语言模型常用评价方法:perplexity、bleu
目录
1. perplexity(困惑度、复杂度)
2. BLEU
代码实现
1. perplexity(困惑度、复杂度)
更多详细,参考:详解语言模型NGram及困惑度Perplexity
语言模型:语言模型可以表示为一个计算
的模型,语言模型仅仅对句子出现的概率进行建模 , 并不尝试去“理解”句子的内容含义。对于自然语言相关的问题,比如机器翻译,最重要的问题就是文本的序列不是符合我们人类的使用习惯,语言模型就是用于评估文本序列符合人类语言使用习惯程度的模型。
语言模型效果好坏的常用评价指标是perplexity,简单说,perplexity值刻画的是语言模型预测一个语言样本的能力。在一个测试集上得到的perplexity值越低,说明建模效果越好。计算公式如下:
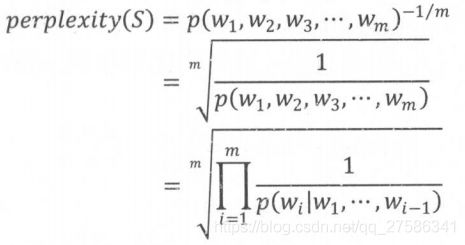
其中, 为句子的长度
为句子的长度
在语言模型的训练中,通常使用perplexity的对数形式:将每个位置上的概率取对数再平均
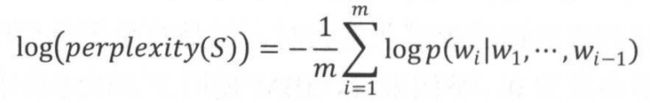
对数使用加法的形式,可以加速计算,同时避免概率乘积数值过小导致浮点数向下溢出的问题。
(1)直观上理解,从以上定义公式可以看出:
- perplexity:实际是计算每一个单词得到的概率倒数的几何平均,因此perplexity可以理解为平均分支系数,即模型预测下一个词时的平均可选择数量。
- 如在PTB数据集上,某个语言模型perplexity=47.7,表明平均情况下,该模型预测下一个词时有47.7个词等可能地可以作为下一个词的合理选择。
(2)在数学上, log perplexity可以看成真实分布与预测分布之间的交叉熵,即真实分布与预测分布之间的距离。
交叉熵:描述了两个概率分布之间的一种距离,假设x是一个离散变量,
与
是与x相关的概率分布,则二者之间交叉熵的定义是在分布
下
的期望值:
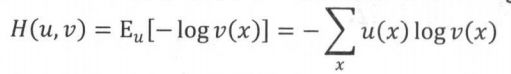
把x看成单词,为每个位置上单词的真实分布,![]() 为模型的预测分布
为模型的预测分布![]() ,就可看出 log perplexity和交叉熵是等价的。 区别在于,由于语言的真实分布是未知的,真实分布用测试语料的取样代替,即认为在给定上文的条件下,语料中出现单词
,就可看出 log perplexity和交叉熵是等价的。 区别在于,由于语言的真实分布是未知的,真实分布用测试语料的取样代替,即认为在给定上文的条件下,语料中出现单词![]() 的概率为1,出现其他单词的概率为0:
的概率为1,出现其他单词的概率为0:

(3)在神经网络中,![]() 分布通常是由一个softmax层产生的,Tensorflow中提供了两个方便计算交叉熵的函数:
分布通常是由一个softmax层产生的,Tensorflow中提供了两个方便计算交叉熵的函数:
- tf.nn.softmax_cross_entropy_with_logits
- tf.nn.sparse_softmax_cross_entropy_with_logits
(4)常见模型的困惑度
深度学习之前,传统的基于统计算法的语言模型,在测试时困惑度大多都在 80以上 (人工语言处理的困惑度的理论最低点大约在 10-20 之间).一方面是算法的局限,另一方面是来自培训语句数量规模的限制.
