Seq2Seq详解
文章目录
- 10. Seq2Seq
-
- 10.1 Baseline Seq2Seq 架构
-
- 10.1.1 技术架构
-
- 10.1.1.1 第一步:Tokenization & Build Dictionary
- 10.1.1.2 第二步:Word Emebedding
- 10.1.1.3 第三步:Training Seq2Seq Model
- 10.1.1.4 第四步:Inference Using the Seq2Seq Model
- 10.1.2 模型优缺点
- 10.1.3 优化
-
- 10.1.3.1 Encoder 变成 双向
- 10.1.3.2 Word-level 词向量
- 10.1.3.3 多任务学习
- 10.1.3.4 Attention(最有效)
- 10.2 Seq2Seq + Attention
-
- 10.2.1 技术架构
-
- 10.2.1.1 第一步:得到 Encoder 的最后一个输出
- 10.2.1.2 第二步:计算权重 α i \alpha_i αi
-
- 10.2.1.2.1 Attention 计算方法一:Bahdanau Attention
- 10.2.1.2.2 Attention 计算方法二:Transformer Attention
- 10.2.1.3 第三步:计算 Context Vector: c c c
- 10.2.1.4 时间复杂度
- 10.2.1.5 Weights Visualization
- 10.2.1.6 Summary
10. Seq2Seq
10.1 Baseline Seq2Seq 架构
10.1.1 技术架构
10.1.1.1 第一步:Tokenization & Build Dictionary

