模型也可以上网课?手把手教你在query-doc匹配模型上实现蒸馏优化!

导语 | 本文主要介绍我们在视频的query-doc匹配模型上进行的模型蒸馏技术优化,第一章介绍知识蒸馏概念、业务模型难点以及现有方案不足;第二章介绍匹配模型细节以及模型蒸馏整体框架;第三章介绍我们在蒸馏方案上的优化点,包括ALBERT/CNN学生模型选择、更好的teacher得分loss指导以及AutoML搜索;第四章是模型压缩实验结果展示。
一、 前言
(一)知识蒸馏
知识蒸馏(Knowledge Distillation)概念是由Hinton在NIPS2014提出,旨在把一个或多个模型(teacher模型)学到的知识迁移到另一个模型(student模型)上,student模型通常使用轻量化的模型,来达到模型压缩的效果。
我们利用模型蒸馏技术,对query-doc匹配的BERT模型进行压缩,最终得到一个1L的轻量BERT模型并成功上线接入。本文将对相关技术方案进行介绍。
(二)现有方案
现有蒸馏方案,如TinyBERT,DistillBERT等,都只对原始的12L BERT模型进行一定尺度内的压缩,最多压缩到4L,hiddensize 312的时候,精度下降就已经很严重了。在现在的任务上,直接复用现有方案,是没办法达到上线要求的,因此,我们在此基础上提出了一系列优化方案,主要目的是保证模型大小更进一步压缩的时候,尽量减少AUC的损失。
我们的优化方案,包括student模型选择(1L ALBERT和textCNN),更好的teacher模型指导(relevance loss)以及AutoML搜索能力的加入(蒸馏超参调优),下面会详细介绍。
二、 模型介绍
(一)query-doc匹配模型
原始匹配模型结构如下。模型接收一个文本对query-doc的输入,经过BERT-encoder编码,得到seq_len长度的hidden state,我们选取: cls位置的hidden vector、所有hidden state的max pool vector、average pool vector三者进行拼接,经过两个线性层和激活层Tanh的处理,最终得到1-dim的匹配分数score。

模型训练阶段。我们将每条训练数据([query,positive doc,negative doc]三元组)处理为(query,positive doc) (query,negative doc)两个文本对,经过上述处理得到对应的positive score和negative score,然后使用这两个分数计算hinge loss(详见下文loss计算部分),作为训练任务的loss值。
在模型结构上,通过finetune训练了减少layer Num/hidden size/immediate size的BERT模型。通过添加Mask Language Mask和Named Entity Recognition的任务进一步优化匹配AUC,最终我们得到了AUC 0.845,latency12ms的 64hidden_size-128immediate_size-4L BERT,以及AUC 0.831,latency 6.7ms的64hidden_size-128immediate_size-2L BERT。为进一步减少模型latency并维持高精度,我们决定采用模型蒸馏工作,使用4L BERT作为teacher模型,蒸馏到更加轻量的模型结构上,同时尽量保证精度不下降。
(二)蒸馏框架
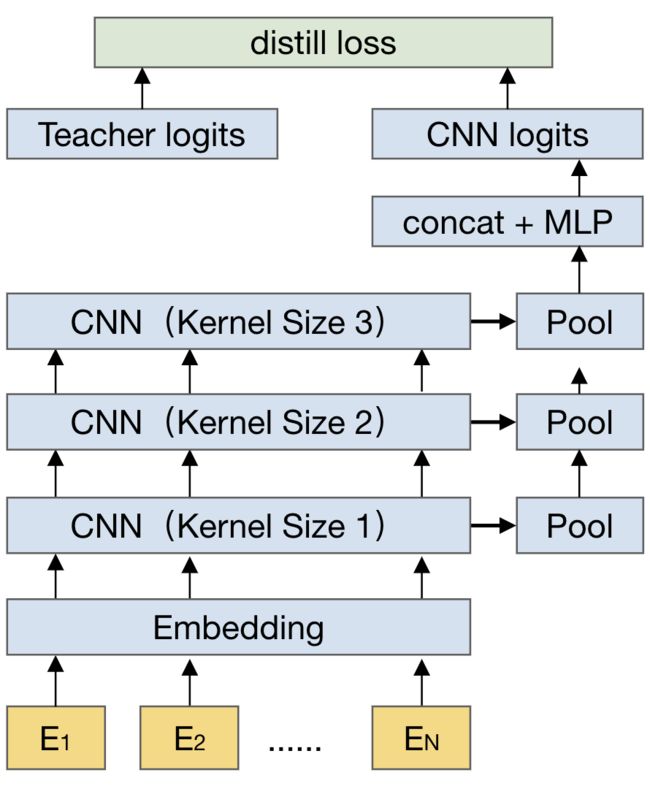
整体流程

