使用Python抓取动态网站数据
微信公众号:运维开发故事,作者:素心
这里将会以一个例子展开探讨多线程在爬虫中的应用,所以不会过多的解释理论性的东西,并发详情点击连接
爬取某应用商店
当然,爬取之前请自行诊断是否遵循君子协议,遵守就爬不了数据
查看robots协议只需要在域名后缀上
rebots.txt即可例如:
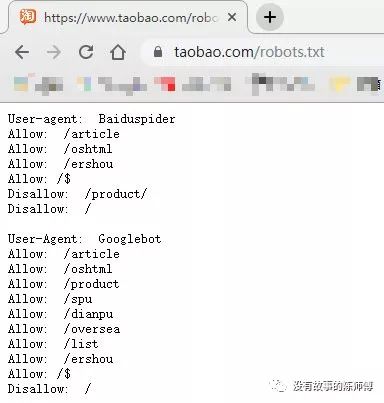
1. 目标
-
URL:
http://app.mi.com/category/15 -
获取“游戏”分类的所有APP名称、简介、下载链接
2. 分析
2.1 网页属性
首先,需要判断是不是动态加载
点击翻页,发现URL后边加上了#page=1,这也就是说,查询参数为1的时候为第二页,写一个小爬虫测试一下
import requests
url = "http://app.mi.com/category/15"headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36"}
html = requests.get(url=url, headers=headers).content.decode("utf-8")
print(html)
在输出的html中搜索“王者荣耀”,发现并没有什么问题,那么第二页呢?将上述代码中的url = "http://app.mi.com/category/15"改为url = "http://app.mi.com/category/15#page=1"
再次搜索第二页的内容”炉石传说”,发现并没有搜索出来,那么该网站可能是动态加载
-
抓包分析
打开chrome自带的窃听器,切换到network,点击翻页

可以看到该GET请求后缀很多参数
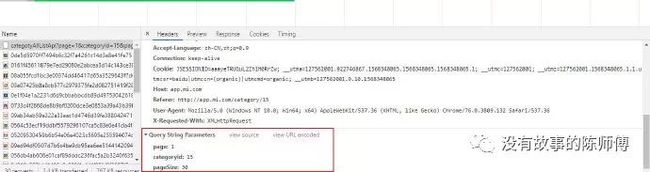
经过多次测试发现
-
page为页数,但是值需要减1才是真实的页数 -
categoryId为应用分类 -
pageSize尚不明确,所以将抓到包的URL打开看一下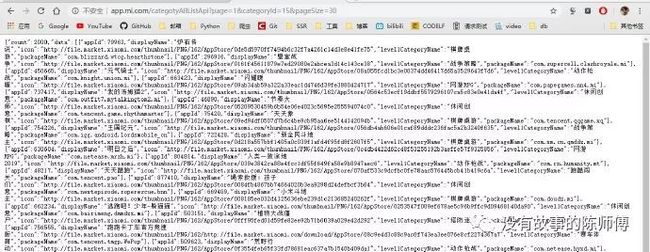
不难发现,
pageSize为每一页显示APP信息的个数,并且返回了一个json字串
2.2 分析json
复制一段json过来
{"count":2000, "data":
[
{"appId":108048, "displayName":"王者荣耀", "icon":"http://file.market.xiaomi.com/thumbnail/PNG/l62/AppStore/0eb7aa415046f4cb838cfe5b5d402a5efc34fbb25", "level1CategoryName":"网游RPG", "packageName":"com.tencent.tmgp.sgame"
},
{},
...