10.1.1.2 第二步:Word Emebedding
这里以 One-hot Encoding 为例。分别对两种语言进行 Encoding。
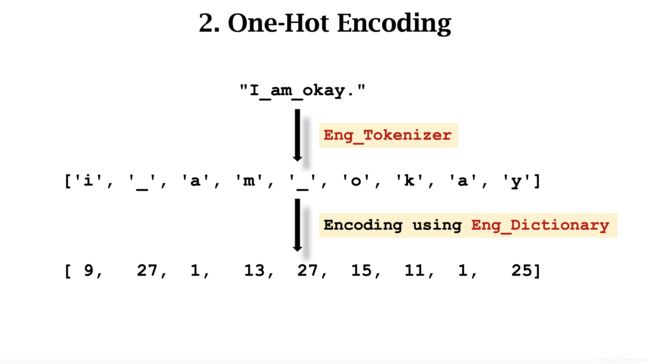
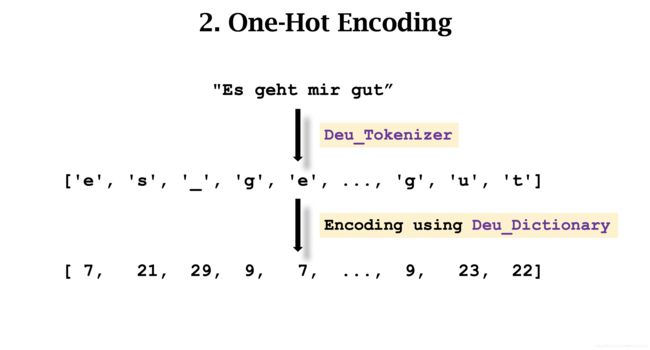
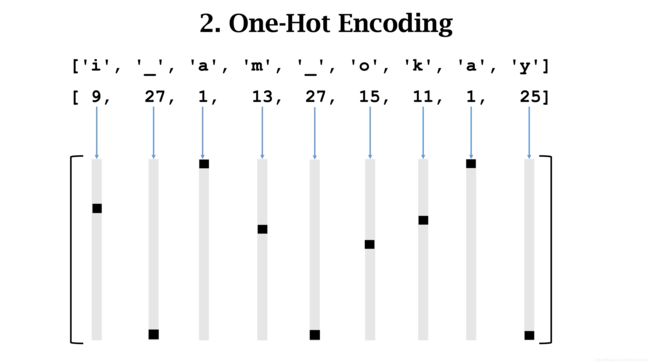
每个词汇对应一个列向量。输入的句子变成一个矩阵。
10.1.1.3 第三步:Training Seq2Seq Model
Encoder 部分只保留最后一个 State。
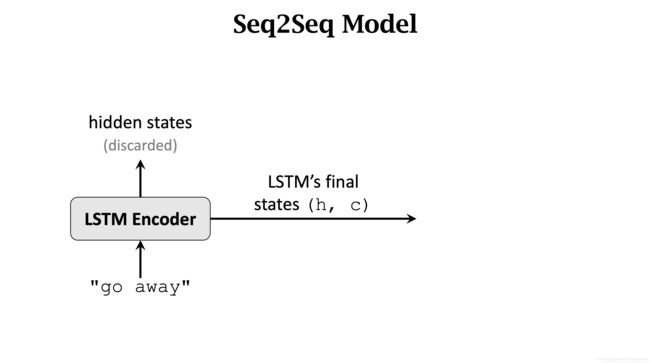
将这个 State 作为 Decoder 的第一个输入。Decoder 第一个输入还有 开始标记 [start]。之后 Decoder 会预测出一个概率分布 p。
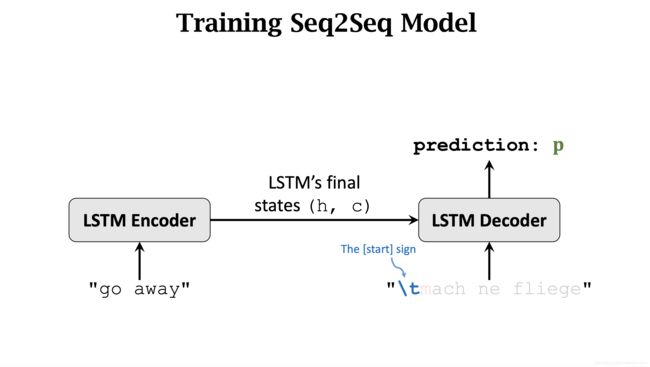
[start] 标记的下一个字符 m 被当成 Label y。使用 CrossEntropy 最小化 loss。并使用反向传播更新 Decoder 和 Encoder 的网络参数。
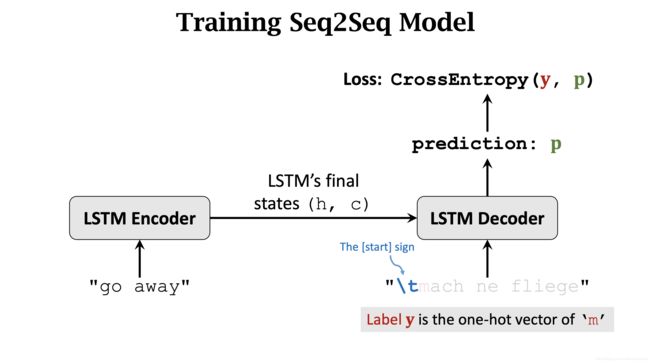
Decoder 的下一个输入是 \t和m. 此时,Label y 是 a.