如上图所示,参考经典的蒸馏框架Distilled BiLSTM ,我们将蒸馏点选在最后的score层,将模型正负样本对(query,postitive doc) ( query,negative doc) 的两个输出值(postitive score,negative score)拼接作为logits,用于计算蒸馏的soft loss,hardloss即为student模型和ground truth计算的的hinge loss。最终的distill loss由softloss和hardloss两部分加权获得(见下一节Loss计算)。
训练过程中,固定finetune好的teacher(4L BERT)参数,只利用distill loss对student模型进行梯度优化。
Loss计算
模型蒸馏的损失函数通常由soft loss和 hard loss两部分组成,soft loss使用MSE计算student logits和teacher logits的距离,使得student模型可以学到大模型teacher的知识;hard loss为ground truth和student模型输出的hinge loss,从而对teacher的错误知识做一定的纠偏。

Hinge Loss
该任务中选择了匹配模型常见的hinge Loss作为hard loss,采用业务方经验值0.7做为阈值,对正负样本对得分
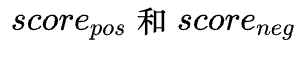
进行loss计算:
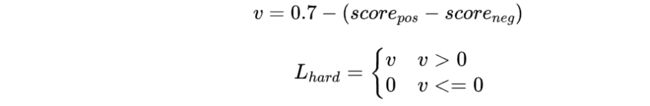
MSE loss
Soft loss用于让student模型的输出接近于teacher模型,从而尽可能学习到teacher模型所携带的信息。
首先,我们采用student和4L bert teacher模型输出的均方误差(MSE)计算logits loss。
![]()
此外,为了提升蒸馏模型精度,我们利用加入多维度匹配得分特征训练的更好的下游相关性模型(GBDT)作为额外的teacher指导模型蒸馏(详见第三章第2小节),它的损失我们记为relevance loss( ),计算方式与logits loss类似:
),计算方式与logits loss类似:
![]()
Distill Loss
为了加快模型收敛速度,我们用指数的方式对上文的每个loss进行放大(下方公式)。另外对soft loss之间的加权,以及soft loss和hard loss的加权都应用了相应权重控制(α和β),并配合下文中的AutoML能力搜索最为合适的权值。
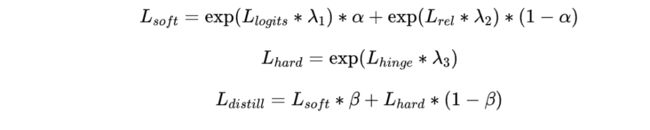
三、压缩方案优化
(一)更轻量的student模型选择
ALBERT模型选择
为了尽量压缩模型的latency,在transformer结构上,我们需要把student BERT的层数缩减到2层甚至1层。考虑到这种情况下,模型本身参数量已经非常少了,蒸馏的时候初始化参数如果从teacher模型中取的话,只能复用上很少一部分的参数量,我们最终选择ALBERT模型来作为teacher和student模型结构。ALBERT的特点之一是采用了层间参数共享的机制,举例来说说,一个4L的BERT模型中,每一层都共享使用的同一层的模型参数,我们使用一个更小的ALBERT模型蒸馏的时候,可以从teacher的共享层参数中做初始化。这样的好处是可以从共享层的参数中尽可能多的继承teacher模型的预训练信息,让蒸馏过程中的student模型更容易达到teacher模型的效果。
我们尝试了2L和1L的ALBERT,其latency和精度相比普通BERT结构都有所提升。最终我们在1L的ALBERT模型上得到了最好的latency以及超过原始4L BERT 1.7%的AUC(见第四章实验结果)。最终,我们将student模型选定为1L-ALBERT的结构。

