,并评估预测模型的精确度。
实验将采用如下步骤进行回归机器学习算法开发:

1.2 知识点
- Spark机器学习开发的常规步骤
- Spark框架提供的特征转换算法--StringIndex
- Spark框架提供的特征转换算法--OneHotEncoder
- Spark提供的API对预测结果准确度进行评估
- Spark SQL在Spark机器学习中的用法
1.3 环境
- 编程语言为Scala
- 编程软件为实验环境中提供的Scala IDE工具
- Spark API版本为2.1
二、理论学习
2.1 逻辑回归(Logistic Regression)
机器学习算法分为监督学习算法和无监督学习算法,在监督学习算法中,算法有目标变量(即预测值)和特征变量等两种变量,根据目标变量的值是离散值还是连续数值,分为分类算法(目标变量的值为离散值,如 是/否、0/1)和回归算法(目标变量为连续值)。
逻辑回归是一个分类算法而不是回归算法。通常是利用已知的特征变量来预测一个离散型目标变量的值(如0/1,是/否,真/假)。通过拟合一个逻辑函数来预测一个事件发生的概率,预测值是一个概率值(0-100%),根据概率值的大小,映射为目标变量的分类值,如:概率值大于等于 50%,映射目标变量分类值为 1,概率值小于 50%,映射目标变量分类值为 0。
2.2 逻辑回归与线性回归
为了更好理解逻辑回归算法,可以与线性回归算法做个对比。线性回归对多维空间中存在的样本点,用特征的线性组合去拟合多维空间中点的分布和轨迹。线性回归的公式如下: 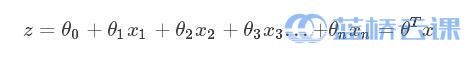 对于逻辑回归来说,其思想也是基于线性回归。其公式如下:
对于逻辑回归来说,其思想也是基于线性回归。其公式如下: 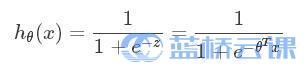 其中,
其中, 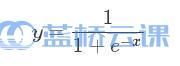 被称作sigmoid函数,Logistic Regression算法将线性函数的结果映射到了sigmoid函数中。sigmoid的函数图形如下:
被称作sigmoid函数,Logistic Regression算法将线性函数的结果映射到了sigmoid函数中。sigmoid的函数图形如下:
hθ(x)<0.5 则说明当前样本数据属于A类;
hθ(x)>0.5 则说明当前样本数据属于B类。
所以可以将sigmoid函数看成样本数据的概率函数。Spark提供的逻辑回归算法,对样本数据的预测结果中,有一列存储了概率值。本实验中将此概率值进行了输出。
2.3 特征工程
特征工程是最大限度地从原始数据中提取特征以供算法和模型使用的过程。特征工程包括特征提取、特征转换、降维等操作。 Spark提供了多种特征工程算法,详细内容可查看官方文档。
本实验中,我们使用 StringIndex 和 OneHotEncoder 两种特征转换算法。
2.2.1 StringIndex
StringIndexer 是指把一组字符型标签编码成一组数值型标签索引,索引的范围为 0 到标签数量,索引构建的顺序为标签的频率,优先编码频率较大的标签,所以出现频率最高的标签为 0 号。如果输入的是数值型的,会转成字符型,再对其进行编码。
Spark官方实例: 下列数据,包括id和category两列:
id | category
----|----------
0 | a
1 | b
2 | c
3 | a
4 | a
5 | c
使用StringIndexer特征转换算法,对上述数据category列进行特征转换,设置生成新列名为categoryIndex,结果为:
id | category | categoryIndex
----|----------|---------------
0 | a | 0.0
1 | b | 2.0
2 | c | 1.0
3 | a | 0.0
4 | a | 0.0
5 | c | 1.0
上述结果中,由于 a 出现了 3 次,c 出现了 2 次,b 出现了 1 次,按照出现频率由高到低,从 0 开始编码,所以 a 的编码为 0.0,c 的编码为1.0,b 的编码为2.0。
2.2.2 OneHotEncoder
OneHot编码将已经转换为数值型的类别特征,映射为一个稀疏向量对象,对于某一个类别映射的向量中只有一位有效,即只有一位数字是 1,其他数字位都是 0。如下面的例子,有如下两个特征属性:
- 婚姻状况:["已婚","单身","离异","未知"]
- 有无房贷:["有房贷","无房贷"]
对于某一个样本,如["已婚","无房贷"],因为机器学习算法不接收字符型的特征值,我们需要将这个分类值的特征数字化,最直接的方法,可以采用序列化的方式:[0,1]。但是这样的特征处理并不能直接放入机器学习算法中。对于这个问题,婚姻状况是4维的,有无房贷是2维的,这样,我们可以采用One-Hot编码的方式对上述的样本["已婚","无房贷"]编码,"已婚"对应[1,0,0,0],"无房贷"对应[0,1],则完整的特征数字化的结果为:[1,0,0,0,0,1],这样做结果就是数据会变得连续,但也会非常的稀疏,所以在Spark中,使用了稀疏向量来表示这个结果。
逻辑回归算法的分类器需要连续数值作为特征输入。
三、步骤
3.1 获取银行营销数据
通过命令,可获取本次实验数据。
wget http://labfile.oss.aliyuncs.com/courses/990/bank_marketing_data.zip
该数据来自于https://github.com/ChitturiPadma/datasets/blob/master/bank_marketing_data.csv