]
}
所有的信息都不知道是干啥的,暂时保存
2.3 二级页面
点击”王者荣耀”,跳转到APP详情,看下URL是什么样子
http://app.mi.com/details?id=com.tencent.tmgp.sgame
然后这里会惊奇的发现,id的查询参数和上边的packageName的值一样,所以详情页就需要拼接URL
2.4 获取信息
-
APP名称
深圳市腾讯计算机系统有限公司
王者荣耀
...... -
APP简介
新版特性
-
APP下载地址
2.4 确认技术
由以上分析可以得出,使用lxml提取数据将会是不错的选择,有关xpath使用请点击跳转
xpath语法如下:
-
名称:
//div[@class="intro-titles"]/h3/text() -
简介:
//p[@class="pslide"][1]/text() -
下载链接:
//a[@class="download"]/@href
3. 代码实现
import requestsfrom lxml import etreeclass MiSpider(object):
def __init__(self):
self.bsase_url = "http://app.mi.com/categotyAllListApi?page={}&categoryId=15&pageSize=30" # 一级页面的URL地址
self.headers = {"User-Agent":"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"} # 获取响应对象
def get_page(self, url):
reponse = requests.get(url=url, headers=self.headers) return reponse # 解析一级页面,即json解析,得到APP详情页的链接
def parse_page(self, url):
html = self.get_page(url).json() # two_url_list:[{"appId":"108048","dispayName":"..",...},{},{},...]
two_url_list = html["data"] for two_url in two_url_list:
two_url = "http://app.mi.com/details?id={}".format(two_url["packageName"]) # 拼接app详情链接
self.parse_info(two_url) # 解析二级页面,得到名称、简介、下载链接
def parse_info(self, two_url):
html = self.get_page(two_url).content.decode("utf-8")
parse_html = etree.HTML(html) # 获取目标信息
app_name = parse_html.xpath('//div[@class="intro-titles"]/h3/text()')[0].strip()
app_info = parse_html.xpath('//p[@class="pslide"][1]/text()')[0].strip()
app_url = "http://app.mi.com" + parse_html.xpath('//a[@class="download"]/@href')[0].strip()
print(app_name, app_url, app_info) # 主函数
def main(self):
for page in range(67):
url = self.bsase_url.format(page)
self.parse_page(url)if __name__ == "__main__":
spider = MiSpider()
spider.main()
接下来将数据存储起来,存储的方式有很多csv、MySQL、MongoDB
数据存储
这里采用MySQL数据库将其存入
建表SQL
/*
Navicat MySQL Data Transfer
Source Server : xxx
Source Server Type : MySQL
Source Server Version : 50727
Source Host : MySQL_ip:3306
Source Schema : MIAPP
Target Server Type : MySQL
Target Server Version : 50727
File Encoding : 65001
Date: 13/09/2019 14:33:38
*/
CREATE DATABASE MiApp CHARSET=UTF8;
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for app
-- ----------------------------
DROP TABLE IF EXISTS `app`;
CREATE TABLE `app` (
`name` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT 'APP名称',
`url` text CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT 'APP下载链接',
`info` longtext CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL COMMENT 'APP简介'
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
1. pymysql
简单介绍一下pymysql 的使用,该模块为第三方,需要用pip安装,安装方法不再赘述。
1.1 内置方法
pymysql方法
connect()连接数据库,参数为连接信息(host, port, user, password, charset)
pymysql对象方法
-
cursor()游标,用来定位数据库 -
cursor.execute(sql)执行sql语句 -
db.commit()提交事务 -
cursor.close()关闭游标 -
db.close()关闭连接
1.2 注意事项
只要涉及数据的修改操作,必须提交事务到数据库
查询数据库需要使用fet方法获取查询结果
1.3 详情
更多详情可以参考pymsql
2. 存储
创建配置文件(config.py)
'''
数据库连接信息
'''HOST = "xxx.xxx.xxx.xxx"PORT = 3306USER = "xxxxx"PASSWORD = "xxxxxxx"DB = "MIAPP"CHARSET = "utf8mb4"
表结构
mysql> desc MIAPP.app;
+-------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+-------+
| name | varchar(20) | YES | | NULL | |
| url | varchar(255) | YES | | NULL | |
| info | text | YES | | NULL | |
+-------+--------------+------+-----+---------+-------+3 rows in set (0.00 sec)
SQL语句
insert into app values(name,url,info);
完整代码
import requestsfrom lxml import etreeimport pymysqlfrom config import *class MiSpider(object):
def __init__(self):
self.bsase_url = "http://app.mi.com/categotyAllListApi?page={}&categoryId=15&pageSize=30" # 一级页面的URL地址
self.headers = {"User-Agent":"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}
self.db = pymysql.connect(host=HOST, port=PORT, user=USER, password=PASSWORD, database=DB, charset=CHARSET) # 连接数据库
self.cursor = self.db.cursor() # 创建游标
self.i = 0 # 用来计数,无其他作用
# 获取响应对象
def get_page(self, url):
reponse = requests.get(url=url, headers=self.headers) return reponse # 解析一级页面,即json解析,得到APP详情页的链接
def parse_page(self, url):
html = self.get_page(url).json() # two_url_list:[{"appId":"108048","dispayName":"..",...},{},{},...]
