各大论文数据集详解
数据集列表
- MSR-VTT
- TRECVID AVS 2016-2018
- VATEX
- MPII Movie Description Dataset (MPII-MD)
- MS-COCO
- Flickr30k
- MSVD
- TGIF
- ActivityNet Captions
- LSMDC
MSR-VTT
论文名称 : MSR-VTT: A Large Video Description Dataset for Bridging Video and Language
这是一个新的大型视频理解基准,特别是视频文本翻译的新兴任务。
这是通过从一个商业视频搜索引擎收集257个热门查询来实现的,每个查询包含118个视频。在目前的版本中,MSR-VTT提供了10K个网络视频片段,总计41.2小时,200K个片段-句子对,涵盖了最全面的类别和多样化的视觉内容,代表了最大的句子和词汇数据集。每一段视频都由1327名AMT工作人员用大约20句自然的句子进行了注释。
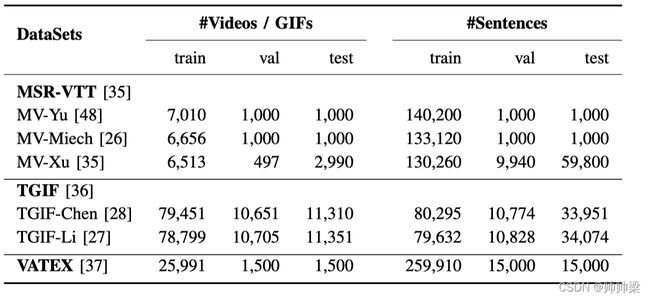
1.官方分区使用6513个剪辑进行训练,497个剪辑用于验证,其余2990个剪辑用于测试。
2.对于的划分,有6656个剪辑用于训练,1000个剪辑用于测试。
3.分区分别使用7010和1000个剪辑进行训练和测试。由于最后两个数据分区没有提供验证集,我们通过从MSR-VTT中随机抽取1000个片段来构建一个验证集。
视频简介:
MSR-VTT dataset: 该数据集为ACM Multimedia 2016 的 Microsoft Research - Video to Text (MSR-VTT) Challenge。地址为 : MSR-VTT dataset. 。该数据集包含10000个视频片段(video clip),被分为训练,验证和测试集三部分。每个视频片段都被标注了大概20条英文句子。此外,MSR-VTT还提供了每个视频的类别信息(共计20类),这个类别信息算是先验的,在测试集中也是已知的。同时,视频都是包含音频信息的。该数据库共计使用了四种机器翻译的评价指标,分别为:METEOR, BLEU@1-4,ROUGE-L,CIDEr。

首先,我们的数据集拥有最多的剪辑-句子对,其中每个视频剪辑都有多个句子注释。这可以更好地训练rnn,从而生成更自然、更多样化的句子。其次,我们的数据集包含了最全面但最具代表性的视频内容,收集了257个热门视频查询在20个代表性类别(包括烹饪和电影)从一个真实的视频搜索引擎。这将有利于验证视频到语言的任何方法的泛化能力。第三,我们数据集中的视频内容比任何现有的数据集都要复杂,因为这些视频是从Web上收集的。这对这个特定的研究领域来说是一个基本的挑战。最后,除了视频内容,我们为每个剪辑保留音频通道,这为相关领域打开了一扇门。图1展示了视频的一些例子和注释句子。
分类:
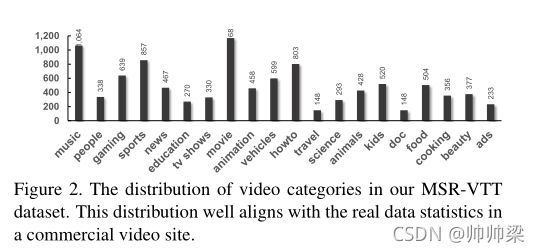
分割
为了将数据集分割为训练集、验证集和测试集,我们根据相应的搜索查询对视频片段进行分离。来自相同视频或相同查询的剪辑将不会单独出现在训练或测试集中,以避免过度拟合。我们将数据按照65%:30%:5%进行分割,分别对应训练集、测试集和验证集中的6,513个、2,990个和497个剪辑。
MSR-VTT源自各种各样的视频类别(来自20个一般领域/类别的7180个视频),
由于MSR-VTT拥有最大的词汇量,每个剪辑注释了20个不同的句子
TRECVID AVS 2016-2018
任务 - 临时视频搜索(AVS)
IACC.3 数据集
IACC.3 数据集是大约 4600 个互联网档案视频(144 GB,600 小时),具有 MPEG-4/H.264 格式的知识共享许可,持续时间从 6.5 分钟到 9.5 分钟不等,平均持续时间接近 7.8 分钟。大多数视频都有一些由捐赠者提供的可用元数据,例如标题、关键字和描述。
没训练数据,所以使用MSR-VTT和TGIF的联合集合训练
VATEX
论文名称:VATEX: A Large-Scale, High-Quality Multilingual Dataset
for Video-and-Language Research
用于视频和语言研究的大规模、高质量多语言数据集
其中包含超过41,250个视频和825,000个中英文字幕。在字幕中,有超过20.6万对英汉平行翻译。
我们采用25991个用于培训的视频剪辑、1500个用于验证的视频剪辑和1500个用于测试的视频剪辑,其中验证和测试集是通过将3000个剪辑的官方验证集随机分成两个相等的部分获得的。
多语言视频字幕