在本实验中所用到的实验数据都存储在/opt/train/bank_marketing_data.csv,注意下载数据后,请拷贝到对应的路径下。下面的代码以此作为依据。
3.2 分析营销数据结构
3.2.1 数据结构描述
在数据bank_marketing_data.csv中,包含4万多条记录和21个字段,本次实验中,我们使用其中10个字段作为因变量,1个字段作为目标变量,进行分析预测。11个字段的名称和中文含义如下:
| 字段名称 | 中文含义 |
|---|---|
| age | 客户年龄 |
| job | 客户职业 |
| marital | 婚姻状况 |
| default | 是否有信用违约 |
| housing | 是否有住房贷款 |
| loan | 是否有住房贷款 |
| duration | 最后一次联系持续时间(秒) |
| previous | 之前活动中与用户联系次数 |
| poutcome | 之前市场营销活动的结果 |
| empvarrate | 就业变化速率 |
| y | 目标变量,本次活动实施结果:是否同意存款 |
3.2.2 编写程序查看数据结构
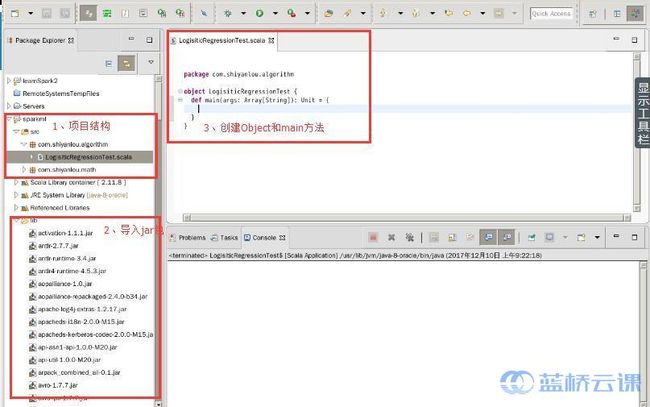
- 打开开发环境:ScalaIDE,创建一个Scala项目:sparkml,创建
package:com.shiyanlou.algorithm用来存放机器学习算法相关的程序。创建Scala Object:LogisiticRegressionTest。 - 将
/opt/spark-2.1.0-bin-hadoop2.6/jars/目录下的所有jar包引入到项目类路径。 - 在
LogisiticRegressionTest Object中创建main方法,此时的项目结构如下:
- 在main方法中编写如下代码:
//实例化SparkSession对象 val spark=SparkSession.builder().appName("Logistic_Prediction").master("local").getOrCreate() //设置日志级别,减少日志输出,便于查看运行结果 spark.sparkContext.setLogLevel("WARN") //导入隐式转换包,方便使用转换函数 import spark.implicits._ //读取数据,传入数据路径/opt/train/bank_marketing_data.csv val bank_Marketing_Data=spark.read .option("header", true) .option("inferSchema", "true") .csv("/opt/train/bank_marketing_data.csv") //查看营销数据的前5条记录,包括所有字段 println("all columns data:") bank_Marketing_Data.show(5) //读取营销数据指定的11个字段,并将age、duration、previous三个字段的类型从Integer类型转换为Double类型 val selected_Data=bank_Marketing_Data.select("age", "job", "marital", "default", "housing", "loan", "duration", "previous", "poutcome", "empvarrate", "y") .withColumn("age", bank_Marketing_Data("age").cast(DoubleType)) .withColumn("duration", bank_Marketing_Data("duration").cast(DoubleType)) .withColumn("previous", bank_Marketing_Data("previous").cast(DoubleType)) //显示前5条记录,只包含指定的11个字段 println("11 columns data:") selected_Data.show(5) //显示营销数据的数据量 println("data count:"+selected_Data.count()) - 上述代码,首先实例化
SparkSession对象,接着读取营销数据bank_marketing_data.csv,将其中age,duration,previous三列由Integer转换成Double类型。查看数据信息,对要分析的数据有一个大概了解。需要注意的是:我们只分析数据中选中的11列,选中的数据存储在了selected_Data变量中。
运行程序,查看运行结果:
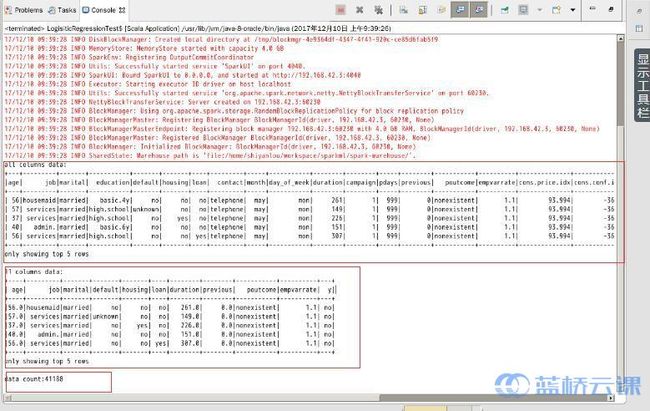
运行结果包括三部分:包含所有列的前5条记录、包含指定11列的前5条记录和数据总条数:41188条。
上述操作可执行完整代码如下:
package com.shiyanlou.algorithm
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types.DoubleType
object LogisiticRegressionTest {
def main(args: Array[String]): Unit = {
val spark=SparkSession.builder().appName("Logistic_Prediction").master("local").getOrCreate()
spark.sparkContext.setLogLevel("WARN")
