图灵奖评委们,明年可以考虑下这两位 AI 先驱
雷锋网 AI 科技评论:昨日毫无疑问是振奋人心的一天,深度学习界的 3 位「巨头」齐齐获得计算机界最高荣誉「图灵奖」,这里再次祝贺 Yoshua Bengio、 Yann LeCun 以及 Geoffrey Hinton!
谈及今年颁奖理由时,美国计算机协会主席 Cherri M. Pancake 在一份声明中表示:「人工智能的发展和繁荣,在很大程度上要归功于 Bengio、Hinton 和 LeCun 为之奠定基础的深度学习的最新进展。这些技术被数十亿人使用。只要拥有智能手机的人现在都能实实在在地体验到自然语言处理和计算机视觉方面的进步,而这些体验在 10 年前是想都不敢想的。」
不过,在得奖消息公布后,也有人在社交媒体上为落选的「遗珠」抱屈,他们认为还有这么一批人,虽然名气不大,对于 AI 研究的发展却做出了不亚于三位巨头的贡献。

递归神经网络之父——Jürgen Schmidhuber

Jürgen Schmidhuber 是瑞士人工智能实验室(IDSIA)的研发主任,他所发明的 LSTM(长短期记忆网络),有效解决了人工智能系统的记忆问题。
昨日颁奖消息公布后,为他抱屈的声音极多,部分人认为「深度学习」少了他终究不够圆满。
推一下眼镜的表情富含深意……
一战成名的 LSTM
要了解 LSTM,还得从循环神经网络(Recurrent Neural Network,RNN)开始说起。
RNN 是一种用于处理序列数据的神经网络,相比一般的神经网络,更擅于处理序列多变的数据(比如某个单词的意思会因为上文提到的内容不同而有不同的含义)然而其技术缺陷也非常明显,其中一项便是梯度消失:
RNN 模型在某些的取值上,梯度特别小(几乎为 0)。这也意味着,如果在控制学习率不变的情况下,要么参数不变(学不到东西),要么就变化极大(学习成果推倒重来)。
因此 RNN 在参数学习上很难表现出彩。
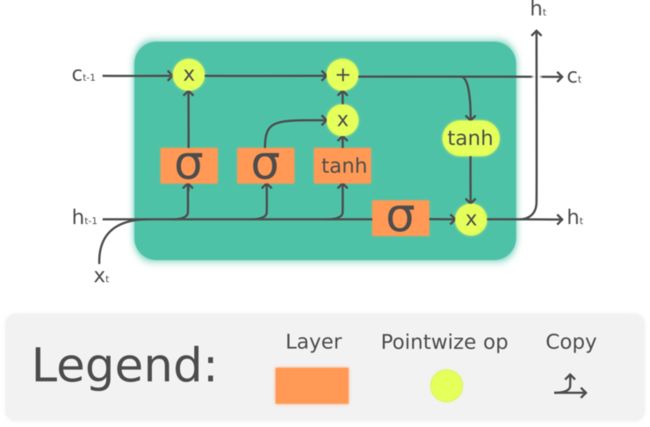
而 LSTM 则可以理解为 RNN 的升级版,其结构天然可以解决梯度消失问题。其内部主要可以分为三个阶段:
忘记阶段
这个阶段主要是对上一个节点传进来的输入进行选择性忘记。简单来说就是会「忘记不重要的,记住重要的」。
——由一个被称为「遗忘门层」的 Sigmod 层组成的。它输入 ht−1 和 xt, 然后在 Ct−1 的每个神经元状态输出 0~1 之间的数字。「1」表示「完全保留这个」,「0」表示「完全遗忘这个」。
选择记忆阶段
这个阶段将这个阶段的输入有选择性地进行「记忆」。哪些重要则着重记录下来,哪些不重要,则少记一些。
——首先,一个被称为「输入门层」的 Sigmod 层决定我们要更新的数值。然后,一个 tanh 层生成一个新的候选数值,Ct˜, 它会被增加到神经元状态中。
输出阶段
这个阶段将决定哪些将会被当成当前状态的输出。
——首先,我们使用 Sigmod 层决定哪一部分的神经元状态需要被输出;然后我们让神经元状态经过 tanh(让输出值变为-1~1 之间)层并且乘上 Sigmod 门限的输出,我们只输出我们想要输出的。
Jürgen Schmidhuber 把这种人工智能训练比作人类大脑将大的时刻过滤成长期记忆,而让更平常的记忆消失的方式。「LSTM 可以学会把重要的东西放在记忆里,忽略那些不重要的东西。在当今世界,LSTM 可以在许多非常重要的事情上表现出色,其中最著名的是语音识别和语言翻译,还有图像字幕,你可以在那里看到一个图像,然后你就能写出能解释你所看到的东西的词语。」他如此表示道。
而现实正如 Jürgen Schmidhuber 所说的,LSTM 确实足够出色,以致无论是苹果、谷歌、微软、Facebook 还是亚马逊都在自家业务中采用了 LSTM——Facebook 应用 LSTM 完成每天 45 亿次的翻译;Google 29% 的数据中心计算能力使用 LSTM(CNN 仅占 5%);LSTM 不仅改善了近 10 亿部 iPhone 手机中的 Siri 和 QuickType 功能,更为超过 20 亿部 Android 手机语音识别提供支持;LSTM 还是亚马逊 Alexa 和 Google 语音识别器的核心。
