基于Spark的银行直销电话数据探索性数据分析
基于Spark的银行直销电话数据探索性数据分析
- 一、业务场景
- 二、数据集说明
- 三、操作步骤
-
- 阶段一、启动HDFS、Spark集群服务和zeppelin服务器
- 阶段二、准备案例中用到的数据集
- 阶段三、对数据集进行探索和分析
- 阶段四、自行练习
未经许可,禁止以任何形式转载,若要引用,请标注链接地址
全文共计7333字,阅读大概需要3分钟
案例:
一、业务场景
某银行机构现有银行的直销活动(电话直销)相关数据的数据集,现希望大数据分析团队使用Spark技术对这些数据进行探索性数据分析,清理错误数据,处理缺失数据,并对数据进行规范化,以期获得有价值的信息。
二、数据集说明
本案例用到的数据集说明如下:
数据集文件:/data/dataset/batch/bank-additional-full.csv
带有缺失值的数据集文件:/data/dataset/batch/bank-additional-full-with-missing.csv
数据集包含41,188个记录和20个输入字段,按日期排序(从2008年5月到2010年11月)
三、操作步骤
阶段一、启动HDFS、Spark集群服务和zeppelin服务器
1、启动HDFS集群
在Linux终端窗口下,输入以下命令,启动HDFS集群:
1. $ start-dfs.sh
2、启动Spark集群
在Linux终端窗口下,输入以下命令,启动Spark集群:
1. $ cd /opt/spark
2. $ ./sbin/start-all.sh
3、启动zeppelin服务器
在Linux终端窗口下,输入以下命令,启动zeppelin服务器:
1. $ zeppelin-daemon.sh start
4、验证以上进程是否已启动
在Linux终端窗口下,输入以下命令,查看启动的服务进程:
1. $ jps
如果显示以下6个进程,则说明各项服务启动正常,可以继续下一阶段。
1. 2288 NameNode
2. 2402 DataNode
3. 2603 SecondaryNameNode
4. 2769 Master
5. 2891 Worker
6. 2984 ZeppelinServer
阶段二、准备案例中用到的数据集
1、将本案例要用到的数据集上传到HDFS文件系统的/data/dataset/目录下。在Linux终端窗口下,输入以下命令:
1. $ hdfs dfs -mkdir -p /data/dataset
2. $ hdfs dfs -put /data/dataset/batch/bank-additional-full.csv /data/dataset/
3. $ hdfs dfs -put /data/dataset/batch/bank-additional-full-with-missing.csv /data/dataset
2、在Linux终端窗口下,输入以下命令,查看HDFS上是否已经上传了该数据集:
1. $ hdfs dfs -ls /data/dataset/
这时应该看到数据集文件bank-additional-full.csv已经上传到了HDFS的/data/dataset/目录下。
阶段三、对数据集进行探索和分析
1、新建一个zeppelin notebook文件,并命名为bank_project。
2、导入代码中要用到的包。在notebook单元格中,输入以下代码:
1. // 导入包
2. import org.apache.spark.sql.types._
3. import spark.implicits._
同时按下【Shift+Enter】键,执行以上代码。
3、定义一个Schema,来表示电话直销数据。在notebook单元格中,输入以下代码:
1. val age = StructField("age", IntegerType)
2. val job = StructField("job", StringType)
3. val marital = StructField("marital", StringType)
4.
5. val edu = StructField("edu", StringType)
6. val credit_default = StructField("credit_default", StringType)
7. val housing = StructField("housing", StringType)
8.
9. val loan = StructField("loan", StringType)
10. val contact = StructField("contact", StringType)
11. val month = StructField("month", StringType)
12.
13. val day = StructField("day", StringType)
14. val dur = StructField("dur", DoubleType)
15. val campaign = StructField("campaign", DoubleType)
16.
17. val pdays = StructField("pdays", DoubleType)
18. val prev = StructField("prev", DoubleType)
19. val pout = StructField("pout", StringType)
20.
21. val emp_var_rate = StructField("emp_var_rate", DoubleType)
22. val cons_price_idx = StructField("cons_price_idx", DoubleType)
23. val cons_conf_idx = StructField("cons_conf_idx", DoubleType)
24.
25. val euribor3m = StructField("euribor3m", DoubleType)
26. val nr_employed = StructField("nr_employed", DoubleType)
27. val deposit = StructField("deposit", StringType)
28.
29. val fields = Array(age, job, marital, edu, credit_default, housing, loan, contact, month, day, dur, campaign, pdays, prev, pout, emp_var_rate, cons_price_idx, cons_conf_idx, euribor3m, nr_employed, deposit)
30.
31. val schema = StructType(fields)
同时按下【Shift+Enter】键,执行以上代码。
4、加载csv文件,创建DataFrame。在notebook单元格中,输入以下代码:
1. val filePath = "hdfs://localhost:9000/data/dataset/bank-additional-full.csv"
2. val df = spark.read
3. .schema(schema)
4. .option("sep", ";")
5. .option("header", true)
6. .csv(filePath)
7.
8. df.count()
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:
filePath: String = /data/spark_demo/bank-additional-full.csv
df: org.apache.spark.sql.DataFrame = [age: int, job: string … 19 more fields]
res12: Long = 41188
由以上输出内容可以看出,原始的数据集共有21个字段,41188条电话呼叫记录。
5、为输入记录定义一个case class类Call,然后创建一个强类型数据集。在notebook单元格中,输入以下代码:
1. import spark.implicits._
2.
3. case class Call(age: Int,
4. job: String,
5. marital: String,
6. edu: String,
7. credit_default: String,
8. housing: String,
9. loan: String,
10. contact: String,
11. month: String,
12. day: String,
13. dur: Double,
14. campaign: Double,
15. pdays: Double,
16. prev: Double,
17. pout: String,
18. emp_var_rate: Double,
19. cons_price_idx: Double,
20. cons_conf_idx: Double,
21. euribor3m: Double,
22. nr_employed: Double,
23. deposit: String)
24. val ds = df.as[Call]
25. ds.printSchema()
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:

6、识别缺失值。在notebook单元格中,输入以下代码:
1. // 分析样本数据集中缺少数据字段的记录数量
2. val filePathWithMissing = "hdfs://localhost:9000/data/dataset/bank-additional-full-with-missing.csv"
3. val dfMissing = spark.read.schema(schema).
4. option("sep", ";").
5. option("header", true).
6. csv(filePathWithMissing)
7. val dsMissing = dfMissing.as[Call]
8.
9. dsMissing.groupBy("marital").count().show()
10. dsMissing.groupBy("job").count().show()
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:

由以上输出内容可以看出,有80人的婚姻状况信息缺失,有330人的职业信息缺失。
7、计算一些基本统计信息,以提高对数据的理解。在notebook单元格中,输入以下代码:
1. // 获取子集
2. val dsSubset = ds.select($"age", $"dur", $"campaign", $"prev", $"deposit")
3. dsSubset.show(5)
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:

在notebook单元格中,输入以下代码:
1. import spark.implicits._
2. // 转换为Dataset并对其进行描述
3. case class CallStats(age: Int, dur: Double, campaign: Double, prev: Double, deposit: String)
4.
5. val dsCallStats = dsSubset.as[CallStats]
6. dsCallStats.cache() // 缓存子集
7. dsSubset.describe().show()
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:
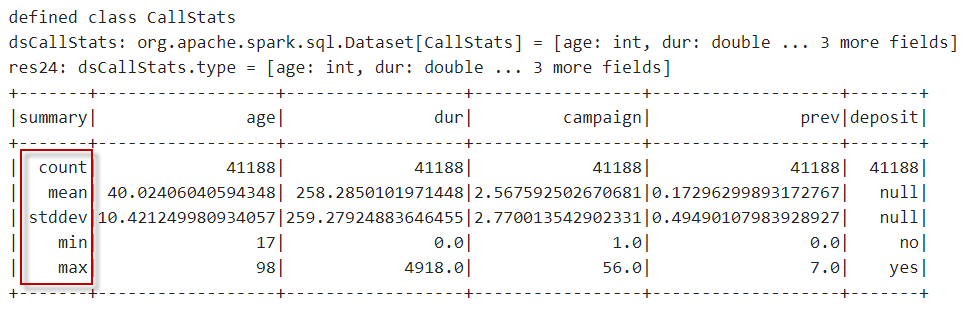
8、分析”age”字段和”dur”字段之间的相关性。在notebook单元格中,输入以下代码:
1. // 协方差给出了这两个变量之间的相关方向
2. val cov = dsSubset.stat.cov("age","dur")
3. println("age to call duration : Covariance = %.4f".format(cov))
4.
5. // 相关性给出了这两个变量之间关系强度的大小
6. val corr = dsSubset.stat.corr("age","dur")
7. println("age to call duration : Correlation = %.4f".format(corr))
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:
cov: Double = -2.3391469421267863
age to call duration : Covariance = -2.3391
corr: Double = -8.657050101409879E-4
age to call duration : Correlation = -0.0009
由以上输出内容可以看出,年龄与最后一次接触时间的协方差方向相反,即年龄越大,接触时间越短。
9、我们可以在两个变量之间创建交叉表格或交叉标记,以评估它们之间的相互关系。在notebook单元格中,输入以下代码:
1. ds.stat.crosstab("age", "marital").orderBy("age_marital").show(10)
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:

从表格中,我们了解到,在一个给定的年龄,不同婚姻状况的个人的分手总数。
10、提取数据列中最常出现的项。在这里,我们选择教育程度作为列,并指定0.3的支持级别,也就是说,我们想要找到的教育程度在DataFrame中发生的频率大于0.3(至少观察到的30%的时间)。在notebook单元格中,输入以下代码:
1. val freq = df.stat.freqItems(Seq("edu"), 0.3)
2. freq.show(false)
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:

由以上输出内容可以看出,最常出现的受教育程度是”high.school”、”university.degree”和”professional.course”。
11、计算DataFrame中数字列的近似分位数。这里我们同样对age列计算,指定的分位数概率为0.25、0.5和0.75(0是最小值,1是最大值,0.5是中值median)。在notebook单元格中,输入以下代码:
1. val quantiles = df.stat.approxQuantile("age", Array(0.25,0.5,0.75),0.0)
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:
quantiles: Array[Double] = Array(32.0, 38.0, 47.0)
由以上输出内容可以看出,第一个四分位数(第 25 个百分点值)是32.0,中分位数(第 50 个百分点值)是38.0,第三个四分位数(第 75 个百分点值)是47.0。
12、探索性数据可视化。首先注册一个临时视图。在notebook单元格中,输入以下代码:
1. df.createOrReplaceTempView("calls")
同时按下【Shift+Enter】键,执行以上代码。
13、统计不同年龄段的客户人数。在notebook单元格中,输入以下代码:
1. %sql
2. select age,count(1) from calls group by age order by age
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:

由以上输出内容可以看出,36岁的客户人数有1780人。
14、数据抽样。我们可以使用sampleBy创建无需替换(without replacement)的分层样本。我们可以指定要在样本中选择的每个值的百分比的分数。在notebook单元格中,输入以下代码:
1. // 样本的大小和每种类型的记录数量如下:
2. import scala.collection.immutable.Map
3.
4. val fractions = Map("unknown" -> .10, "divorced" -> .15, "married" -> 0.5, "single" -> .25)
5. val dsStratifiedSample = ds.stat.sampleBy("marital", fractions, 36L)
6.
7. dsStratifiedSample.count()
8. dsStratifiedSample.groupBy("marital").count().orderBy("marital").show()
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:
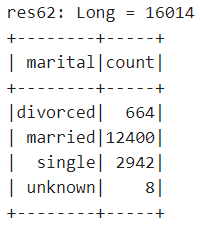
由以上输出内容可以看出,总抽样数为16014人,其中不同的婚姻状况抽样数按设置的因子抽取数量如图中所示。
15、创建数据透视表。在notebook单元格中,输入以下代码:
1. // 下面的例子以住房贷款为中心,并按婚姻状况进行统计:
2. val sourceDF = df.select($"job", $"marital", $"edu", $"housing", $"loan", $"contact", $"month", $"day", $"dur", $"campaign", $"pdays", $"prev", $"pout", $"deposit")
3. sourceDF.groupBy("marital").pivot("housing").agg(count("housing")).sort("marital").show()
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:

由以上输出内容可以看出,不同婚姻状况客户的住房贷款分布情况。
阶段四、自行练习
1、使用本案例的数据集,查询不同受教育程度的客户数量,并可视化呈现。
2、使用本案例的数据集,探索受教育程度和婚姻状况间是否有相关性,并尝试对结果进行分析说明。