import spark.implicits._
val bank_Marketing_Data=spark.read
.option("header", true)
.option("inferSchema", "true")
.csv("/opt/train/bank_marketing_data.csv")
println("all columns data:")
bank_Marketing_Data.show(5)
val selected_Data=bank_Marketing_Data.select("age",
"job",
"marital",
"default",
"housing",
"loan",
"duration",
"previous",
"poutcome",
"empvarrate",
"y")
.withColumn("age", bank_Marketing_Data("age").cast(DoubleType))
.withColumn("duration", bank_Marketing_Data("duration").cast(DoubleType))
.withColumn("previous", bank_Marketing_Data("previous").cast(DoubleType))
println("11 columns data:")
selected_Data.show(5)
println("data count:"+selected_Data.count())
}
}
3.3 概要分析数据字段内容
机器学习算法接收的数据都是向量对象,向量对象中的元素值都是数值型的。由于我们所分析的数据中存在非数值型的字段列,我们需要对其进行分析,尤其是包含分类值的字段列,需要统计出分类值和分类数量,为下一步的特征转换做准备。
3.3.1 在main方法中继续编写如下代码:
//对数据进行概要统计
val summary=selected_Data.describe()
println("Summary Statistics:")
//显示概要统计信息
summary.show()
//查看每一列所包含的不同值数量
val columnNames=selected_Data.columns
val uniqueValues_PerField=columnNames.map { field => field+":"+selected_Data.select(field).distinct().count() }
println("Unique Values For each Field:")
uniqueValues_PerField.foreach(println)
3.3.2 运行程序,查看运行结果。上述程序主要输出内容如下:
概要统计信息

统计信息输出,包括12列: 第1列为统计值,总数、平均值、方差值、最小值、最大值; 第2-12列为指定的数据字段值。从中可以看出每一列的总数、平均值、方差值、最小值、最大值是多少。如果某列内容不是数值,则某些统计信息会是null。
每一列包含多少个不同值

从输出可以看出,age列有78个不同的值,job列有12个不同的值,后续的输出可以以此类推... 需要注意:job、marital、default、housing、poutcome、loan这6列的值是分类值,如 marital列:婚姻状况,有已婚、单身、离异、未知等分类值。
截至到此可执行的完整代码如下:
package com.shiyanlou.algorithm
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types.DoubleType
object LogisiticRegressionTest {
def main(args: Array[String]): Unit = {
val spark=SparkSession.builder().appName("Logistic_Prediction").master("local").getOrCreate()
spark.sparkContext.setLogLevel("WARN")
import spark.implicits._
val bank_Marketing_Data=spark.read
.option("header", true)
.option("inferSchema", "true")
.csv("/opt/train/bank_marketing_data.csv")
println("all columns data:")
bank_Marketing_Data.show(5)
val selected_Data=bank_Marketing_Data.select("age",
"job",
"marital",
"default",
"housing",
"loan",
"duration",
"previous",
"poutcome",
"empvarrate",
"y")
.withColumn("age", bank_Marketing_Data("age").cast(DoubleType))
.withColumn("duration", bank_Marketing_Data("duration").cast(DoubleType))
.withColumn("previous", bank_Marketing_Data("previous").cast(DoubleType))
println("11 columns data:")
selected_Data.show(5)
println("data count:"+selected_Data.count())
