统计学习方法---李航
统计学习方法笔记
第一章:统计学习概论
1.1 统计学习
统计学习( statistical learning)是关于计算机基于数据构建概率统计模型并运用模型对数据进行预测与分析的一门学科。统计学习也称为统计机器学习(statistical machine learning). 机器学习称为统计学习更学术化。
Herbert A.simon对“学习”的定义我觉得挺好的:如果一个系统能够通过执行某个过程改进它的性能,这就是学习。
统计学习的对象是数据(data),它从数据出发,提取数据的特征,抽象出数据模型,发现数据中的知识,又回到数据的分析和预测中去。
统计学习关于数据的基本假设是:同类数据具有一定的统计规律性。
统计学习的目的是用于对数据的预测与分析,对别是对未知新数据进行预测与分析。
实现统计学习方法步骤
(1) 得到有限训练数据集合
(2) 确定包含所有可能的模型的假设空间,即学习模型的集合
(3)确定模型选择的准则,即学习的策略
(4)实现求解最优模型的算法,即学习的算法
(5)通过学习方法选择最优的模型
(6)利用学习的最优模型对新数据进行预测或分析
。。。。。。。。所以说统计学习就是机器学习,都一样的。
1.2 监督学习
统计学习包括:监督学习、非监督学习、半监督学习以及强化学习。本书主要讨论监督学习的问题。
这个就很基础了,没有什么值得记录的。
1.3 统计学习三要素
方法 = 模型+策略+算法
模型设计假设空间,决策函数,和数理统计讲的都差不多。
策略设计损失函数,风险函数,经验风险最小化,结构风险最小化,也和数理统计大差不差。
算法就对应不同问题用不同算法求解了。
监督学习方法又可以分为生成方法和判别方法,所学到的模型分别称为生成模型和判别模型。
生成方法由数据学习联合分布概率P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型:P(Y|X)=P(X,Y)/P(X), 这样的方法称为生成方法,是因为模型表示了给定输入X缠身输出Y的生成关系。典型的生成模型有:朴素贝叶斯和隐马尔可夫模型。
判别方法是由数据直接学习策略函数f(X)或者条件概率分布P(Y|X)作为预测模型,即判别模型。判别方法关心的是对给定的输入X,应该预测什么样的输出Y。典型的判别模型有:k近邻,感知机,决策树支持向量机等。
第二章 感知机
感知机是二分类的线性分类模型。
第三章 k 近邻法
k近邻法假设给定一个训练集,其中实例类别已定,分类时,对新的实例,根据其k个最近邻的训练实例的类别,通过多数表决等方式进行预测。-----因此k近邻法不具有显示的学习过程-----k近邻法实际上利用训练数据集对特征空间进行划分,并作为其分类的模型。
k值的选择,距离度量以及分类的决策规则是k近邻法的三个基本要素。k近邻法1968年由cover和Hart提出。
k近邻法的特殊情况是k=1的情形,成为最近邻算法。
k近邻算法没有显示的学习过程。
图3.2给出了二维空间中p取不同值时,与原点的Lp距离为1(Lp=1)的点的图形
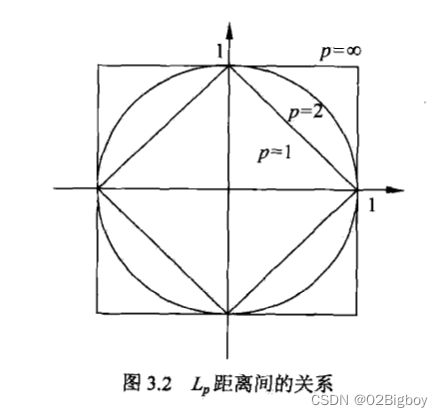
由不同的距离度量所确定的最近邻点是不同的。
如果k值选择较小的值,只有与输入实例较近的(相似的)训练实例才会对预测结果起作用,但缺点是“学习”的估计误差会增大,预测结果会对近邻的实例点非常敏感,如果近邻的实例点恰巧是噪声,预测就会出错。换句话说,k值的减小就意味着整体模型变得非常复杂,容易发生过拟合。
如果选择较大的k值,就相当于用较大邻域中的训练实例进行预测,其优点是可以减少学习的估计误差。但缺点是学习的近似误差会增大,这时与输入实例较远的(不相似)训练实例也会对预测起作用,使预测发生错误。k值增大就意味着整体模型变得简单。
第四章 朴素贝叶斯法
朴素贝叶斯是生成方法,是根据训练样本学习标签的先验概率,以及条件分布,然后用贝叶斯求最大后验概率。
基本假设是条件独立。即联合的条件概率可以等于多个条件概率的乘积。
算法过程:

一个具体的实例为:

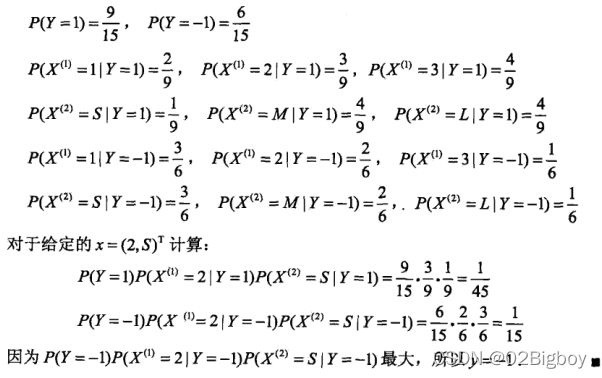
通过这上面的例子,可以清楚地理解朴素贝叶斯的过程。
但我觉得朴素贝叶斯只适合于每一维度特征取值很少的情况,或者说这种离散的情况,因为这样那个条件概率才能计算。
但用上面的方法,相当于是极大似然估计,会出现所要估计的概率值为0 的情况,这会影响到后验概率的计算结果,使分类产生偏差,解决这一问题的方法是采用贝叶斯估计。具体的条件概率的贝叶斯估计是:

式中λ大于等于0.等价于在随机变量各个取值的频数上赋予一个正数λ,sj就等于一共有对少个取值。
上面的方法可以解决条件概率为0的情况。
第五章 决策树
决策树是一种基本的分类和回归方法。本章主要讨论用于分类的决策树。
其主要优点是:模型具有可读性,分类速度快。
决策树学习通常包括三个步骤:特征选择,决策树的生成进而决策树的修剪。
决策树由节点和有向边组成。节点有两种类型:内部节点和叶节点。
内部结点:表示一个特征或者属性
叶结点:表示一个类
决策树对应于对应的条件分布。
如下图一个决策树的图:
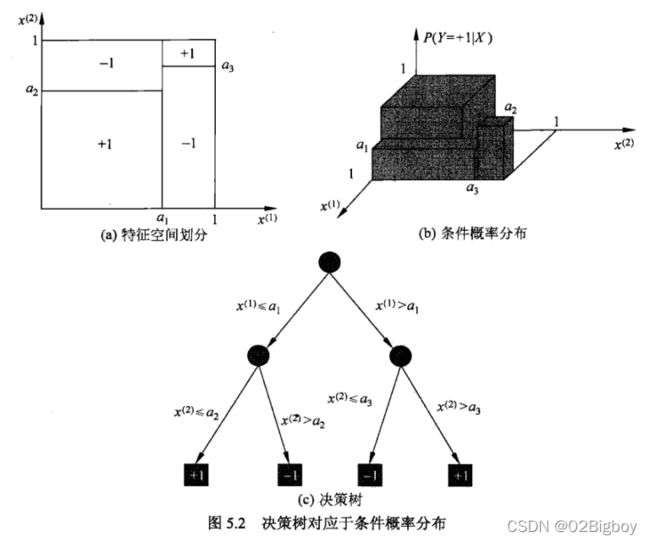
决策树本质上是从训练数据集中归纳出一组分类规则。与训练集不相矛盾的决策树可能有多个,也可能一个都没有,我们需要的是一个与训练数据矛盾较小的决策树,同时具有很好的泛化能力。
一般我们肯定是要选择具有分类能力的特征来构建树。所以我们需要对特征进行选择,特征选择的准则是信息增益或信息增益比。
信息增益其实就是互信息:表示得知特征X的信息而使得类Y的信息不确定性减少的程度。
而信息增益比是指,信息增益除以训练集的经验熵。
算法本章讲了:
ID3算法:是用信息增益准则来选择特征,递归的构建决策树
C4.5算法:用信息增益比来选择特征的
决策树往往对训练数据的分类很准确,但对未知的测试数据的分类却没有那么准确,即出现过拟合的线性。
那怎么办呢?
决策树的剪枝
决策树的剪枝通过优化损失函数还考虑了减小模型复杂度,然后选择达到一个平衡的状态。
讲了一个典型的CART算法。
第六章 逻辑斯谛(logistic)回归与最大熵模型
logistic regression是统计学习中经典的分类方法。
logistic分布:

对应的分布密度和分布函数图形为:
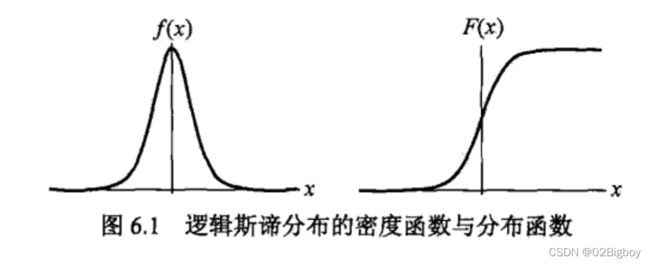
分布函数是以点(u,0.5)为中心对称。
二项逻辑回归模型:

一个事件的几率(odds):是指该事件发生的概率与该事件不发生的概率的比值。如果一个事件发生的概率是p,那么该事件的几率是p/(1-p)。几率这个词很陌生,但是他的对数几率(log odds)却有点熟悉:
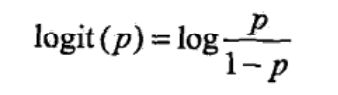
然后就可以得出,逻辑回归中,输出Y=1的对数几率是输入函数x的线性函数。
二项推广到多项逻辑斯蒂回归(multi-nominal logistic regression model),用于多类分类。
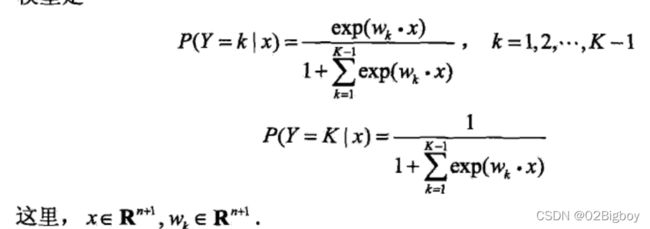
最大熵模型
最大熵原理认为:学习概率模型时,在所有可能的概率模型(分布)中,熵最大的模型是最好的模型。
在没有更多地信息的情况下,让那些不确定的都等可能,则能达到熵最大。
然后一般通过最大熵来学习回归模型。
第七章 支持向量机
支持向量机(SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器。
当训练数据线性可分时,即线性可分支持向量机
当训练数据近似线性可分时,通过软间隔最大化,也学习一个线性的分类器,即线性支持向量机,又称为软间隔支持向量机
当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机。
当输入空间为欧式空间或离散集合、特征空间为希尔伯特空间时,核函数表示将输入从输入空间映射到特征空间得到的特征向量之间的内积,通过核函数可以学习非线性支持向量机,等价于隐式地在高维特征空间中学习线性支持向量机。
内积:

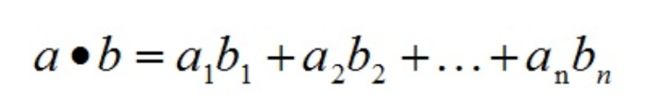
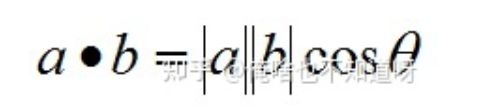
内积的物理意义:表征b在a方向上的投影,也可以计算他们之间的夹角。向量的内积是一个数
外积:

线性可分支持向量机
一般的当训练数据集可分时,存在无穷个分离超平面可将两类数据正确分开。感知机利用误分类最小策略,求得分离超平面,不过这时有无穷多个。线性可分支持向量机利用间隔最大化求最优超平面,这时,解是惟一的。
函数间隔:来表示分类的正确性以及确信度。同号表示正确,大小表示确信度(离平面越远分类置信度越高)
几何间隔:就是点到平面的距离
最小几何距离:所有点到平面的最小距离
最大间隔分离超平面:最大化–最小几何距离。
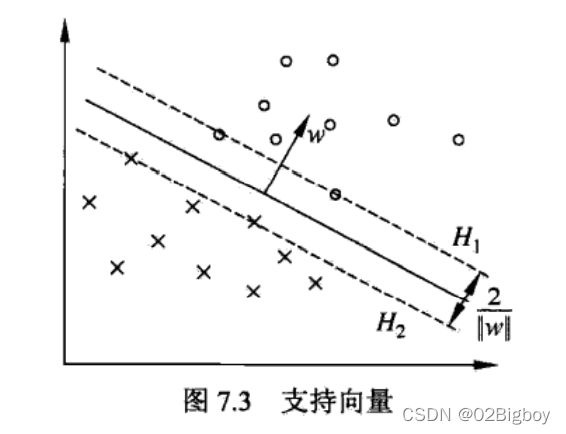
支持向量机:训练数据集的样本点中与分离超平面距离最近的样本点的实例。
叫这个名字的原因是:决定超平面时,只有支持向量机起作用,而其他实例点并不起作用,如果移动支持向量将改变所求的解,但移动其他点,甚至去掉这些点,解是不会改变的。所以支持向量在确定分离超平面中起着决定性作用,所以将这类分类模型成为支持向量机。
那对于线性不可分的数据集而言,怎么用线性支持向量机呢,就在上面的优化式子里面加一个松弛变量:

然后目标函数变成:

这样就可以求解了。

上面的优化问题可以转变为合页损失,即

非线性支持向量机与核函数。
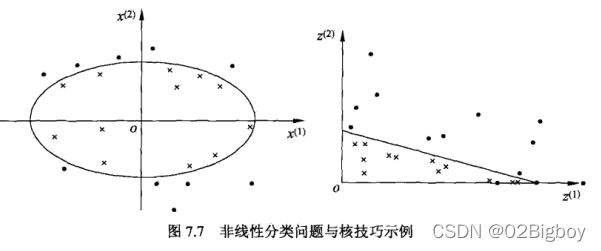
非线性分类问题分两步:1.首先使用一个变换将原空间的数据映射到新空间;2.然后再在新空间里用线性分类器学习方法从训练数据中学习分类模型。核技巧就是这样的方法。
核函数:设X是输入空间,又设H为特征空间(希尔伯特空间),如果存在一个从X到H的映射:
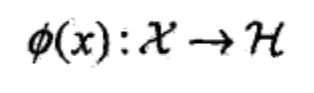

***核技巧***的想法就是,在学习与预测中只定义核函数K(x,z),而不显示的定义映射函数φ。通常直接计算K(x,z)比较容易,而通过φ(x)和φ(z)计算K(x,z)并不容易。注意φ是输入空间到特征空间的映射,特征空间一般是高维的,甚至是无穷维的。可以看到对于给定的核K(x,z),特征空间和映射函数φ的取法并不唯一,如下例所示:

核技巧在支持向量机的作用:在支持向量的对偶问题中,目标函数 内积可以用核函数来代替
![]()
x.x是原空间内积,K(x,z)是特征空间的内积。
上面等价于,经过映射函数φ将原来的输入空间变换到一个新的特征空间。
核函数选择的有效性需要通过实验验证!
构建希尔伯特空间的步骤:首先定义映射φ并构成向量空间S,然后在S上定义内积构成内积空间,最后将S完备化构成希尔伯特空间。
定义映射:

希尔伯特空间也叫可再生希尔伯特空间,因为可再生核:

常用的核:
多项式核和高斯核:

***内积换成核函数!!!***就是核函数的技巧。
第八章 提升方法
提升(boosting)方法是一种常用的统计学习方法,在分类问题中,它通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性能。
提升方法基于这样的一种***思想***:对于一个复杂任务来说,将多个专家的判断进行适当的综合所得出的判断,要比其中任何一个专家单独的判断好。实际上,就是“三个臭皮匠顶个诸葛亮”的道理。
AdaBoost算法
主要思想:
- 改变训练数据的权值: 提高那些被前一轮弱分类器错误分类样本的权重,而降低那些被正确分类样本的权值;
- 弱分类器组合成一个强分类器: 加大分类误差率小的弱分类器的权值
提升数
提升树部分没太看懂。
第九章 EM算法及其推广
EM算法:是一种迭代算法,用于含有隐变量(hidden variable)的概率模型参数的极大似然估计
EM每次迭代由两部分组成:
E步:求期望(expectation)
M步:求极大(maximization)
如果概率模型的变量都是观测变量,那么给定数据,可以直接利用最大似然估计法,或贝叶斯估计方法估计模型参数。但是当模型含有隐变量,就不能简单使用这些估计方法。
那什么是隐变量?
通过一个扔硬币的例子理解什么是隐变量:

这里未观测到掷硬币A的结果,但这个结果会对观测值造成影响,这样的变量称作隐变量。
这样的问题解法一般是:
1.列出概率模型:

我们用极大似然估计即可求出对应的参数。
这个问题没有解析解(未知参数不能直接由已知参量表示),只有通过迭代的方法求解。
2. 给出此时隐变量的概率分布时,的条件概率均值

3.用极大化似然估计,根据2求出的式子,算参数,更新参数,迭代。

每次迭代相当于在求Q函数及其最大。
关于EM算法,这里放一个博客.:我觉得比李航这本书讲的清晰。


EM:就是变量之间求解互相关,我们先初始化一部分参数,然后求解剩下的参数,剩下的参数求解完后,我们可以更新初始化参数,然后一步步迭代,最终结果就非常接近解。