2013年,以 Ciprian Chelba 为首的来自谷歌的团队推出了一个叫做"十亿单词基准"(One Billion Word Benchmark) 的语料库.这个语料库包含了接近十亿个英文单词组成的不同语句, 用来培训和测试不同的算法模型. 这个数据规模, 是先前流行的所谓 "Penn Treebank" 的包含四百五十万英文单词的语料库的大约两百倍。Chelba 的团队, 使用一个包含二百亿个自由参数的循环神经网络的模型, 模型的训练消耗了十天的时间, 把困惑度下降到了 51 左右. (同期使用传统的统计算法, 最佳结果是 67)
2016年二月, 以 Rafal Jozefowicz 为第一作者的谷歌大脑的团队, 发表论文, "探索语言模型的极限" (Exploring the limits of language modeling). 该团队, 使用了 RNN/ LSTM 和所谓 "字母层面的卷积神经网络" (Character-Level Convolutional Neural Network) 的技术结合的模型, 在"十亿单词基准"的测试上把困惑度降低到了 30. 而相应的模型自由参数的数目降到了只有十亿 (相当于 Chelba 团队的模型的百分之五), 计算量大大降低.
更有意思的是,当把十个经过微调的不同参数的LSTM模型综合起来,取其均值, 对测试数据验证时, 其困惑度最低达 23.7.
机器越来越懂人话, 越来越会说人话了.
2. BLEU
参考:
论文:BLEU: a Method for Automatic Evaluation of Machine Translation
BLEU的全名为:bilingual evaluation understudy,即:双语互译质量评估辅助工具,它最初是用来评估机器翻译质量的工具。为了判断机器翻译的质量,可以根据一个数值指标来衡量其与一个或多个人工参考翻译的接近程度。
BLEU (Bilingual Evaluation Understudy,双语评估辅助工具)可以说是所有评价指标的鼻祖,它的核心思想是比较候选译文和参考译文里的 n-gram 的重合程度,重合程度越高就认为译文质量越高。unigram用于衡量单词翻译的准确性,高阶n-gram用于衡量句子翻译的流畅性。 实践中,通常是取N=1~4,然后对进行加权平均。
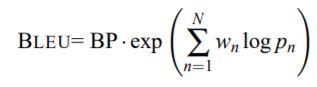
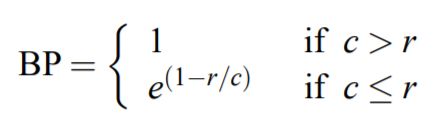
其中,r是一个参考翻译的词数,c是一个候选翻译的词数,BP代表译句较短惩罚值。
- BLEU 需要计算译文 1-gram,2-gram,...,N-gram 的精确率,一般 N 设置为 4 即可,公式中的 Pn 指 n-gram 的精确率。
- Wn 指 n-gram 的权重,一般设为均匀权重,即对于任意 n 都有 Wn = 1/N。
- BP 是惩罚因子,如果译文的长度小于最短的参考译文,则 BP 小于 1。
- BLEU 的 1-gram 精确率表示译文忠于原文的程度,而其他 n-gram 表示翻译的流畅程度。
- BLEU的设计思想与评判机器翻译好坏的思想是一致的:机器翻译结果越接近专业人工翻译的结果,则越好。
- BLEU的主要思想:使用与参考翻译匹配的可变长度短语的加权平均值。即BLUE去做判断:一句机器翻译的话与其相对应的几个参考翻译作比较,算出一个综合分数。这个分数越高说明机器翻译得越好。(注:BLEU算法是句子之间的比较,不是词组,也不是段落)。
- BLEU实现者的主要编程任务:将候选翻译的n-gram与参考翻译的n-gram进行比较并计算匹配数。 这些匹配与位置无关。 匹配越多,候选翻译就越好。
- BLEU是做不到百分百的准确的,它只能做到个大概判断,它的目标也只是给出一个快且不差自动评估解决方案。
基准BLEU指标——> 修正的n-gram精度——> 译句较短惩罚:通过一次次的改进、纠正,这样的 BLEU算法已经基本可以快捷地给出相对有参考价值的评估分数了。做不到也不需要很精确,它只是给出了一个评判的参考线而已。
(1)基准BLEU指标
其实最原始的BLEU算法很简单:两个句子,S1和S2,S1里头的词出现在S2里头越多,就说明这两个句子越一致。就像这样子:similarity(‘i like apple’, ‘i like english’)=2/3。
分子是一个候选翻译的单词有多少出现在参考翻译中(出现过就记一次,不管是不是在同一句参考翻译里头),分母是这个候选翻译的词汇数。
请看下面这个错误案例:
| Candidate | the | the | the | the | the | the | the |
| Reference1 | the | cat | is | on | the | mat | |
| Reference2 | there | is | a | cat | on | the | mat |
计算过程:
1. 候选翻译的每个词——the,都在参考译文中出现,分子为7;
2. 候选翻译一共就7个词,分母为7;
3. 这个翻译的得分: 7/7 = 1!