val summary=selected_Data.describe()
println("Summary Statistics:")
summary.show()
val columnNames=selected_Data.columns
val uniqueValues_PerField=columnNames.map { field => field+":"+selected_Data.select(field).distinct().count() }
println("Unique Values For each Field:")
uniqueValues_PerField.foreach(println)
}
}
3.4 特征工程
经过对数据的概要分析,我们知道,营销数据中除了数值型的字段(age、duration、previous、empvarrate),还有一些包含分类值的字符型字段(job、marital、default、housing、poutcome、loan)。本步骤就要利用特征工程,对分类字段进行特征转换,使用spark提供的StringIndex和OneHotEncoder算法。
3.4.1 为了方便测试,我们在项目中新建一个Scala Object:LogisiticRegressionTest2,新建main方法。
3.4.2 在main方法中编写如下代码:
//实例化SparkSession对象
val spark=SparkSession.builder().appName("Logistic_Prediction").master("local").getOrCreate()
//设置日志级别,减少日志输出,便于查看运行结果
spark.sparkContext.setLogLevel("WARN")
//导入隐式转换包,方便使用转换函数
import spark.implicits._
//读取数据,传入数据路径/opt/train/bank_marketing_data.csv
val bank_Marketing_Data=spark.read
.option("header", true)
.option("inferSchema", "true") .csv("/opt/train/bank_marketing_data.csv")
//查看营销数据的前5条记录,包括所有字段
bank_Marketing_Data.show(5)
//读取营销数据指定的11个字段,并将age、duration、previous三个字段的类型从Integer类型转换为Double类型
val selected_Data=bank_Marketing_Data.select("age",
"job",
"marital",
"default",
"housing",
"loan",
"duration",
"previous",
"poutcome",
"empvarrate",
"y")
.withColumn("age", bank_Marketing_Data("age").cast(DoubleType))
.withColumn("duration", bank_Marketing_Data("duration").cast(DoubleType))
.withColumn("previous", bank_Marketing_Data("previous").cast(DoubleType))
val indexer = new StringIndexer().setInputCol("job").setOutputCol("jobIndex")
val indexed = indexer.fit(selected_Data).transform(selected_Data)
indexed.printSchema()
indexed.show
val encoder = new OneHotEncoder().setDropLast(false).setInputCol("jobIndex").setOutputCol("jobVec")
val encoded = encoder.transform(indexed)
encoded.show()
encoded.printSchema()
首先获取需要分析的数据字段,存入selected_Data变量,此步骤与上一个类LogisiticRegressionTest中的代码相同。 接着将对分类字段 job 使用 StringIndex 数据转换算法,将分类值转换为数值类型,输入列为 job,输出列为 jobIndex,为 OneHot 编码做准备。 然后对 jobIndex 字段使用 OneHotEncoder 数据转换算法,输入列为 StringIndex 数据转换算法的输出列,输出列为 jobVec。
输出结果如下:
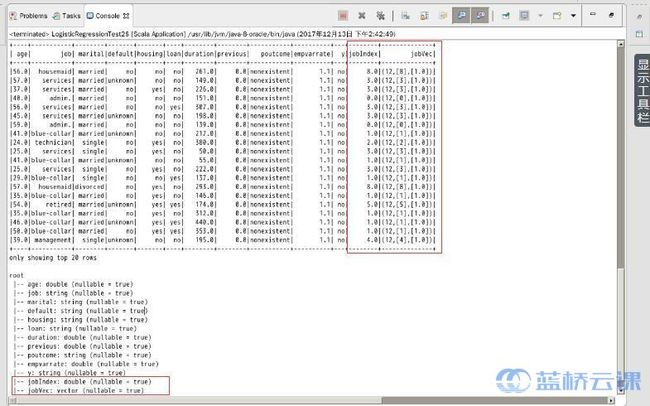
输出结果中的内容分为两部分:数据内容和数据结构。
从上方的数据内容可以看出,对 job 列应用数据转换算法(StringIndexer和OneHotEncoder),输出了新列:jobIndex 和 jobVec。 从下方的数据内容可以看出,jobIndex列为double类型,jobVec列为向量类型。
StringIndex 数据转换算法为数据增加了一列,列名为jobIndex,列类型为double,原始列job 并没有删除。由于原始列值不是数值型,无法参与向量运算,所以可以将对应的原始列删除;
OneHotEncoder 数据转换算法为数据增加了一列,列名为 jobVec,列类型为 Vector,原始列 jobIndex 并没有删除。