two_url_list = html["data"] for two_url in two_url_list:
two_url = "http://app.mi.com/details?id={}".format(two_url["packageName"]) # 拼接app详情链接
self.parse_info(two_url) # 解析二级页面,得到名称、简介、下载链接
def parse_info(self, two_url):
html = self.get_page(two_url).content.decode("utf-8")
parse_html = etree.HTML(html) # 获取目标信息
app_name = parse_html.xpath('//div[@class="intro-titles"]/h3/text()')[0].strip()
app_info = parse_html.xpath('//p[@class="pslide"][1]/text()')[0].strip()
app_url = "http://app.mi.com" + parse_html.xpath('//a[@class="download"]/@href')[0].strip()
ins = "insert into app(name,url,info) values (%s,%s,%s)" # 需要执行的SQL语句
self.cursor.execute(ins, [app_name, app_url, app_info])
self.db.commit()
self.i += 1
print("第{}APP {}成功写入数据库".format(self.i, app_name)) # 主函数
def main(self):
for page in range(67):
url = self.bsase_url.format(page)
self.parse_page(url) # 断开数据库
self.cursor.close()
self.db.close()
print("执行结束,共{}个APP成功写入".format(self.i))if __name__ == "__main__":
spider = MiSpider()
spider.main()

多线程
爬取上述信息似乎有点慢,如果数据多的话太耗时,而且计算机资源也得不到充分的利用
这就需要用多线程的理念,关于多进程和多线程的概念网上比比皆是,只需要明白一点
进程可以包含很多个线程,进程死掉,线程不复存在
打个比方,假设有一列火车,把这列火车理解成进程的话,那么每节车厢就是线程,正是这许许多多的线程才共同组成了进程
python中有多线程的概念
假设现在有两个运算:
n += 1n -= 1
在python内部实际上这样运算的
x = n
x = n + 1n = x
x = n
x = n + 1n = x
线程有一个特性,就是会争夺计算机资源,如果一个线程在刚刚计算了x = n这时候另一个线程n = x运行了,那么这样下来全就乱了, 也就是说n加上一千个1再减去一千个1结果不一定为1,这时就考虑线程加锁问题了。
每个线程在运行的时候争抢共享数据,如果线程A正在操作一块数据,这时B线程也要操作该数据,届时就有可能造成数据紊乱,从而影响整个程序的运行。
所以Python有一个机制,在一个线程工作的时候,它会把整个解释器锁掉,导致其他的线程无法访问任何资源,这把锁就叫做GIL全局解释器锁,正是因为有这把锁的存在,名义上的多线程实则变成了单线程,所以很多人称GIL是python鸡肋性的存在。
针对这一缺陷,很多的标准库和第三方模块或者库都是基于这种缺陷开发,进而使得Python在改进多线程这一块变得尤为困难,那么在实际的开发中,遇到这种问题本人目前用四种解决方式:
用
multiprocessing代替Thead更换
cpython为jpython加同步锁
threading.Lock()消息队列
queue.Queue()
如果需要全面性的了解并发,请点击并发编程,在这里只简单介绍使用
1. 队列方法
# 导入模块from queue import Queue# 使用q = Queue()
q.put(url)
q.get() # 当队列为空时,阻塞q.empty() # 判断队列是否为空,True/False
2. 线程方法
# 导入模块from threading import Thread# 使用流程t = Thread(target=函数名) # 创建线程对象t.start() # 创建并启动线程t.join() # 阻塞等待回收线程# 创建多线程for i in range(5):
t = Thread(target=函数名)
t.start()
t.join()
3. 改写
理解以上内容就可以将原来的代码改写多线程,改写之前加上time来计时

多线程技术选用:
-
爬虫涉及IO操作较多,贸然改进程会造成计算机资源的浪费。
pass
-
更换
jpython简直没必要。pass
-
加锁可以实现,不过针对IO还是比较慢,因为操作文件的话,必须加锁。
pass
-
使用消息队列可有效的提高爬虫速率。