Decoder 的第三次输入是 \t、m、a. Label y 是 c.
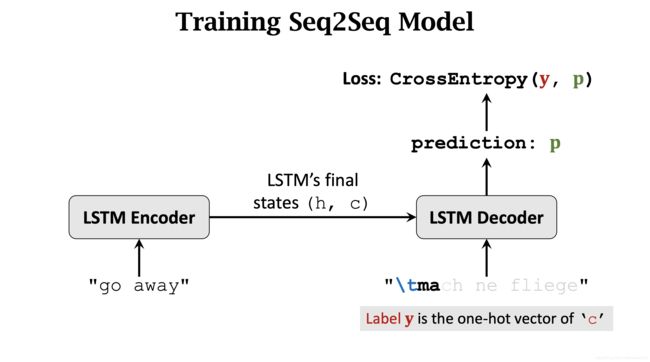
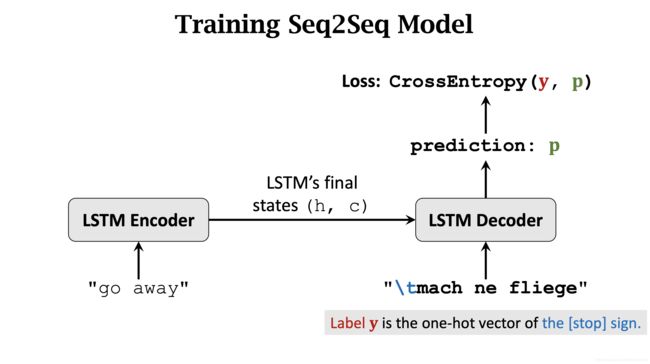
重复这个过程,当整个德语句子输入完时,Label y 是 停止标记 [stop]。
10.1.1.4 第四步:Inference Using the Seq2Seq Model
输入要翻译句子的 Matrix. 保留最后一个输出 State。
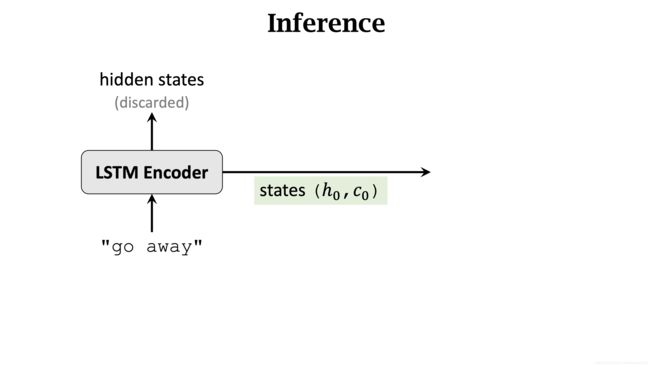
Encoder 的最后一个输出 State 和 [start] 标记被传入到 Decoder 中。

记录 Decoder 的输出 State( h 1 h_1 h1, c 1 c_1 c1) 和 m. 并将她们当作是 Decoder 的下一次输入。


记录 Decoder 第二次的输出 State(h_2$, c 2 c_2 c2) 和 a.
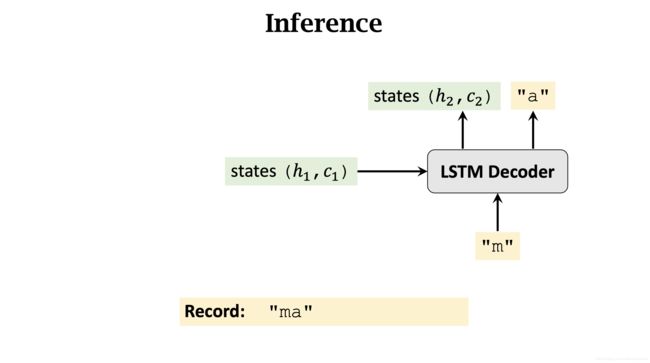
注意, Decoder 第三次的输入 不是 ma,而是 a。这和训练时不一样。 同样,作为输入的还有上一步输出的 State ( h 2 h_2 h2, c 2 c_2 c2)。
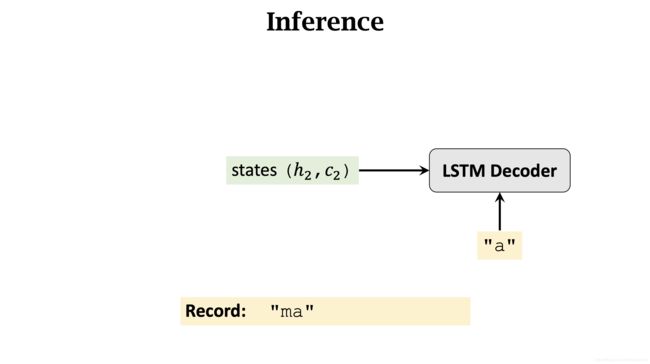
同理,Decoder 的每一次输入都是上一步的输出,而不是当前Decoder的所有输出 y ^ \hat y y^

