基于Spark的电影推荐系统实现
基于Spark的电影推荐系统实现
- 一、业务场景
- 二、数据集说明
- 三、操作步骤
-
- 阶段一、启动HDFS、Spark集群服务和zeppelin服务器
- 阶段二、准备案例中用到的数据集
- 阶段三、对数据集进行探索和分析
未经许可,禁止以任何形式转载,若要引用,请标注链接地址
全文共计7821字,阅读大概需要3分钟
一、业务场景
受某视频网站委托,需开发一套基于Spark的大数据机器学习系统,应用协同过滤算法对网站客户进行电影推荐。
二、数据集说明
本案例所使用的数据集说明如下:
评分数据集:/data/dataset/ml/movielens/ratings.csv
电影数据集:/data/dataset/ml/movielens/movies.csv
三、操作步骤
阶段一、启动HDFS、Spark集群服务和zeppelin服务器
1、启动HDFS集群
在Linux终端窗口下,输入以下命令,启动HDFS集群:
1. $ start-dfs.sh
2、启动Spark集群
在Linux终端窗口下,输入以下命令,启动Spark集群:
1. $ cd /opt/spark
2. $ ./sbin/start-all.sh
3、启动zeppelin服务器
在Linux终端窗口下,输入以下命令,启动zeppelin服务器:
1. $ zeppelin-daemon.sh start
4、验证以上进程是否已启动
在Linux终端窗口下,输入以下命令,查看启动的服务进程:
1. $ jps
如果显示以下6个进程,则说明各项服务启动正常,可以继续下一阶段。
1. 2288 NameNode
2. 2402 DataNode
3. 2603 SecondaryNameNode
4. 2769 Master
5. 2891 Worker
6. 2984 ZeppelinServer
阶段二、准备案例中用到的数据集
1、将本案例要用到的数据集上传到HDFS文件系统的”/data/dataset/ml/“目录下。在Linux终端窗口下,输入以下命令:
1. $ hdfs dfs -mkdir -p /data/dataset/ml
2. $ hdfs dfs -put /data/dataset/ml/movielens /data/dataset/ml/
2、在Linux终端窗口下,输入以下命令,查看HDFS上是否已经上传了该数据集:
1. $ hdfs dfs -ls /data/dataset/ml/movielens
这时应该看到movielens目录及其中的训练数据集已经上传到了HDFS的”/data/dataset/ml/“目录下。
阶段三、对数据集进行探索和分析
1、新建一个zeppelin notebook文件,并命名为movie_project。
2、先导入案例中要用到的机器学习库。在notebook单元格中,输入以下代码:
1. // 导入相关的包
2. import org.apache.spark.mllib.evaluation.RankingMetrics
3. import org.apache.spark.ml.evaluation.RegressionEvaluator
4. import org.apache.spark.ml.recommendation.ALS
5. import org.apache.spark.ml.tuning.{ParamGridBuilder, CrossValidator}
6. import org.apache.spark.sql.functions._
7. import org.apache.spark.sql.types._
8. import spark.implicits._
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:
import org.apache.spark.mllib.evaluation.RankingMetrics
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.ml.recommendation.ALS
import org.apache.spark.ml.tuning.{ParamGridBuilder, CrossValidator}
import org.apache.spark.sql.functions.
import org.apache.spark.sql.types.
import spark.implicits._
3、加载数据集。在notebook单元格中,输入以下代码:
1. // 加载数据。因为不需要timestamp列,因此立即删除它
2. val file = "hdfs://localhost:9000/data/dataset/ml/movielens/ratings.csv"
3.
4. val ratingsDF1 = spark.read.option("header", "true").
5. option("inferSchema", "true").
6. csv(file).
7. drop("timestamp")
8.
9. ratingsDF1.count
10. ratingsDF1.printSchema
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:
file: String = /data/spark_demo/movielens/ratings.csv
ratingsDF1: org.apache.spark.sql.DataFrame = [userId: int, movieId: int … 1 more field]
res97: Long = 100836
root
|— userId: integer (nullable = true)
|— movieId: integer (nullable = true)
|— rating: double (nullable = true)
由以上输出内容可以看出,该数据集共有3个字段,分别是用户id、电影id和该用户对该电影的评分。
4、查看前5条数据。在notebook单元格中,输入以下代码:
1. ratingsDF1.show(5)
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:
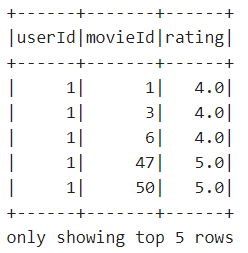
5、对数据进行简单统计。在notebook单元格中,输入以下代码:
1. // 看看被评分的电影总共有多少部:
2. ratingsDF1.select("movieId").distinct().count
3.
4. // 看看有多少用户参与评分:
5. ratingsDF1.select("userId").distinct().count
同时按下Shift+Enter键,执行以上代码,输出内容如下:
Long = 9724
Long = 610
由以上输出内容可以看出,该评分数据集中,参与的用户有610名,被评论的电影有9724部。
6、快速检查谁是活跃的电影评分者。在notebook单元格中,输入以下代码:
1. // 快速检查谁是活跃的电影评分者
2. val ratingsByUserDF = ratingsDF1.groupBy("userId").count()
3. ratingsByUserDF.orderBy($"count".desc).show(10)
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:

由以上输出内容可以看出,参与度最高用的用户其id是414。
7、分析每部电影的最大评分数量。在notebook单元格中,输入以下代码:
1. // 分析每部电影的最大评分数量
2. val ratingsByMovieDF = ratingsDF1.groupBy("movieId").count()
3. ratingsByMovieDF.orderBy($"count".desc).show(10)
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:

由以上输出内容可以看出,评价数超过300的电影有三部,其中评价数最多的电影其id是356。
8、数据拆分,将原始数据集拆分为训练集和测试集,其中训练集占80%,测试集占20%。在notebook单元格中,输入以下代码:
1. // 为训练和测试准备数据
2. val Array(trainingData, testData) = ratingsDF1.randomSplit(Array(0.8, 0.2))
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:
trainingData: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [userId: int, movieId: int … 1 more field]
testData: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [userId: int, movieId: int … 1 more field]
9、Spark实现了ALS算法(Alternating Least Square),这一步建立ALS的实例。在notebook单元格中,输入以下代码:
1. // 建立ALS的实例
2. val als = new ALS().setRank(12).
3. setMaxIter(10).
4. setRegParam(0.03).
5. setUserCol("userId").
6. setItemCol("movieId").
7. setRatingCol("rating")
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:
als: org.apache.spark.ml.recommendation.ALS = als_10a2c5c69e40
10、训练模型,并设置模型的冷启动策略。在notebook单元格中,输入以下代码:
1. // 训练模型
2. val model = als.fit(trainingData)
3.
4. // 从Spark 2.2.0开始,可以将coldStartStrategy参数设置为drop,以便删除包含NaN值的预测的DataFrame中的任何行。
5. // 然后将在非nan数据上计算评估度量,该度量将是有效的。
6. model.setColdStartStrategy("drop")
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:
model: org.apache.spark.ml.recommendation.ALSModel = als_10a2c5c69e40
res169: model.type = als_10a2c5c69e40
11、执行预测,并查看预测结果。在notebook单元格中,输入以下代码:
1. // 执行预测
2. val predictions = model.transform(testData)
3.
4. // 查看预测结果
5. predictions.sort("userId").show(10)
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:
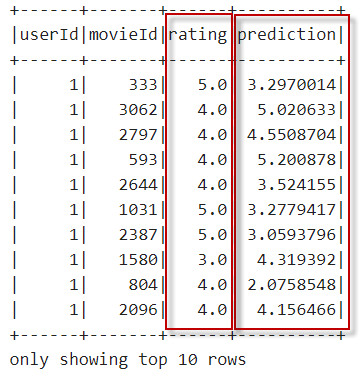
由以上输出内容可以看出,rating列为标签列,prediction为预测结果列。
12、有的预测值为NaN(非数字),这会影响到rmse的计算,因些需要先删除结果集中的NaN值。在notebook单元格中,输入以下代码:
1. val predictions_dropNaN = predictions.na.drop(Array("prediction"))
2. predictions_dropNaN.count
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:
predictions_dropNaN: org.apache.spark.sql.DataFrame = [userId: int, movieId: int … 2 more fields]
res178: Long = 19333
由以上输出内容可以看出,删除prediction列具有NaN值的记录以后,结果集中还有19333条记录。
13、设置一个评估器(evaluator)来计算RMSE度量指标。在notebook单元格中,输入以下代码:
1. // 设置一个评估器(evaluator)来计算RMSE度量指标
2. val evaluator = new RegressionEvaluator().setMetricName("rmse").
3. setLabelCol("rating").
4. setPredictionCol("prediction")
5.
6. val rmse = evaluator.evaluate(predictions_dropNaN)
7. println(s"Root-mean-square error = ${rmse}")
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:
evaluator: org.apache.spark.ml.evaluation.RegressionEvaluator = regEval_7943cc497104
rmse: Double = 1.017470307395966
Root-mean-square error = 1.017470307395966
由以上输出内容可以看出,根均方差(rmse)值为
1.017470307395966
14、使用ALSModel来执行推荐。在notebook单元格中,输入以下代码:
1. // 为所有用户推荐排名前五的电影
2. model.recommendForAllUsers(5).show(false)
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:

15、为每部电影推荐top 3个用户。在notebook单元格中,输入以下代码:
1. // 为每部电影推荐top 3个用户
2. val recMovies = model.recommendForAllItems(3)
3. recMovies.show(5,false)
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:

由以上输出内容可以看出,为每部电影推荐前3个用户。但是不好的一点是,我们只能看到电影的id,而不是电影的名称。
16、读取电影数据集,这样就能看到电影标题了。在notebook单元格中,输入以下代码:
1. // 读取电影数据集,这样就能看到电影标题了
2. val moviesFile = "hdfs://localhost:9000/data/dataset/ml/movielens/movies.csv"
3. val moviesDF = spark.read.option("header", "true").option("inferSchema", "true").csv(moviesFile)
4.
5. val recMoviesWithInfoDF = recMovies.join(moviesDF, "movieId")
6. recMoviesWithInfoDF.select("movieId", "title", "recommendations").show(5, false)
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:

由以上输出内容可以看出,现在每部电影的id和名称都是可见的了。
17、使用CrossValidator对ALS模型进行调优。在notebook单元格中,输入以下代码:
1. // 使用CrossValidator对ALS模型进行调优
2. val paramGrid = new ParamGridBuilder()
3. .addGrid(als.regParam, Array(0.05, 0.15))
4. .addGrid(als.rank, Array(12,20))
5. .build
6.
7. val crossValidator=new CrossValidator()
8. .setEstimator(als)
9. .setEvaluator(evaluator)
10. .setEstimatorParamMaps(paramGrid)
11. .setNumFolds(3)
12.
13. // 打印出4个超参数组合
14. crossValidator.getEstimatorParamMaps.foreach(println)
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:
paramGrid: Array[org.apache.spark.ml.param.ParamMap] =
Array({
als_10a2c5c69e40-rank: 12,
als_10a2c5c69e40-regParam: 0.05
}, {
als_10a2c5c69e40-rank: 20,
als_10a2c5c69e40-regParam: 0.05
}, {
als_10a2c5c69e40-rank: 12,
als_10a2c5c69e40-regParam: 0.15
}, {
als_10a2c5c69e40-rank: 20,
als_10a2c5c69e40-regParam: 0.15
})
crossValidator: org.apache.spark.ml.tuning.CrossValidator = cv_efc8cf15a3ab
{
als_10a2c5c69e40-rank: 12,
als_10a2c5c69e40-regParam: 0.05
}
{
als_10a2c5c69e40-rank: 20,
als_10a2c5c69e40-regParam: 0.05
}
{
als_10a2c5c69e40-rank: 12,
als_10a2c5c69e40-regParam: 0.15
}
{
als_10a2c5c69e40-rank: 20,
als_10a2c5c69e40-regParam: 0.15
}
由以上输出内容可以看出,共打印了四组参数组合。
18、使用找到的最优模型来再次进行预测,并对预测结果进行评估。在notebook单元格中,输入以下代码:
1. //这需要一段时间才能完成超过10个实验
2. val cvModel = crossValidator.fit(trainingData)
3.
4. // 执行预测并删除空值
5. val predictions2 = cvModel.transform(testData).na.drop
6.
7. val evaluator2 = new RegressionEvaluator()
8. .setMetricName("rmse")
9. .setLabelCol("rating")
10. .setPredictionCol("prediction")
11.
12. val rmse2 = evaluator2.evaluate(predictions2)
同时按下【Shift+Enter】键,执行以上代码,输出内容如下:
cvModel: org.apache.spark.ml.tuning.CrossValidatorModel = cv_efc8cf15a3ab
predictions2: org.apache.spark.sql.DataFrame = [userId: int, movieId: int … 2 more fields]
evaluator2: org.apache.spark.ml.evaluation.RegressionEvaluator = regEval_4dd08e13c0e9
rmse2: Double = 0.9471342462991672
由以上输出内容可以看出,rmse2的值要低于rmse1,预测结果相比之前更加准确。