大型多语言视频和语言研究数据集VATEX,其中包含超过41250个独特的视频和825000个高质量字幕。它涵盖了600个人类活动和各种视频内容。每个视频配有来自20名个人标注者的10个英文和10个中文不同字幕。
- 它包含了英语和汉语的大规模描述,可以支持许多受单语言数据集限制的多语言研究。
- 其次,VATEX拥有最多的剪辑句对,每个视频片段都有多个独特的句子注释,每个标题在整个语料库中都是唯一的。
- 第三,VATEX的视频内容更全面、更有代表性,共涵盖600个人类活动。

VATEX数据集的一个示例。该视频有10个英文和10个中文描述。所有这些都描述了同一段视频,因此它们彼此之间是远平行的,而最后5个则是成对的翻译。
大概是这样的
MPII Movie Description Dataset (MPII-MD)
MPII-MD包含从94部好莱坞电影中提取的约68000个视频剪辑。每个剪辑都附带一个句子描述,该描述来源于电影脚本和音频描述(AD)数据。广告或描述性视频服务(DVS)是添加到电影中的附加音频曲目,用于为视力受损者描述电影中明确的视觉元素。尽管电影片段是手动与描述对齐的,但由于视觉和文本内容的高度多样性,以及大多数片段只有一个引用语句,因此数据非常具有挑战性。我们使用作者提供的训练/验证/测试分割,每五帧提取一次(视频比MSVD短,平均94帧)。
我们使用官方数据分区,即56828、4929和6580个电影剪辑,分别用于培训、评估和测试。每个电影剪辑都与一个或两个文本描述相关联。

MS-COCO
MS-COCO包含123287张图片,每张图片用五句话描述。我们采用其标准拆分为[2],[9],使用113287张图像进行训练,5000张图像进行验证,其余5000张图像进行测试。通过对1000张测试图像进行5倍以上的平均或对5000张测试图像进行测试,报告最终结果。
: COCO2017 数据集分类统计.
: coco2017数据集80类别名称与id号的对应关系.
: COCO2017数据集结构说明.
Flickr30k
Flickr30k收集31000张图像,每张图像有5个文本注释。我们采用其标准分割为,29000张图像用于训练,1000张图像用于验证,1000张图像用于测试。
flickr30k数据集是什么
这个数据集的核心就两点,一是图像,二是图像对应的描述语言。
先上图:
在token文件中的标注信息:
667626.jpg#0 A girl wearing a red and multicolored bikini is laying on her back in shallow water .
667626.jpg#1 Girl wearing a bikini lying on her back in a shallow pool of clear blue water .
667626.jpg#2 A young girl is lying in the sand , while ocean water is surrounding her .
667626.jpg#3 A little girl in a red swimsuit is laying on her back in shallow water .
667626.jpg#4 A girl is stretched out in shallow water
可以看到,每副图像都搭配有5句描述,五句描述语言的的意思基本都差不多。
我们的目标是训练出一个模型,需要达到的效果是:将一张图像放进去,出来一句对应的还算正确的图像描述,俗话说的看图说话。
一张图像,对应5条描述语言,一共有158915条语言描述。
MSVD
Youtube2Text (MSVD)
MSVD包含1970个视频,每个视频剪辑包含40个句子。我们使用标准拆分,1200个视频用于培训,100个视频用于验证,670个视频用于测试。
- 这个数据集包含 1970个短视频,10-25s,平均时长为9s,视频包含不同的人,动物,动作,场景等。
- 每个视频由不同的人标注了多个句子,大约41 annotated sentences per clip,共有 80839 个sentences,平均每个句子有8个words,这些所有的句子中共包含近16000个 unique words。
- caption中包括多国的语言进行描述,部分论文中采取只选用laguage = english 的caption 进行训练和测试


TGIF
Tumblr GIF(TGIF)数据集包含100K个GIF动态图和120K条描述GIF视觉内容的句子。
TGIF包含gif格式的视频,79451个用于培训的视频剪辑,10651个用于验证的视频剪辑,其余11310个用于测试的视频剪辑。
例子:
一个男人怒目而视,一个戴墨镜的人出现了。
一只猫试图在平板电脑上抓老鼠
一个穿着红色衣服的男人正在跳舞
一只动物在丛林中靠近另一只
一个戴帽子的男人调整领带,做了一张奇怪的脸。
有人把一只猫放在包装纸上,然后把它包起来戴上蝴蝶结
一个黑发女人正在看着这个男人
一个骑自行车的人正在跳过栅栏
一群男人站着盯着同一个方向。
a boy is happy parking and see another boy
原文出处
ActivityNet Captions
ActivityNet Captions数据库由20000个视频组成。每个视频都有多个句子描述的密集注释。
ActivityNet Captions数据库将视频和一系列时序标注的语句联系在一起。每个语句覆盖了视频的某一特定片段,描述了出现的事件。这些事件持续的时间或长或短,对事件本身也没有限制,并且可以同时出现。ActivityNet Captions包含20000个视频,每个视频平均含有3.65个时序定位的描述语句,一共有100000条描述。我们发现每个视频的语句数量相对服从正态分布。除此之外,随着视频的持续时间增加,描述语句的数量也在增加。句子的平均长度为13.48个词,也符合正态分布。平均每个句子描述了36秒的事件,大约是相应视频的31%的内容。然而每个视频的完整语句描述了大概视频94.6%的内容,这一点说明每一段标注基本都能覆盖视频内的主要活动。我们还发现描述内容有10%的重叠,说明同时出现的事件会互相覆盖。
长这样:

视频论文介绍网站
LSMDC
由118081个短片组成。这些视频摘自202部长篇电影。
-----------------------------出处---------------------------