重复这个过程,直到最终输出 [stop] 标记。
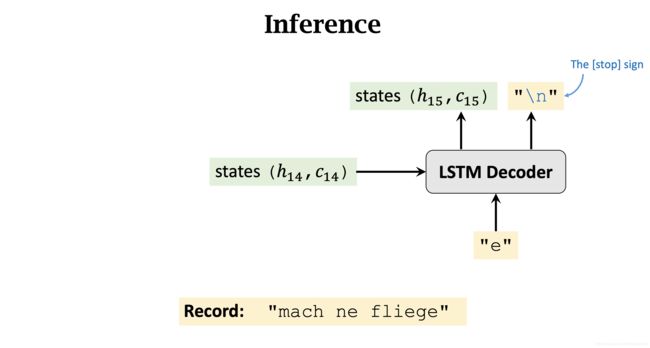
返回 Decoder的所有输出 y ^ \hat y y^。即:mach ne fliege。

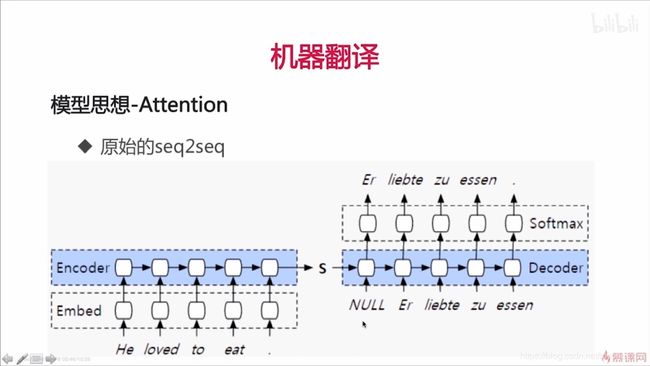
10.1.2 模型优缺点
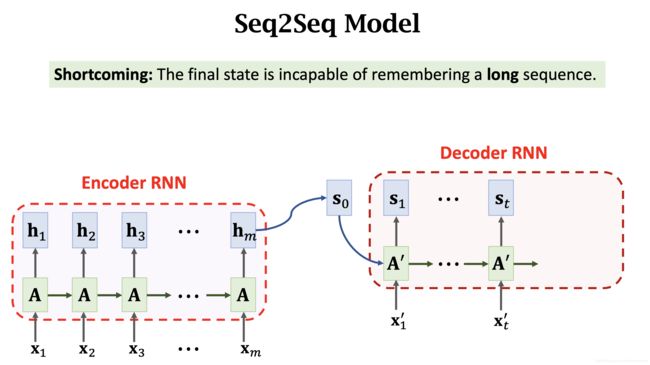
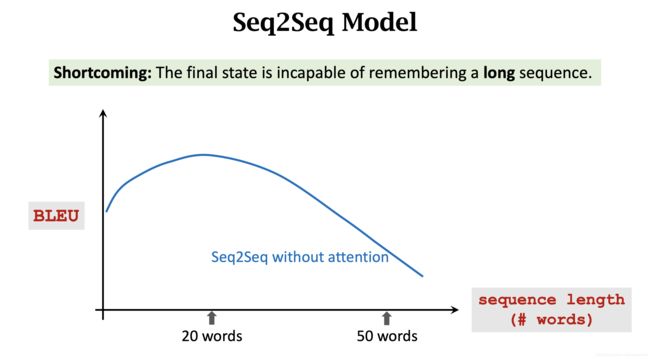
在机器翻译任务中,使用 Seq2Seq 模型,BLEU 指标随句子长度增长逐渐降低。

10.1.3 优化
10.1.3.1 Encoder 变成 双向
Use Bi-LSTM in the encoder; use unidirectional LSTM in the decoder.