CNN模型尝试
在模型蒸馏的student模型选择上,除了将层数少/参数少的Transformer结构之外,我们还尝试了将其蒸馏到CNN模型结构上。在这个匹配任务中,我们选择了非常轻量的textCNN模型作为student。
最初的设计中TextCNN直接复用Teacher模型的Embedding层,通过拼接不同大小的卷积核提取出来的隐层特征值来计算匹配得分。为进一步提升蒸馏模型性能,我们还尝试了将Teacher模型的BERT Embedding替换为腾讯开源的Word2Vec Embedding,同时采用QQSeg分词器进行分词,相较于替换前获得了1.5%的auc提升,配合更好的GBDT teacher模型指导和AutoML搜索,得到了3.55ms的latency并且AUC略微超越4L BERT Teacher模型。
(二)更好的teacher指导
为进一步提升蒸馏性能,我们尝试采用性能更高的teacher模型来辅助指导蒸馏。这里选择了当前搜索排序模型依赖精排GBDT模型,这个模型是线上精排的下游模型,基于人工标注的真实数据训练,并在特征工程中加入了多个不同维度的文本匹配及相关性判断打分,以及一些人工设定的相关性规则。
多种维度上的相似性得分特征,使得GBDT模型可以在当前任务上取得超过BERT单模型的精度效果。我们采用GBDT模型输出的logits(relevance score)与student模型的logits计算MSE的的relevance loss,进一步指导模型蒸馏,大幅提升了student模型的性能。
蒸馏后的student模型,又可以放回GBDT模型中,作为语义特征表示,反过来提升GBDT模型的AUC值,且因为采用了非常轻量的模型结构,推理速度以及资源消耗可以达到上线标准。
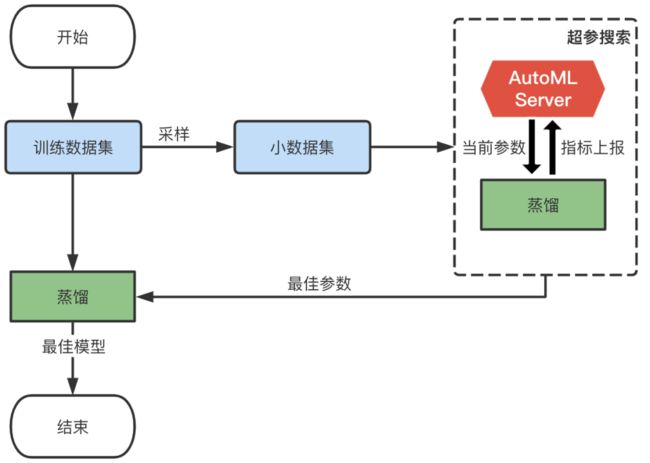
(三)AutoML搜索更好的超参配置
模型蒸馏过程中,存在很多超参数,比如学习率,蒸馏loss的权重配比等,这些超参数的配置对模型性能影响还是比较大的,为了得到最优的参数配置,我们利用了Venus上的自动调参能力进行AutoML搜索。
考虑到模型训练数据量较大,我们首先对训练数据集进行了采样,只用6%的数据量进行搜索,搜索时长设置为24h(模型全量训练耗时平均23h),最终获取在采样数据集上搜索得到的最佳配置,再用全量数据进行finetune,AUC相比于人工经验设定的超参数结果还能有0.6%的提升(详见模型性能)
四、 模型性能
线下实验效果展示:

实验配置:
batch_size=10,max_seq_len=128,8核CPU
结果说明:
通过加入relevance loss的模型蒸馏技术,我们可以在1L的ALBERT结构以及CNN-attention结构下取得超过人工调优的4L BERT模型,并且推理latency均压缩至5ms以下,达到上线标准。其中,1L ALBERT蒸馏,更是在线下测试中取得了2.99ms的latency以及2.4%的AUC提升,在线上测试中也取得了较好的效果。
参考资料:
1.Hinton@NIPS2014:Distilling the Knowledge in a Neural Network
2.Distilling Task-Specific Knowledge from BERT into Simple Neural Networks
3.ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
4.Transformer to CNN: Label-scarce distillation for efficient text classification
作者简介

王瑞琛
腾讯应用研究工程师
腾讯应用研究工程师,目前专注于通用模型压缩、AutoML相关算法研究,有丰富的CV/NLP模型研发以及模型蒸馏、裁剪领域的相关研究经验。
推荐阅读
2种方式!带你快速实现前端截图
C++反射:深入探究function实现机制!
C++反射:全面解读property的实现机制!
C++反射:深入浅出剖析ponder库实现机制!