很明显,这样算是错的,需要改进一下。
(2)修正的n-gram精度
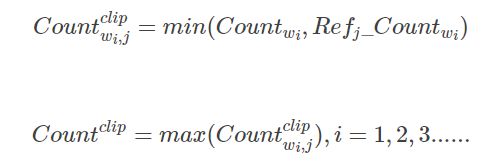


其实改进的n-gram精度得分可以用了衡量翻译评估的充分性和流畅性两个指标:一元组属于字符级别,关注的是翻译的充分性,就是衡量你的逐字逐字翻译能力; 多元组上升到了词汇级别的,关注点是翻译的流畅性,词组准了,说话自然相对流畅了。所以我们可以用多组多元精度得分来衡量翻译结果的。
(3)译句较短惩罚
再仔细看改进n-gram精度测量,当译句比参考翻译都要长时,分母增大了,这就相对惩罚了译句较长的情况。译句较短就更严重了!比如说下面这样:
| Candidate | the | cat | |||||
| Reference1 | the | cat | is | on | the | mat | |
| Reference2 | there | is | a | cat | on | the | mat |
显然,这时候选翻译的精度得分又是1(1/2+1/2)!短译句就是这样,很容易得高分…所以必须要设计一个有效的惩罚措施去控制。
首先,定一个名词叫“最佳匹配长度”(best match length),就是,如果译句长度和任意一个参考翻译的长度相同,就认为它满足最佳匹配长度。这种情况下,就不要惩罚了,惩罚因子要设为1。
其中,r是一个参考翻译的词数,c是一个候选翻译的词数,BP代表译句较短惩罚值。
最终BLEU值的计算公式为:
为赋予的权重,
为改进的多元精度。
(4)文本块的修正的n-gram精度
我们如何在多语句测试集上计算修正的n-gram精度? 虽然通常在整个文档的语料库中评估MT系统,但我们的基本评估单位是句子。 一条源语句可以翻译成许多目标语句,在这种情况下我们滥用术语并将相应的目标语句称为“语句”。我们首先逐句计算n-gram匹配。 接下来,我们将所有候选语句的截断的n-gram计数相加,并除以测试语料库中候选n-gram的数量,以计算整个测试语料库的修正的精度分数pn。

(5)组合修正后的n-gram精度
uni-gram下的指标可以衡量翻译的充分性,n-gram下的可以衡量翻译的流畅性,建议将它们组合使用。那么,应该如何正确的组合它们呢?
没疑问,加总求和取平均。专业点的做法要根据所处的境况选择加权平均,甚至是对原式做一些变形。
首先请看一下不同n-gram下的对某次翻译结果的精度计算:
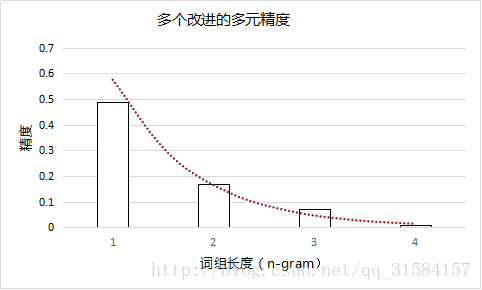
事实是这样,随着n-gram的增大,精度得分总体上成指数下降的,而且可以粗略的看成随着n而指数级的下降。我们这里采取几何加权平均,并且将各n-gram的作用视为等重要的,即取权重服从均匀分布。
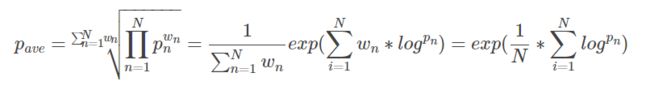
为赋予的权重,为改进的多元精度。
代码实现
>>>reference_corpus[0] [array([702, 12, 167, 430, 57, 21, 39, 255, 71, 100, 12])]
>>>generation_corpus[0] array([ 16, 14, 6, 2301])
import collections
import math
def _get_ngrams(segment, max_order):
"""Extracts all n-grams upto a given maximum order from an input segment.