10.1.3.2 Word-level 词向量

10.1.3.3 多任务学习
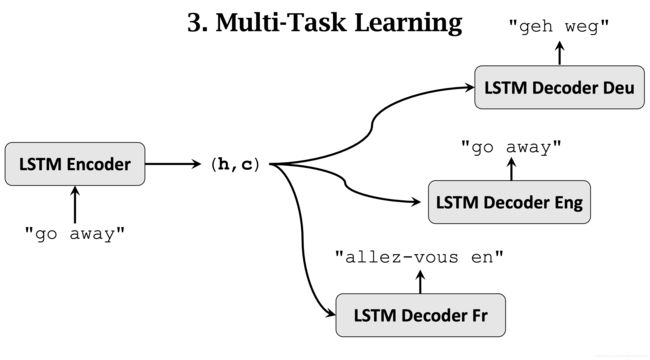
10.1.3.4 Attention(最有效)
Attention 机制优化。下一节详细讲解。
10.2 Seq2Seq + Attention

10.2.1 技术架构
这里为了方便理解,使用了 SimpleRNN,而不是上面的LSTM。重点在于理解这个过程。触类旁通。
10.2.1.1 第一步:得到 Encoder 的最后一个输出
Decoder 的第一步中, s 0 s_0 s0 就是 Encoder 的最后一个输出 h m h_m hm。
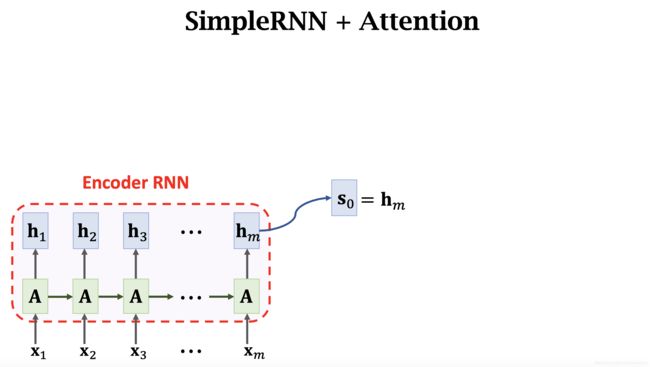
10.2.1.2 第二步:计算权重 α i \alpha_i αi
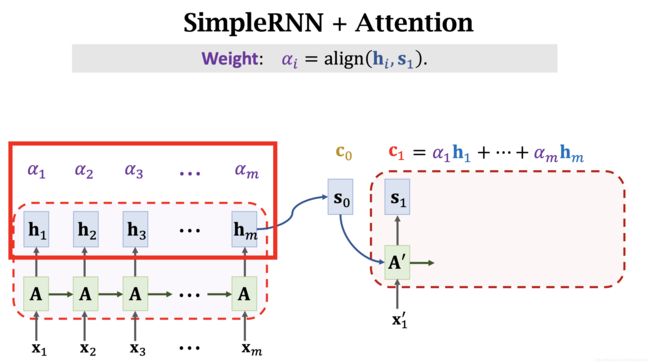
使用 Attention 机制计算 s 0 s_0 s0 与 Encoder 中每一步产生的 h i h_i hi 计算得到c权重 α i \alpha_i αi. 所有 α \alpha α 加和 等于 1.

10.2.1.2.1 Attention 计算方法一:Bahdanau Attention
计算权重 α i \alpha_i αi 的方法有很多。常用的有两种。第一种是cBahdanau,也就是 Attention 开山鼻祖论文中的方法:

10.2.1.2.2 Attention 计算方法二:Transformer Attention
第二种方法分别使用了两个矩阵。和 Transformer 中一样。

10.2.1.3 第三步:计算 Context Vector: c c c
在上一小节中,我们讲了两种计算 Attention 的方法,这里我们不讨论如何得到 α i \alpha_i αi 的细节。无论选择哪一种,都会得到 α i \alpha_i αi。我们假设现在已经得到了 α i \alpha_i αi 。
注意:这里我们屏蔽了计算 α i \alpha_i αi 的细节,本节仅给大家展示 SimpleRNN 与 Attention 如何结合的。在 Transformer 章节中,我们会将计算 α i \alpha_i αi 的过程引入进来。在本节中引入,大家可能很难理解。本章节先整体理解,后续章节再细节理解。
将 α i \alpha_i αi 和 h i h_i hi 对应相乘,得到 c 0 c_0 c0

