WWW 2021 | Radflow: 可进行数十万节点的多变量时序预测模型

©作者 | 方雨晨
学校 | 北京邮电大学
研究方向 | 时空数据挖掘
此文使用与 N-BEATS 一样的层级循环神经网络捕捉不同的时间趋势。然后将循环神经网络的输出做空间消息传递。在超大的网络时序数据集上取得 SOTA 的结果。

论文标题:
Radflow: A Recurrent, Aggregated, and Decomposable Model for Networks of Time Series
论文代码:
https://github.com/alasdairtran/radflow
论文链接:
https://arxiv.org/abs/2102.07289

Preliminary
给出时序图 ,且图中有 个节点,所以 ,且有 条边。每个节点 在时间 内的观测值为:
![]()
表示节点 在 时刻被观测到 个特征,当只有一个值时 。 表示节点 在时间 到时间 的子序列。
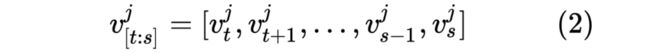
如果节点 与节点 在时间 有关联,就添加一条从 的边 。 表示节点 在 时刻的邻居集合,因为边集是会随时间边而变化的,所以图 是动态图。因此 时间内的邻接矩阵表示维 , 表示在时间 存在节点 到节点 的边。
现在定义时序预测问题,也即给出一段长为 的历史观测值预测未来 时刻的值。假设未来与历史的分割线为 ,那么关于节点 未来 到 时间的预测可以表示为:

也即使用过去 B 时刻的观测值与其邻居节点信息对未来做出预测。对未来邻居节点有两种设置,一种为 IMPUTATION,也即已经知道未来邻居节点的值,表示为:

当我们要填补序列中的缺失值或者解释节点受邻居影响时通常使用这种设置。另一种为 FORECAST,也即使用我们时间序列的观测值对所有节点的未来值做出预测,然后使用预测的邻居节点信息对当前节点做出预测。
在两者设置下,最后预测的输出都可以表示为:

表示节点 在 时刻 的预测值。

Challenge
作者指出目前时序预测还存在以下三个缺陷:
Expressiveness:目前的模型过于简单,没有考虑到多个时序变量之间的关系,N-BEATS 虽然对时间序列进行分解但是也没有对时序图进行建模。
Scale:本文的目标是对含有几十万个节点的时序图进行建模,不仅要考虑到时间序列内容与空间内容,更要考虑到时空内容的交互。T-GCN 模型虽然集成了 GNN 与 RNN,但是受限于其复杂度难以处理大规模数据集。
Dynamic:多个变量间的关系是随着时间变化而变化的。动态网络虽然已经是 GNN 的研究热点,但是却只被用在了链接预测与节点分类等任务,并没有被用于时间序列预测中。

Contribution
此文提出了一个基于分解原则的循环神经网络架构,并将循环神经网络的输出作为网络流汇聚的输入,模型名为 Radflow。它可以生成节点嵌入作为图模型的输入优于 N-BEATS,也可以通过注意力机制采样重要节点处理大规模节点数据集,而且 Radflow 的结构可以处理动态变化的节点关系。此外,注意力与层分解策略为网络与时间的影响提供了可解释性。具体如下:
Radflow 是一个可以进行数十万节点的多变量时序预测的端到端预测模型。
通过层分解与多头注意力为时序模式和网络邻居提供了可解释的预测。
在现实数据集的不同任务上的表现超过了时序模型与网络模型。
此文公开了一个含有 366K 节点和 22M 边的多变量时序预测数据集,名为 WIKITRAFFIC。

Method
4.1 Overview
如下图所示,模型主要由 Recurrent 与 Flow Aggregation 两个模块组成。其中 Recurrent 模块遵循层级分解机制对每个变量进行时序建模,Flow Aggregation 模块根据节点间的消息汇聚对输出结果进行调整。 节点在 时刻的预测值可以表示为:
![]()
其中 表示 Recurrent 模块的预测值, 表示 Flow Aggregation 的预测值。另外 Flow Aggregation 模块以 Recurrent 模块输出为输入。
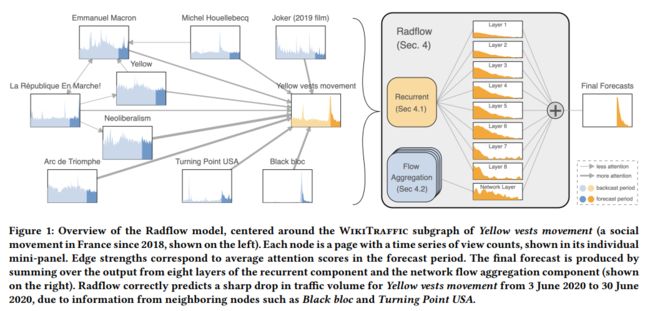
4.2 Recurrent component

