随机森林算法及贝叶斯优化调参Python实践
1. 随机森林算法
1.1. 集成模型简介
集成学习模型使用一系列弱学习器(也称为基础模型或基模型)进行学习,并将各个弱学习器的结果进行整合,从而获得比单个学习器更好的学习效果。
集成学习模型的常见算法有聚合法算法(Bagging)、提升算法(Boosting)和堆叠法(Stacking)
Bagging算法的典型机器学习模型为随机森林模型,而Boosting算法的典型机器学习模型则为AdaBoost、GBDT、XGBoost和LightGBM模型。
1.2. Bagging算法简介
Bagging算法的原理类似投票,每个弱学习器都有一票,最终根据所有弱学习器的投票,按照“少数服从多数”的原则产生最终的预测结果,如下图所示。

假设原始数据共有10000条,从中随机有放回地抽取10000次数据构成一个新的训练集(因为是随机有放回抽样,所以可能出现某一条数据多次被抽中,也有可能某一条数据一次也没有被抽中),每次使用一个训练集训练一个弱学习器。这样有放回地随机抽取n次后,训练结束时就能获得由不同的训练集训练出的n个弱学习器,根据这n个弱学习器的预测结果,按照“少数服从多数”的原则,获得一个更加准确、合理的最终预测结果。
具体来说,在分类问题中是用n个弱学习器投票的方式获取最终结果,在回归问题中则是取n个弱学习器的平均值作为最终结果。

1.3. 随机森林算法及实践
在机器学习中,随机森林(Random forest)是一种集成机器学习方法,是一个包含多个决策树的分类器,它利用随机重采样技术bootstrap和节点随机分裂技术构建多棵决策树,通过投票得到最终分类结果。
forest_model = joblib.load(DB_info.ModelRF_FileName2)
dtest = self.forecast_df[self.feature].copy()
dtest = self._feature_StandardScaler(dtest, True)
x = dtest
y = forest_model.predict_proba(x)
yprob = np.argmax(y, axis=1)
# 取预测结果标识
y_pred = [round(value) for value in yprob]
2. 模型优化调参
2.1. 人工调参
手动调参需要结合数据情况及算法的理解,优化调参的优先顺序及参数的经验值。
不同模型手动调参思路会有差异,如随机森林是一种bagging集成的方法,参数主要有n_estimators(子树的数量)、max_depth(树的最大生长深度)、max_leaf_nodes(最大叶节点数)等。(此外其他参数不展开说明)
对于n_estimators:通常越大效果越好。参数越大,则参与决策的子树越多,可以消除子树间的随机误差且增加预测的准度,以此降低方差与偏差。
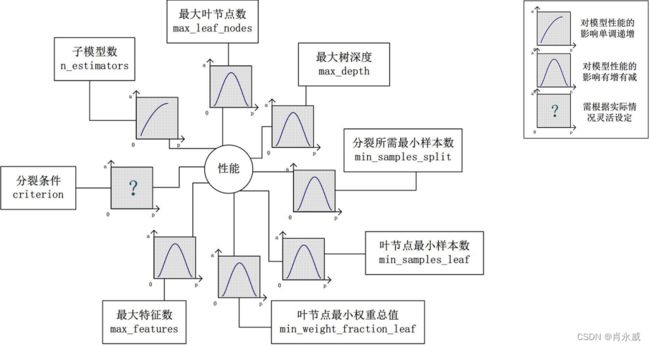
对于max_depth或max_leaf_nodes:通常对效果是先增后减的。取值越大则子树复杂度越高,偏差越低但方差越大。
2.2. 贝叶斯优化调参
参数优化基本思想是基于数据使用贝叶斯定理估计目标函数的后验分布,然后再根据分布选择下一个采样的超参数组合。它充分利用了前一个采样点的信息,其优化的工作方式是通过对目标函数形状的学习,并找到使结果向全局最大提升的参数。
假设一组超参数组合是 X = x 1 , x 2 , . . . x n X=x_1,x_2,...x_n X=x1,x2,...xn( x n x_n xn表示某一个超参数的值),不同超参数会得到不同效果,贝叶斯优化假设超参数与最后模型需要优化的损失函数存在一个函数关系。
高斯过程用贝叶斯优化中对目标函数建模,得到其后验分布。
而目前机器学习其实是一个可见输入与输出的黑盒子(black box),所以很难确直接定存在什么样的函数关系,所以我们需要将注意力转移到一个我们可以解决的函数上去,下面开始正式介绍贝叶斯优化。
贝叶斯优化的大体思路如下:
假设我们有一个函数 f : x → R f:x \rightarrow \mathbb{R} f:x→R,我们需要在 x ⊆ X x \subseteq X x⊆X内找到:
x ∗ = a r g m i n x ∈ X f ( x ) ( 2 ) x^*=\underset{x\in X}{argmin}f(x) \: \: \: \: \: (2) x∗=x∈Xargminf(x)(2)
注意上面的 x x x表示的是超参数。以随机森林分类任务为例, x x x可以是n_estimators:森林中树的数量,max_depth(最大的树深度)等超参数的设置。而为了避免全文符号太多,所以将输入数据隐去了。
贝叶斯优化把搜索的模型空间假设为高斯分布,利用高斯过程,按迭代的方式每次计算得到比当前最优参数期望提升的新的最优参数。例如详细算法,Sequential model-based optimization (SMBO) 是贝叶斯优化的最简形式。
目前可以做贝叶斯优化的第三方python包很多,常用的有BayesianOptimization、bayesopt、skopt等等。本文使用BayesianOptimization为例,利用随机森林的分类模型进行分类识别。
import numpy as np
import pandas as pd
from sklearn.metrics import accuracy_score, precision_score, confusion_matrix
from sklearn.metrics import recall_score
from sklearn.metrics import roc_auc_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from bayes_opt import BayesianOptimization
from sklearn.datasets import make_classification
x, y = make_classification(n_samples=1000, n_features=5, n_classes=2)
def RF_evaluate(n_estimators, min_samples_split, max_features, max_depth):
val = cross_val_score(
RandomForestClassifier(n_estimators=int(n_estimators),
min_samples_split=int(min_samples_split),
max_features=min(max_features, 0.999),
max_depth=int(max_depth),
random_state=2,
n_jobs=-1),
x, y, scoring='f1', cv=5
).mean()
return val
# 确定取值空间
pbounds = {'n_estimators': (50, 250), # 表示取值范围为10至250
'min_samples_split': (2, 25),
'max_features': (0.1, 0.999),
'max_depth': (5, 12)}
RF_bo = BayesianOptimization(
f=RF_evaluate, # 目标函数
pbounds=pbounds, # 取值空间
verbose=2, # verbose = 2 时打印全部,verbose = 1 时打印运行中发现的最大值,verbose = 0 将什么都不打印
random_state=1,
)
RF_bo.maximize(init_points=5, # 随机搜索的步数
n_iter=10, # 执行贝叶斯优化迭代次数
acq='ei')
print(RF_bo.max)
res = RF_bo.max
params_max = res['params']
2.3. 交叉验证
交叉验证是在机器学习建立模型和验证模型参数时常用的办法,一般被用于评估一个机器学习模型的表现。更多的情况下,我们也用交叉验证来进行模型选择(model selection)和优化调参。
K折验证交叉验证
总的来说,交叉验证既可以解决数据集的数据量不够大问题,也可以解决参数调优的问题。这块主要有三种方式:简单交叉验证(HoldOut检验)、k折交叉验证(k-fold交叉验证)、自助法。该文仅针对k折交叉验证做详解。
简单交叉验证
方法:将原始数据集随机划分成训练集和验证集两部分。比如说,将样本按照70%~30%的比例分成两部分,70%的样本用于训练模型;30%的样本用于模型验证。
缺点:
(1)数据都只被所用了一次,没有被充分利用
(2)在验证集上计算出来的最后的评估指标与原始分组有很大关系。
本文中使用cross_val_score执行交叉验证。
cross_val_score参数设置
sklearn.model_selection.cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv=’warn’, n_jobs=None, verbose=0, fit_params=None, pre_dispatch=‘2*n_jobs’, error_score=’raise-deprecating’)
参数:
estimator: 需要使用交叉验证的算法
X: 输入样本数据
y: 样本标签
groups: 将数据集分割为训练/测试集时使用的样本的组标签(一般用不到)
scoring: 交叉验证最重要的就是他的验证方式,选择不同的评价方法,会产生不同的评价结果。具体可用哪些评价指标,官方已给出详细解释,链接:https://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter
3. 实验
运行贝叶斯调优,结果如下:

则对于最优参数为:124 6 0.45147 5。
定义随机森林预测函数,接续上面代码。
from sklearn.model_selection import train_test_split
import joblib
def RandomForest(train_x,train_y,n_estimators,min_samples_split, max_features, max_depth):
# n_estimators:森林中树的数量,随机森林中树的数量默认100个树,精度递增显著,但并不是越多越好,加上verbose=True,显示进程使用信息
# n_jobs 整数 可选(默认=1) 适合和预测并行运行的作业数,如果为-1,则将作业数设置为核心数
forest_model = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth, min_samples_split =min_samples_split,
random_state=0, n_jobs=-1)
x_train,x_test,y_train,y_test = train_test_split(train_x,train_y,test_size=0.3)
forest_model.fit(x_train, y_train)
joblib.dump(forest_model, 'rf.jobl') # 存储
y_pred = forest_model.predict(x_test)
# 模型评估
# 混淆矩阵
print(confusion_matrix(y_test, y_pred))
print("准确率: %.3f" % accuracy_score(y_test, y_pred))
precision = precision_score(
y_test, y_pred, average='macro')
print('precision Score: %.2f%%' % (precision * 100.0))
recall = recall_score(y_test, y_pred, average='macro')
print('Recall Score: %.2f%%' % (recall * 100.0))
sklearn中模型保存和加载的模块: joblib
在机器学习的过程中,常用的就是sklearn中的库进行模型的训练,而对于训练好的模型,需要进行保存持久化的。对于这样的需求,可以使用sklearn中的joblib模块进行保存与加载。
3.1. 使用自定义参数
RandomForest(x,y,100,3, 0.2, 10)

准确率为0.947。
3.2. 使用贝叶斯优化参数
RandomForest(x,y,n_estimators,min_samples_split, max_features, max_depth)

准确率为0.953。
3.3. 结论
使用贝叶斯优化参数,将会找出较为合理的参数,实验预测结果精度提高了0.06。
参考:
[1]. QYiRen. 随机森林模型及案例(Python). CSDN博客. 2022.04
[2]. 呆萌的代Ma. sklearn模型使用贝叶斯优化调参(以随机森林为例). CSDN博客. 2021.07
[3]. 教育专家雷教授. 一文归纳Ai调参炼丹之法. 百度. 2021.07
[4]. macan_dct. 交叉验证以及scikit-learn中的cross_val_score详解. CSDN博客. 2019.06
[5]. 肖永威. 使用贝叶斯优化工具实践XGBoost回归模型调参. CSDN博客. 2021.11
[6]. https://scikit-learn.org/stable/modules/ensemble.html#forest