LogisiticRegressionTest2 类的完整代码如下:
package com.shiyanlou.algorithm
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types.DoubleType
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.feature.OneHotEncoder
object LogisticRegressionTest2 {
def main(args: Array[String]): Unit = {
val spark=SparkSession.builder().appName("Logistic_Prediction").master("local").getOrCreate()
spark.sparkContext.setLogLevel("WARN")
import spark.implicits._
val bank_Marketing_Data=spark.read
.option("header", true)
.option("inferSchema", "true")
.csv("/opt/train/bank_marketing_data.csv")
bank_Marketing_Data.show(5)
val selected_Data=bank_Marketing_Data.select("age",
"job",
"marital",
"default",
"housing",
"loan",
"duration",
"previous",
"poutcome",
"empvarrate",
"y")
.withColumn("age", bank_Marketing_Data("age").cast(DoubleType))
.withColumn("duration", bank_Marketing_Data("duration").cast(DoubleType))
.withColumn("previous", bank_Marketing_Data("previous").cast(DoubleType))
val indexer = new StringIndexer().setInputCol("job").setOutputCol("jobIndex")
val indexed = indexer.fit(selected_Data).transform(selected_Data)
indexed.printSchema()
indexed.show
val encoder = new OneHotEncoder().setDropLast(false).setInputCol("jobIndex").setOutputCol("jobVec")
val encoded = encoder.transform(indexed)
encoded.show()
encoded.printSchema()
}
}
3.4.3 同理,对marital、default、housing、poutcome、loan 等5个分类列进行 OneHot 编码,在 main 方法中已有代码后面,继续编写代码:
val indexer = new StringIndexer().setInputCol("job").setOutputCol("jobIndex")
val indexed = indexer.fit(selected_Data).transform(selected_Data)
val encoder = new OneHotEncoder().setDropLast(false).setInputCol("jobIndex").setOutputCol("jobVec")
val encoded = encoder.transform(indexed)
//下面代码为新增代码
val maritalIndexer=new StringIndexer().setInputCol("marital").setOutputCol("maritalIndex")
//注意:此处所使用的数据是job列应用OneHotEncoder算法后产生的数据encoded
//这里不能使用原始数据selected_Data,因为原始数据中没有jobVec列。
val maritalIndexed=maritalIndexer.fit(encoded).transform(encoded)
val maritalEncoder=new OneHotEncoder().setDropLast(false).setInputCol("maritalIndex").setOutputCol("maritalVec")
val maritalEncoded=maritalEncoder.transform(maritalIndexed)
val defaultIndexer=new StringIndexer().setInputCol("default").setOutputCol("defaultIndex")
//注意:此处所使用的数据是对marital列应用OneHotEncoder算法后产生的数据maritalEncoded
val defaultIndexed=defaultIndexer.fit(maritalEncoded).transform(maritalEncoded)
val defaultEncoder=new OneHotEncoder().setDropLast(false).setInputCol("defaultIndex").setOutputCol("defaultVec")