将 s 0 s_0 s0, c 0 c_0 c0, x 1 ′ x_1^{\prime} x1′ 传入 decoder 得到 输出 s 1 s_1 s1。
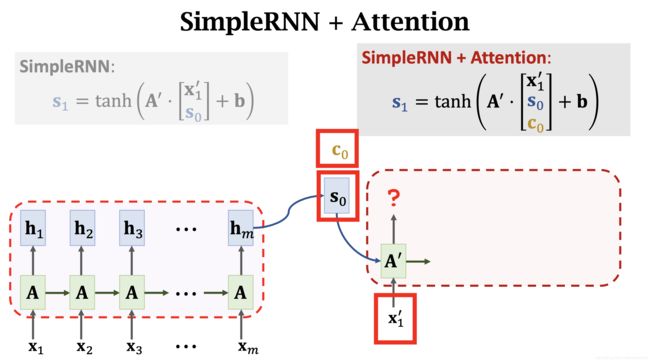
同样, s 1 s_1 s1 与 Encoder 中的每个 h h h 计算得到 α i \alpha_i αi。注意,这里的 α i \alpha_i αi 和 s 0 s_0 s0 时计算的不是一个 α \alpha α。不可以复用权重 α \alpha α。对于每一个新的 s i s_i si,都需要重新计算一遍 α \alpha α。最后得到 c 2 c_2 c2.
将 s 1 s_1 s1, c 1 c_1 c1, x 2 ′ x_2^{\prime} x2′ 传入 decoder 得到 输出 s 2 s_2 s2。
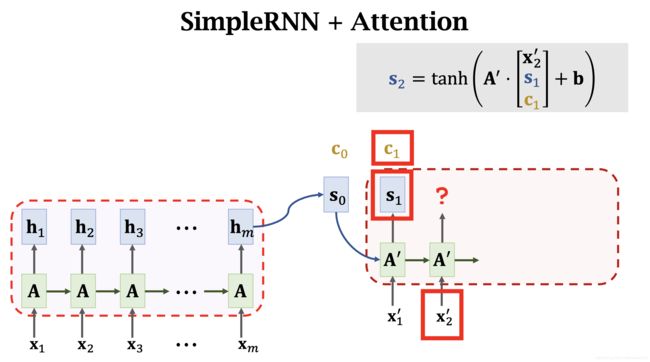
重复上面的过程。
10.2.1.4 时间复杂度

10.2.1.5 Weights Visualization

10.2.1.6 Summary

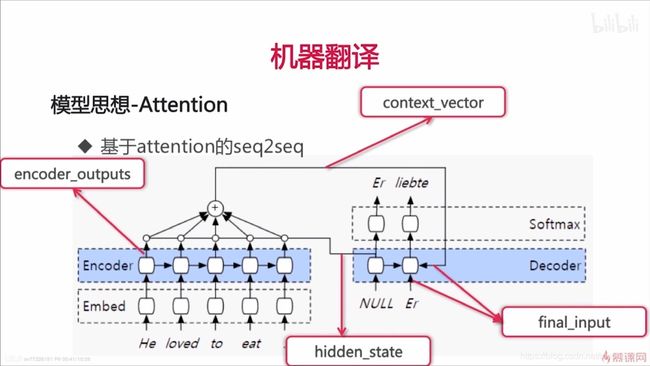
上图中,五个 encoder 单元都会输出 encoder_outputs,所以上面 encoder_outputs 其实有五条线。为了美观,只画了一条线。
- Encoder 产出:encoder outputs 和 hidden state;
- hidden_state 和 encoder_outputs 计算得到 attention weights;
- attention weights 和 encoder outputs 加权求和 得到 context_vector;
- context_vector 和 下一个 input 一起输入给 decoder,计算得到一个输出 和一个 hidden_state。这个输出会当做下一次 decoder 计算的输入。第一个输入是 NULL 标记。这些输出就是 final_input。
具体计算过程:

注意:score 计算时,H 是某一步的,而EO是encoder的多步的,大家可能会有一个疑问,两者维度会不对应。在 TensorFlow 中,如果出现维度不对应,H会被拷贝多份,和 EO 长度一样,分别和 EO 中的每个向量进行加法。