Recurrent 模块由 L 个堆叠的 LSTM 组成,具体结构如上图所示,首先对节点观测值使用线性变换将其转到高维空间作为第一层 LSTM 的输入:
![]()
其中 表示可学习的参数。作者表示假设 并且 是全 向量,那么相当于是有了 个并行的 的观测值。
对于 个堆叠的 LSTM 模块, 表示节点 在 时刻的第 个模块的输入,且式 7 表示第一个模块的输入。每个模块将有三个输出值 backcast vector 、forecast vector 和 node vector :

上式中 FeedForward 层有两个线性层夹一个 GELU 激活函数组成:
![]()
backcast vector 是当前层对于残差时间模式的预测并且将作为下一层 LSTM 的输入组成之一:
![]()
forecast vector 是第 个 LSTM 模块对于下一个时间的预测值,下一个时间的 Recurrent 模块预测值为所有当前时间所有 LSTM 的 forecast vector 之和:

其中 ,最后再使用一个线性函数将维度降低为观测维度 作为式 6 的第一项:
![]()
4.3 Flow aggregation component
层首先将 Recurrent 层每个模块输出的 node vector 相加作为流汇聚层的输入:
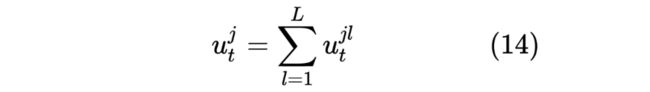
在 IMPUTATION 设置中, 节点在 时刻的邻居节点集合表示为:
![]()
在 FORECAST 设置中,将使用真值得到的 替换为预测值得到的 。然后将 节点在 t 时刻的嵌入映射为 query:
![]()
然后将 t+1 时刻邻居的嵌入映射为 key 和 value:

时刻 节点从邻居节点得到的带权和信息可以表示为:
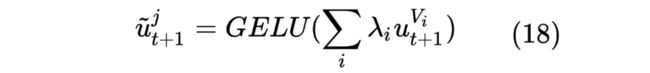
注意力权重 通过 query 与 key 的点积接 softmax 得到。上式中并不包括 节点自身的信息,作者通过参数融合 时刻节点的自身信息与 时刻邻居信息:
![]()
然后再使用一个线性映射将其转换为观测维度 作为式 6 的第二项:
![]()
此外作者还提出了另外两者消息汇聚方式。第一种是将式 18 替换为下式,称为 Radflow-GraphSage:
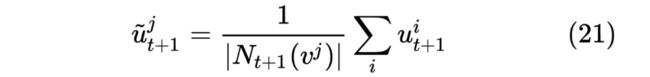
第二种采用更简单的方式去掉式 19 中的线性映射简单相加称为 Radflow-MeanPooling。