val defaultEncoded=defaultEncoder.transform(defaultIndexed)
val housingIndexer=new StringIndexer().setInputCol("housing").setOutputCol("housingIndex")
//注意:此处所使用的数据是对default列应用OneHotEncoder算法后产生的数据defaultEncoded
val housingIndexed=housingIndexer.fit(defaultEncoded).transform(defaultEncoded)
val housingEncoder=new OneHotEncoder().setDropLast(false).setInputCol("housingIndex").setOutputCol("housingVec")
val housingEncoded=housingEncoder.transform(housingIndexed)
val poutcomeIndexer=new StringIndexer().setInputCol("poutcome").setOutputCol("poutcomeIndex")
//注意:此处所使用的数据是对housing列应用OneHotEncoder算法后产生的数据housingEncoded
val poutcomeIndexed=poutcomeIndexer.fit(housingEncoded).transform(housingEncoded)
val poutcomeEncoder=new OneHotEncoder().setDropLast(false).setInputCol("poutcomeIndex").setOutputCol("poutcomeVec")
val poutcomeEncoded=poutcomeEncoder.transform(poutcomeIndexed)
val loanIndexer=new StringIndexer().setInputCol("loan").setOutputCol("loanIndex")
//注意:此处所使用的数据是对poutcome列应用OneHotEncoder算法后产生的数据poutcomeEncoded
val loanIndexed=loanIndexer.fit(poutcomeEncoded).transform(poutcomeEncoded)
val loanEncoder=new OneHotEncoder().setDropLast(false).setInputCol("loanIndex").setOutputCol("loanVec")
val loanEncoded=loanEncoder.transform(loanIndexed)
loanEncoded.show()
loanEncoded.printSchema()
上述代码对多个分类字段(marital、default、housing、poutcome、loan)使用了 StringIndex 和 OneHotEncoder 算法,代码执行流程可以用下图表示:
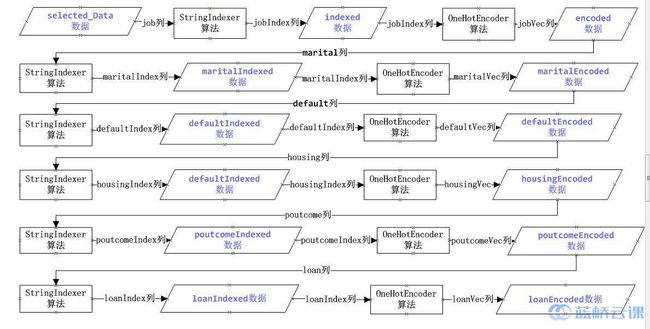
上图初看较复杂,其实很简单!我们对数据进行特征转换,实质上是对数据中的某列进行特征转换,每次应用特征转换算法都会有一个输入列和一个输出列。上图中,菱形表示应用算法后,增加了输出列的数据,正方形表示算法,正方形前后的箭头表示输入列和输出列。转换的具体步骤如下:
- selected_Data 是我们选择了11列后的数据,首先对selected_Data数据中的job数据进行StringIndexer转换,算法输出一个新列:jobIndex,对应代码如下:
val indexer = new StringIndexer().setInputCol("job").setOutputCol("jobIndex")
val indexed = indexer.fit(selected_Data).transform(selected_Data)
- indexed 变量中的数据是包含了新列 jobIndex 的数据,原始列 job 的类型为字符型,新列 jobIndex 的类型为对应的数值型,将此列输入到 OneHotEncoder 算法中,进行 OneHot 编码,输出一个新列 jobVec,对应代码如下:
val encoder = new OneHotEncoder().setDropLast(false).setInputCol("jobIndex").setOutputCol("jobVec")
val encoded = encoder.transform(indexed)
- encoded 变量中的数据是包含了新列 jobVec 的数据,接着用 encoded 数据中的 marital 列作为 StringIndexer 算法的输入列,算法输出一个新列 maritalIndex,对应代码如下:
val maritalIndexer=new StringIndexer().setInputCol("marital").setOutputCol("maritalIndex")
val maritalIndexed=maritalIndexer.fit(encoded).transform(encoded)
- 接着对maritalIndexed变量中的maritalIndex列进行OneHotEncoder编码,其过程与job列一样,以此类推......