Args:
segment: text segment from which n-grams will be extracted.
max_order: maximum length in tokens of the n-grams returned by this
methods.
Returns:
The Counter containing all n-grams upto max_order in segment
with a count of how many times each n-gram occurred.
"""
ngram_counts = collections.Counter()
for order in range(1, max_order + 1):
for i in range(0, len(segment) - order + 1):
ngram = tuple(segment[i:i + order])
ngram_counts[ngram] += 1
return ngram_counts
def compute_bleu(reference_corpus, translation_corpus, max_order=4,
smooth=False):
"""Computes BLEU score of translated segments against one or more references.
Args:
reference_corpus: list of lists of references for each translation. Each
reference should be tokenized into a list of tokens.
translation_corpus: list of translations to score. Each translation
should be tokenized into a list of tokens.
max_order: Maximum n-gram order to use when computing BLEU score.
smooth: Whether or not to apply Lin et al. 2004 smoothing.
Returns:
3-Tuple with the BLEU score, n-gram precisions, geometric mean of n-gram
precisions and brevity penalty.
"""
matches_by_order = [0] * max_order # 整个测试集上: references 与 translation 的 n-gram 匹配数--------分子
possible_matches_by_order = [0] * max_order # 整个测试集上: translation 的n-gram词数--------分母
reference_length = 0
translation_length = 0
for (references, translation) in zip(reference_corpus, translation_corpus):
reference_length += min(len(r) for r in references) # 可能多个参考句子
translation_length += len(translation) # 一个候选句子
merged_ref_ngram_counts = collections.Counter()
for reference in references:
merged_ref_ngram_counts |= _get_ngrams(reference, max_order)
translation_ngram_counts = _get_ngrams(translation, max_order)
overlap = translation_ngram_counts & merged_ref_ngram_counts # Counter({(18,): 1, (46, 18): 1, (46,): 1})
for ngram in overlap: # (18,)
matches_by_order[len(ngram) - 1] += overlap[ngram]
for order in range(1, max_order + 1):
possible_matches = len(translation) - order + 1
if possible_matches > 0:
possible_matches_by_order[order - 1] += possible_matches
# matches_by_order: [5874, 760, 99, 26]
# possible_matches_by_order: [50699, 44185, 37706, 31384]
'''
a = collections.Counter({(49, 6): 1, (3,): 1, (98, 487, 49, 6): 1, (49, 6, 999): 1})
b = collections.Counter({(49, 6): 1, (3,): 1, (486, 49, 6): 1, (49, 6): 1})
a & b
Counter({(3,): 1, (49, 6): 1})
'''
# 计算n-gram精度
precisions = [0] * max_order
for i in range(0, max_order):
if smooth:
# +1 平滑处理,防止为0
precisions[i] = ((matches_by_order[i] + 1.) /
(possible_matches_by_order[i] + 1.))
else:
if possible_matches_by_order[i] > 0:
precisions[i] = (float(matches_by_order[i]) /
possible_matches_by_order[i])
else:
precisions[i] = 0.0
# 组合修正后的n-gram精度
if min(precisions) > 0:
p_log_sum = sum((1. / max_order) * math.log(p) for p in precisions) # sum(1/N * log(Pn))
geo_mean = math.exp(p_log_sum) # exp(sum(1/N * log(Pn)))
else:
geo_mean = 0
# 译句较短惩罚
ratio = float(translation_length) / reference_length # 一个batch的总长度
if ratio > 1.0:
bp = 1.
elif ratio == 0.0:
bp = 0.
else:
bp = math.exp(1 - 1. / ratio)
bleu = geo_mean * bp
return bleu, precisions, bp, ratio, translation_length, reference_length