线程池的设计:
- 既然爬取的页面有67页,APP多达2010个,则考虑将URL入列
def url_in(self):
for page in range(67):
url = self.bsase_url.format(page)
self.q.put(page)
下边是完整代码
import requestsfrom lxml import etreeimport timefrom threading import Threadfrom queue import Queueimport jsonimport pymysqlfrom config import *class MiSpider(object):
def __init__(self):
self.url = "http://app.mi.com/categotyAllListApi?page={}&categoryId=15&pageSize=30"
self.headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3895.5 Safari/537.36"} # 创建URL队列
self.url_queue = Queue() # 把所有要爬取的页面放进队列
def url_in(self):
for page in range(67):
url = self.url.format(page) # 加入队列
self.url_queue.put(url) # 线程事件函数
def get_data(self):
while True: # 如果结果 为True,则队列为空了
if self.url_queue.empty(): break
# get地址,请求一级页面
url = self.url_queue.get()
html = requests.get(url=url, headers=self.headers).content.decode("utf-8")
html = json.loads(html) # 转换为json格式
# 解析数据
app_list = [] # 定义一个列表,用来保存所有的APP信息 [(name,url,info),(),(),...]
for app in html["data"]: # 应用链接
app_link = "http://app.mi.com/details?id=" + app["packageName"]
app_list.append(self.parse_two_page(app_link)) return app_list def parse_two_page(self, app_link):
html = requests.get(url=app_link, headers=self.headers).content.decode('utf-8')
parse_html = etree.HTML(html)
app_name = parse_html.xpath('//div[@class="intro-titles"]/h3/text()')[0].strip()
app_url = "http://app.mi.com" + parse_html.xpath('//div[@class="app-info-down"]/a/@href')[0].strip()
app_info = parse_html.xpath('//p[@class="pslide"][1]/text()')[0].strip()
info = (app_name, app_url, app_info)
print(app_name) return info # 主函数
def main(self):
# url入队列
self.url_in() # 创建多线程
t_list = [] for i in range(67):
t = Thread(target=self.get_data)
t_list.append(t)
t.start() for i in t_list:
i.join()
db = pymysql.connect(host=HOST, user=USER, password=PASSWORD, database=DB, charset=CHARSET)
cursor = db.cursor()
ins = 'insert into app values (%s, %s, %s)'
app_list = self.get_data()
print("正在写入数据库")
cursor.executemany(ins, app_list)
db.commit()
cursor.close()
db.close()if __name__ == '__main__':
start = time.time()
spider = MiSpider()
spider.main()
end = time.time()
print("执行时间:%.2f"% (end - start))
当然这里的设计理念是将URL纳入队列之中,还可以将解析以及保存都写进线程,以提高程序的执行效率。
更多爬虫技术点击访问
欢迎各位一起交流