- 最后对loan列进行特征转换,转换结果为loanEncoded数据,将loanEncoded数据中的内容和schema输出。
3.4.5 再次运行程序,查看输出结果:
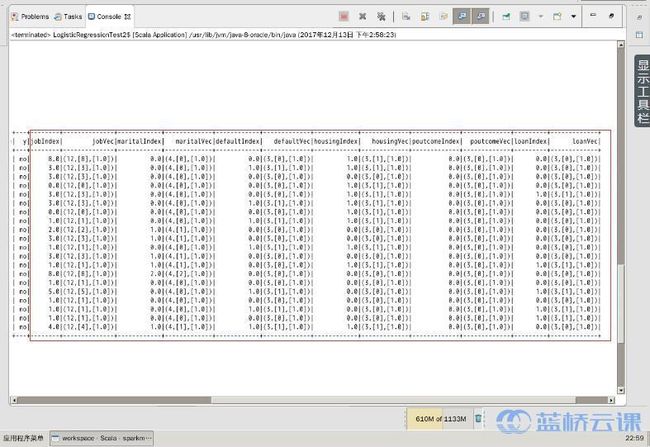
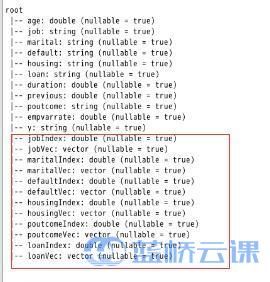
可以看出,marital、default、housing、poutcome、loan 这5个分类的字段增加情况和 job 字段一样,都增加了对应稀疏向量字段。
到目前为止,除了目标变量y,所有的字符型列都完成了 OneHot 编码,在对目标变量y进行数据转换后,就可以基于编码后的向量字段应用逻辑回归算法进行预测了。 在应用逻辑回归算法之前,我们使用 pipeline 技术对算法和数据进行流水线式组装,然后再应用逻辑回归算法。
3.5 建立逻辑回归模型进行预测
3.5.1 在上一步骤main方法中已有代码后面,继续编写代码:
//实例化一个向量组装器对象,
//将向量类型字段("jobVec","maritalVec", "defaultVec","housingVec","poutcomeVec","loanVec")
//和数值型字段("age","duration","previous","empvarrate")
//形成一个新的字段:features,其中包含了所有的特征值
val vectorAssembler = new VectorAssembler()
.setInputCols(Array("jobVec","maritalVec", "defaultVec","housingVec","poutcomeVec","loanVec","age","duration","previous","empvarrate"))
.setOutputCol("features")
//对目标变量进行StringIndexer特征转换,输出新列:label
val indexerY = new StringIndexer().setInputCol("y").setOutputCol("label")
//将特征算法按顺序进行合并,形成一个算法数组
val transformers=Array(indexer,
encoder,
maritalIndexer,
maritalEncoder,
defaultIndexer,
defaultEncoder,
housingIndexer,
housingEncoder,
poutcomeIndexer,
poutcomeEncoder,
loanIndexer,
loanEncoder,
vectorAssembler,
indexerY);
//将原始数据selected_Data进行8-2分,80%用于训练数据。20%用于测试数据,评估训练模型的精确度。
val splits = selected_Data.randomSplit(Array(0.8,0.2))
val training = splits(0).cache()
val test = splits(1).cache()
//实例化逻辑回归算法
val lr = new LogisticRegression()
//将算法数组和逻辑回归算法合并,传入pipeline对象的stages中,然后作用于训练数据,训练模型
var model = new Pipeline().setStages(transformers :+ lr).fit(training)
//将上一步的训练模型作用于测试数据,返回测试结果
var result = model.transform(test)
//显示测试结果集中的真实值、预测值、原始值、百分比字段
result.select("label", "prediction","rawPrediction","probability").show(10,false)
//创建二分类算法评估器,对测试结果进行评估
val evaluator = new BinaryClassificationEvaluator()
var aucTraining = evaluator.evaluate(result)
println("aucTraining = "+aucTraining)
3.5.2 再次运行程序,查看运行结果:
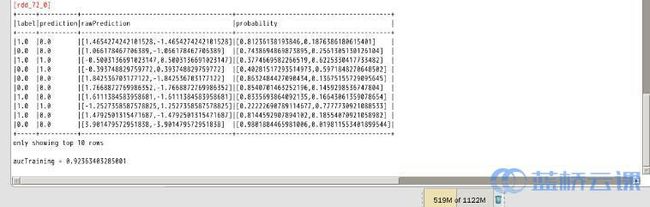
从运行结果中可以看出,输出的测试结果前10条数据,其中 probability 列值是[0,1]对应的发生概率,如果某个分类值出现的概率大于0.5,那么预测值 prediction 就是对应的那个分类值。 对20%测试集的预测精确度为:0.92363403285001,即:精确度为 90% 以上,说明我们训练的模型,预测的准确度还是很高的。注意:每次运行的精确度不会完全一样,有稍微的差别。
截至此操作完整代码如下:
package com.shiyanlou.algorithm
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types.DoubleType
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.feature.OneHotEncoder
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator
import org.apache.spark.ml.feature.VectorAssembler
object LogisticRegressionTest2 {
def main(args: Array[String]): Unit = {
val spark=SparkSession.builder().appName("Logistic_Prediction").master("local").getOrCreate()
spark.sparkContext.setLogLevel("WARN")
import spark.implicits._
val bank_Marketing_Data=spark.read
.option("header", true)
.option("inferSchema", "true")
.csv("/opt/train/bank_marketing_data.csv")
bank_Marketing_Data.show(5)
val selected_Data=bank_Marketing_Data.select("age",
"job",
"marital",
"default",
"housing",
"loan",
"duration",
"previous",
"poutcome",
"empvarrate",
"y")
.withColumn("age", bank_Marketing_Data("age").cast(DoubleType))
.withColumn("duration", bank_Marketing_Data("duration").cast(DoubleType))
.withColumn("previous", bank_Marketing_Data("previous").cast(DoubleType))
val indexer = new StringIndexer().setInputCol("job").setOutputCol("jobIndex")