LSTM 的巨大成功,导致后来每当有人提到利用 RNN 取得卓越成果时,都会默认是 LSTM 的功劳。
通用人工智能梦
然而 Jürgen Schmidhuber 并未满足于 LSTM 的成功,他的终极归宿是 AGI(通用人工智能)。
两年前接受雷锋网(公众号:雷锋网) AI 科技评论采访时,Jürgen Schmidhuber 明确表示自己有一项「商业上认知不是很广,但是却是非常重要的研究」——如何让机器具备自我学习、更聪明的能力。在他一篇 1987 年的论文中,他详细描述了元学习(Meta Learning,或者叫做 Learning to Learn)计划的第一个具体研究,即不仅学习如何解决问题,而且学习提高自己的学习算法,通过递归自我学习最终成为超级人工智能。但这种设想受限当时的计算性能力无法进得到充分验证。
坚信 AGI 一定能实现的背后,是他坚信「我们生活在一个矩阵式的计算机模拟中」的理念。「这就是我的想法,因为这是对一切事物最简单的解释。「他的理论认为,人类一开始就设定为要不断追逐进步,并将继续制造更强大的计算机,直到我们让自己变得过时或者决定与智能机器合并为止。
为此,Schmidhuber 曾经预言:「要么你变成了一个真正不同于人类的东西,要么你出于怀旧的原因依然以人的身份存在。但你不会成为一个主要的决策者,你不会在塑造世界的过程中扮演任何角色。」
争议
在查阅资料的过程中,你会发现 Jürgen Schmidhuber 的「傲气」无处不在。
年轻的时候,他是那个会在履历学术经历一栏写上「拒绝加州理工学院的博士后录取通知」的学术青年。2016 年的神经信息处理系统大会上,他当场质疑 Ian Goodfellow 的「生成对抗网络」是抄袭了他在 1992 年的一项研究。后来,他在《自然》杂志的留言板上与所有人工智能大佬开怼,指责他们扭曲了人工智能的历史,抹去了他和其他人最初的想法。
阿尔伯塔大学的研究人员 Kory Mathewson 说过,与 Jürgen Schmidhuber 起冲突甚至成为某种「潜在的仪式」,有些年轻的 AI 研究人员甚至期待有朝一日能够获得这个「待遇」。但对于一些资深的研究人员来说,Jürgen Schmidhuber 可能就是麻烦的存在,比如他经常被认为只会「抱怨」、「虚伪」、「自私」、「过分强调理论的价值」。
对此,他依然固守己见。「每当我看到有人做了重要的事情,而他没有得到认可,但有人又说另一个人先做了那件事,那么我是第一个把这个信息传递给《自然》杂志、《科学》杂志或其他期刊上的人。你可以通过时间脉络来证明谁先做了什么。说得好听点,其他的一切都是再创造,说得难听一点,这是剽窃。」
因此,不少人怀疑,这正是 Jürgen Schmidhuber 无法在图灵奖名单上出现的原因。
支持向量机(SVM)之父——Vladimir Vapnik

另外一名呼声极高的,是奠定了统计学习理论的 Vladimir Vapnik,他主要成就有二:
与另一名苏联数学家合写了著名的统计学习理论 Vapnik–Chervonenkis theory(VC 维)
在上述理论基础上发展出支持向量机 (Support Vector Machine,简称 SVM) 演算法
SVM 演算法
1971 年,Vladimir Vapnik 与 A. Chervonenkis 在论文《On the uniform convergence of relative frequencies of events to their probabilities》中提出了 Vapnik–Chervonenkis theory,它表明机器学习算法选择的模型的错误率,是两个因素的作用结果:
模型类越大,分类器错误率的聚集性 (收敛到泛化错误率的速度) 就越差。
模型类越大,拟合数据效果也越好。
总的来说,根据泛化错误率 <= 经验错误率 + 泛化界,我们必须权衡模型的复杂度,以最小化泛化错误率。