Experiments
5.1 Datasets
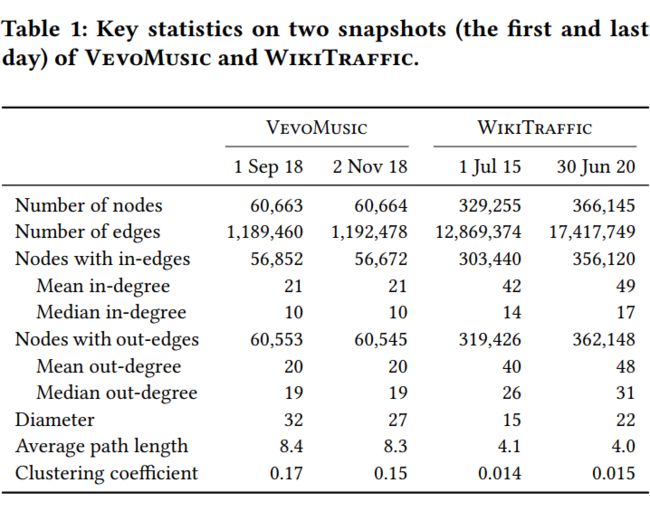
此文使用了四个数据集。分别是根据静态路网结构得到静态图的交通数据集 Los-LOOP 和 SZ-TAXI,以及根据每天的 Youtube 访问顺序变化的 VEVOMUSIC 数据集和根据 WIKI 页面访问顺序变化的 WIKITRAFFIC 数据集。
其中 WIKITRAFFIC 是此文收集的新的数据集。VEVOMUSIC 数据集和 WIKITRAFFIC 数据集都是节点数量上万的大型多变量时序预测数据集,如下图所示。
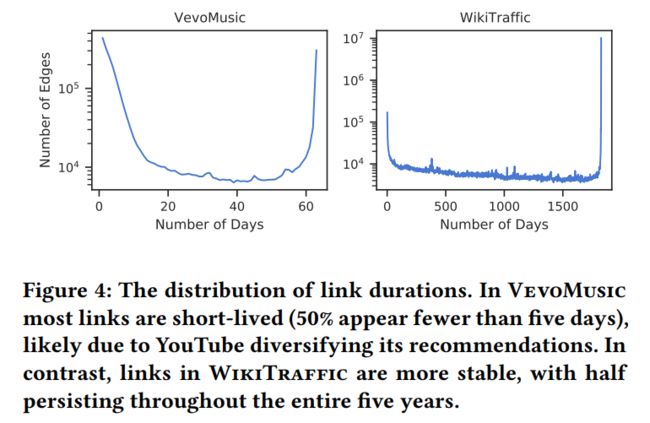
此外此文还展示了两个动态图数据集的边生存时间,可以看出 WIKITRAFFIC 的边存在时间更长。
5.2 Results
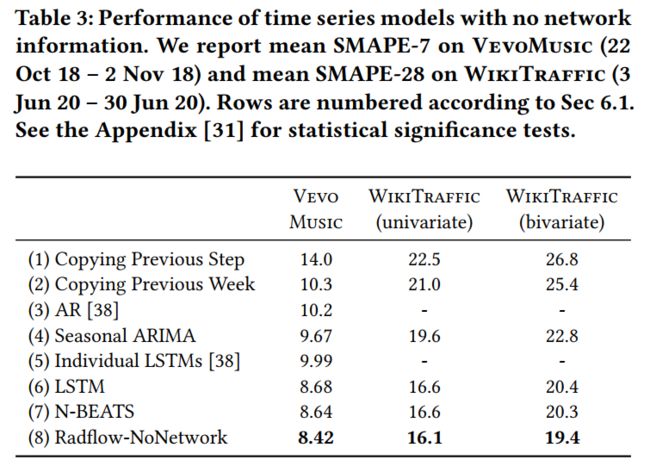
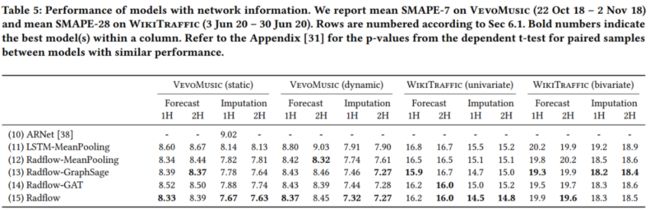
此文首先展示了 Radflow 在不使用图信息的情况下与单变量时序模型的比较,如下图所示 Radflow-NoNetwork 的表现优于 sota 模型 N-BEATS。
然后此文展示了在使用静态图数据集上的表现,优于 sota 模型 T-GCN。Copying Previous Step 表示直接使用历史的最后一个值作为预测值,SMAPE 很低不太懂为什么。

最后此文展示了 Radflow 在基于动态图的大型多变量时序预测数据集上的表现。Radflow-GAT 表示 Aggregation 模块使用 GAT 进行消息汇聚。
5.3 Ablation
作者对 Aggregation 使用的 node vector 做消融实验分别为下图中的 16-20。然后也进行了去除式 19 中的线性变换 no final projection 以及单头注意力 one attention head 实验。

5.4 Visulization
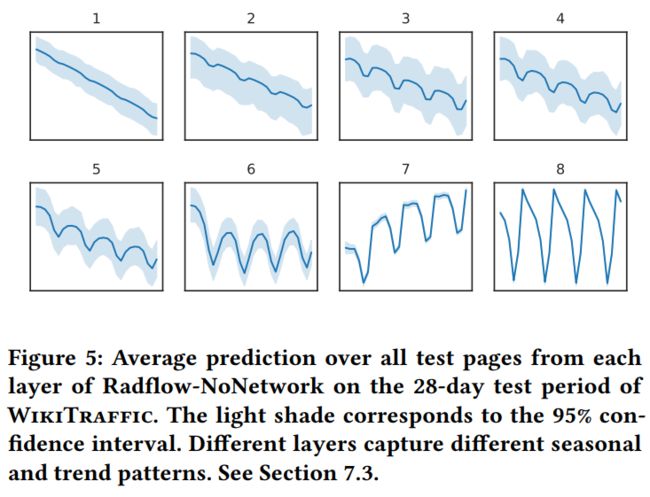
作者可视化了 Recurrent 模块中每一层的预测结果,可以看到每一层预测了不同的时间模式。
然后作者随机去除数据集中的节点与边时模型的表现。可以看出缺失节点时使用图信息的模型鲁棒性更强。

更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
???? 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
???? 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