val indexed = indexer.fit(selected_Data).transform(selected_Data)
indexed.printSchema()
indexed.show
val encoder = new OneHotEncoder().setDropLast(false).setInputCol("jobIndex").setOutputCol("jobVec")
val encoded = encoder.transform(indexed)
encoded.show()
encoded.printSchema()
val maritalIndexer=new StringIndexer().setInputCol("marital").setOutputCol("maritalIndex")
val maritalIndexed=maritalIndexer.fit(encoded).transform(encoded)
val maritalEncoder=new OneHotEncoder().setDropLast(false).setInputCol("maritalIndex").setOutputCol("maritalVec")
val maritalEncoded=maritalEncoder.transform(maritalIndexed)
val defaultIndexer=new StringIndexer().setInputCol("default").setOutputCol("defaultIndex")
val defaultIndexed=defaultIndexer.fit(maritalEncoded).transform(maritalEncoded)
val defaultEncoder=new OneHotEncoder().setDropLast(false).setInputCol("defaultIndex").setOutputCol("defaultVec")
val defaultEncoded=defaultEncoder.transform(defaultIndexed)
val housingIndexer=new StringIndexer().setInputCol("housing").setOutputCol("housingIndex")
val housingIndexed=housingIndexer.fit(defaultEncoded).transform(defaultEncoded)
val housingEncoder=new OneHotEncoder().setDropLast(false).setInputCol("housingIndex").setOutputCol("housingVec")
val housingEncoded=housingEncoder.transform(housingIndexed)
val poutcomeIndexer=new StringIndexer().setInputCol("poutcome").setOutputCol("poutcomeIndex")
val poutcomeIndexed=poutcomeIndexer.fit(housingEncoded).transform(housingEncoded)
val poutcomeEncoder=new OneHotEncoder().setDropLast(false).setInputCol("poutcomeIndex").setOutputCol("poutcomeVec")
val poutcomeEncoded=poutcomeEncoder.transform(poutcomeIndexed)
val loanIndexer=new StringIndexer().setInputCol("loan").setOutputCol("loanIndex")
val loanIndexed=loanIndexer.fit(poutcomeEncoded).transform(poutcomeEncoded)
val loanEncoder=new OneHotEncoder().setDropLast(false).setInputCol("loanIndex").setOutputCol("loanVec")
val loanEncoded=loanEncoder.transform(loanIndexed)
loanEncoded.show()
loanEncoded.printSchema()
val vectorAssembler = new VectorAssembler()
.setInputCols(Array("jobVec","maritalVec", "defaultVec","housingVec","poutcomeVec","loanVec","age","duration","previous","empvarrate"))
.setOutputCol("features")
val indexerY = new StringIndexer().setInputCol("y").setOutputCol("label")
val transformers=Array(indexer,
encoder,
maritalIndexer,
maritalEncoder,
defaultIndexer,
defaultEncoder,
housingIndexer,
housingEncoder,
poutcomeIndexer,
poutcomeEncoder,
loanIndexer,
loanEncoder,
vectorAssembler,
indexerY);
val splits = selected_Data.randomSplit(Array(0.8,0.2))
val training = splits(0).cache()
val test = splits(1).cache()
val lr = new LogisticRegression()
var model = new Pipeline().setStages(transformers :+ lr).fit(training)
var result = model.transform(test)
result.select("label", "prediction","rawPrediction","probability").show(10,false)
val evaluator = new BinaryClassificationEvaluator()
var aucTraining = evaluator.evaluate(result)
println("aucTraining = "+aucTraining)
}
}
五、总结
本次实验,采用了项目中使用机器学习算法的基本步骤,演示了对银行营销数据的分析预测。主要包括如下步骤:
- 获取银行营销数据
- 分析营销数据结构
- 概要分析数据字段内容
- 对数据使用特征工程
- 建立逻辑回归模型并预测
除了上述步骤,有时根据数据情况和具体场景,需要对数据进行清洗。数据清洗的方式有删除法、均值法等,后续实验中会详细介绍。
需要注意的是:在具体项目中,如果算法工程师拿到的数据已经是数值型内容,或者已经进行了特征化,那么此时,可以省略相应步骤,直接建立相应的算法模型,进行预测。
https://www.shiyanlou.com/courses/1003/labs/4242/document