在此基础上,Vladimir Vapnik 等人对线性分类器提出了另一种设计最佳准则。其原理从线性可分说起,然后扩展到线性不可分以及非线性函数中去,这种分类器被称为支持向量机(Support Vector Machine,简称 SVM)。SVM 最早是由 Vladimir N.Vapnik 和 Alexey Ya.Chervonenkis 在 1963 年提出,目前的版本(soft margin)是 Corinna Cortes 和 Vapnik 在 1993 年提出,1995 年发表。
SVM 主要是针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能。
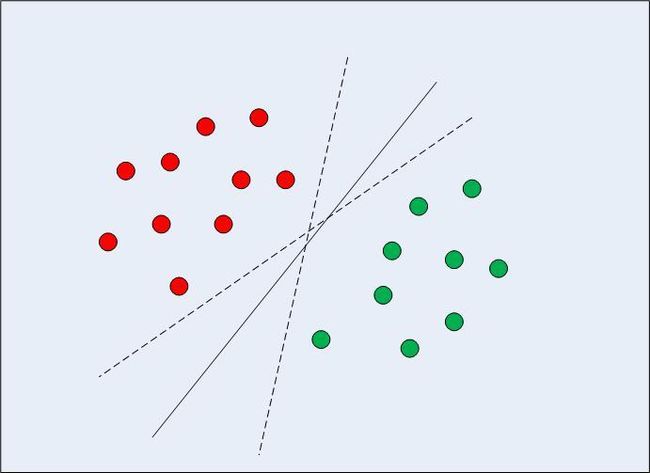
这让泛化对空间中数据点的测量误差容忍度更大,再结合作为非线性扩充的「内核技巧」(kernel trick),支持向量机算法就成了机器学习中的重要支柱。
目前 SVM 已经被广泛运用在各个领域,尤其是许多工程领域,并成功解决了许多真实界问题背后的关键演算法,像是文字分类、超文本(网页分类)、图像辨识、生物资讯学(蛋白质分类、癌症特徵分类)、手写笔迹辨识等。可说是自动分类技术中最重要的关键演算法之一。
一度「压制」深度学习
当 Vapnik 和 Cortes 在 1995 年提出支持向量机(SVM)理论后,机器学习这一领域便分成了两大流派——神经网络及支持向量机。2000 年内核版的 SVM 被提出后,神经网络在这场竞争中逐渐处于下风。
换句话说,在深度学习还没火起来以前,支持向量机(support vector machine)是毫无疑问的主流。2002 - 2014 年期间,在 NEC Lab 工作的 Vladimir Vapnik 在支持向量机领域的地位与今天的 Geoffrey Hinton 之于深度学习不相伯仲。
对于支持向量机与深度学习的纠葛,阿里巴巴技术副总裁贾扬清曾经在知乎上有过这么一段论述:
这两个冤家一直不争上下,最近基于神经网络的深度学习因为 AlphaGo 等热门时事,促使神经网络的热度达到了空前最高。毕竟,深度学习那样的多层隐含层的结构,犹如一个黑盒子,一个学习能力极强的潘多拉盒子。有人或许就觉得这就是我们真正的神经网络,我们不知道它那数以百千计的神经元干了什么,也不理解为何如此的结构能诞生如此美好的数据——犹如复杂性科学般,处于高层的我们并不能知道底层的」愚群「为何能涌现。两者一比起来,SVM 似乎也没有深度学习等那么令人狂热,连 Hinton 都开玩笑说 SVM 不过是浅度学习(来自深度学习的调侃)。
不然,个人觉得相对于热衷于隐含层的神经网络,具有深厚的数学理论的 SVM 更值得让我们研究。SVM 背后伟大的数学理论基础可以说是现今人类的伟大数学成就,因此 SVM 的解释性也非神经网络可比,可以说,它的数学理论让它充满了理性,这样的理性是一个理工科生向往的。
SVM 的高效性能并且在神经网络无法取得较好效果的领域的优异表现,此外,支持向量机能够利用所有的先验知识做凸优化选择,产生准确的理论和核模型,因此可以对不同的学科产生大的推动,产生非常高效的理论和实践改善。
最后,想与各位聊聊,你心目中的图灵奖人选还有谁?
参考文献:
1)《理解长短期记忆(LSTM) 神经网络》. 元峰
https://zhuanlan.zhihu.com/p/24018768
2)《为什么相比于RNN,LSTM在梯度消失上表现更好?》. 刘通
https://www.zhihu.com/question/44895610/answer/616818627
3)《他是人工智能教父,却快要被世人遗忘》. Joyce Lee . 机器人网
https://www.roboticschina.com/news/2018051811Schmidhuber.html
4)《Vapnik-Chervonenkis理论》. zccg
https://zhuanlan.zhihu.com/p/22457275
5)《如何理解SVM | 支持向量机之我见》. 煎鱼不可能有BUG
https://www.jianshu.com/p/96e8fad1a2a4#
6)贾扬清在知乎上的回答
https://www.zhihu.com/question/22290096/answer/52642714
雷锋网 AI 科技评论 雷锋网