GBDT与xgboost :流失预测 shap解释 调参 保存调参好的模型
集成学习
集成学习的方式分为两类:
个体的学习器之间存在强依赖关系,必须串行生成序列化方法,代表
Boosting;
个体学习器之间不存在强依赖关系,可同时生成并行化方法,代表是Bagging和随机森林。


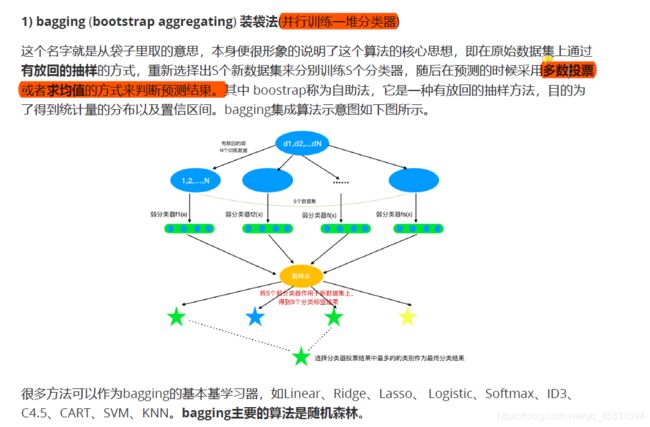
bagging
boosting


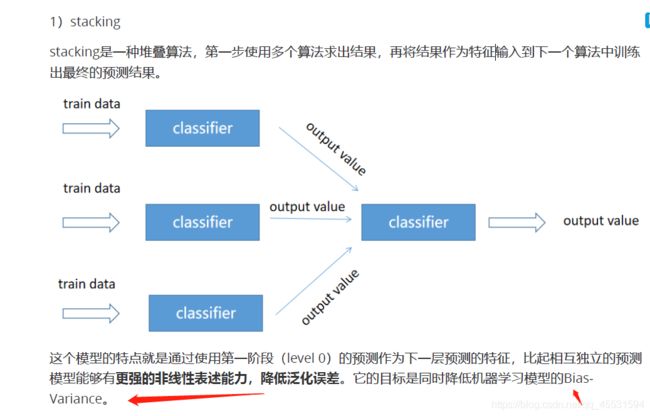
stacking
2)点击率预估
使用GBDT+LR进行点击率(CTR)预估。
https://blog.csdn.net/Snoopy_Yuan/article/details/80703175?depth_1-utm_source=distribute.pc_r
elevant.none-task&utm_source=distribute.pc_relevant.none-task


XGBOOST 的推导过程

实例:

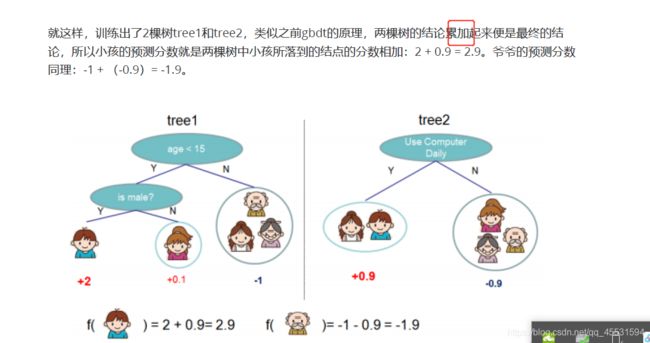
XGBOOST 是一个加法模型


T为叶子节点的个数,Wj为叶子节点的权重。





Xgboost-重要参数


对于General paramaters,表示使用何种基本模型,通常是决策树或线性模型,一般不需要调整,采
用默认值即可,参数调优不包括这部分。
主要参数是以下几类:


对于Booster paramaters,表示若学习器相关参数,需要仔细调整,会影响模型性能。.
eta 学习率
gamma




对于Learning task parameters,与任务有关,定下来后通常不需要调整。

XGBoost调参技巧

XGBOOST 比GBDT的特点

选用哪一种xgboost
*
代码实操* :
## 获取数据
import xgboost as xgb # 调用陈天奇的库
from xgboost.sklearn import XGBClassifier # 使用sklearn api
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import metrics
data = pd.read_table('C:/Users/lb/Desktop/test/gouwu.txt',sep='\t',engine="python",encoding = 'utf-8')
data.columns.values
data.head()

data.shape

分割数据集
from sklearn.model_selection import train_test_split
data_x = data.drop(['留存标签'],axis=1)
data_y = data['留存标签']
train_x,test_x,train_y,test_y = train_test_split(data_x,data_y,test_size=0.3,random_state=5)
行标签的恢复以后注意添加这个步骤
for i in [train_x,test_x]:
i.index = range(i.shape[0])
train_x.head()

模型的训练
from sklearn.metrics import accuracy_score
model = XGBClassifier( )
# 训练模型
model.fit(train_x,train_y)
# 预测模型
pred_y = model.predict(test_x)
metrics.accuracy_score(test_y, pred_y)
分类的准确率
![]()
xgboost 进阶用法

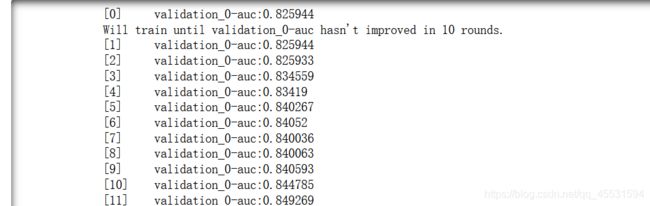
监控每一步的表现
# 监控模型每一步的表现
# eval_set=[(x_test,y_test)] 评估数据集,list类型
# eval_metric 评估标准(多分类问题,使用mlogloss作为损失函数),二分类 auc
# early_stopping_rounds= 10 如果模型的loss十次内没有减小,则提前结束模型训练
# verbose = True True显示,False不显示
eval_set = [(test_x, test_y)]
model.fit(train_x, train_y, early_stopping_rounds=10, eval_metric="auc",
eval_set=eval_set, verbose=True)
显示特征的重要性
#显示各个特征的重要性 ---- 基于训练的特征树输出
from xgboost import plot_importance
from matplotlib import pyplot
plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plot_importance(model)
pyplot.show()

为了得到影响因素正向还是逆向的影响,用shap
shap 来解释xgboost模型
import shap
shap.initjs()
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(train_x)
print(shap_values)

shap_values.shape
train_x.shape

plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
shap.summary_plot(shap_values,train_x,max_display=30)
#红色高 蓝色低
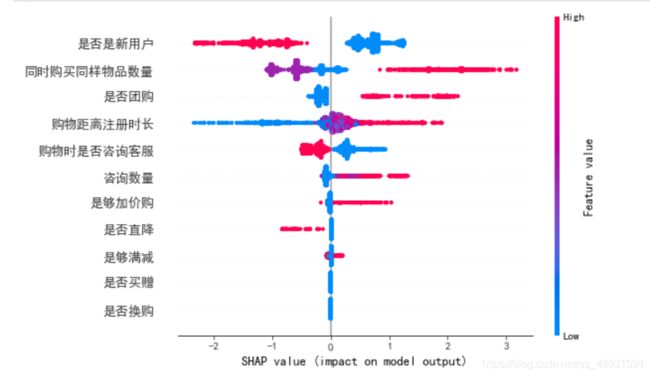
shap.summary_plot(shap_values,train_x, plot_type="bar")
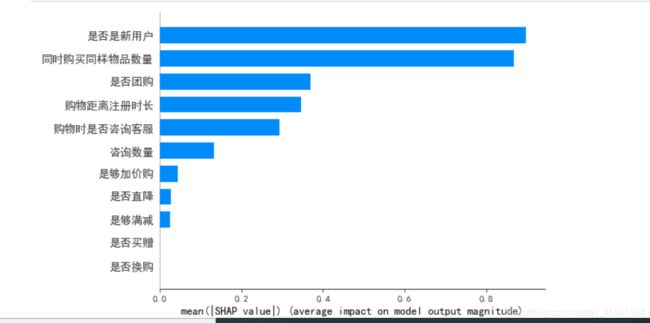
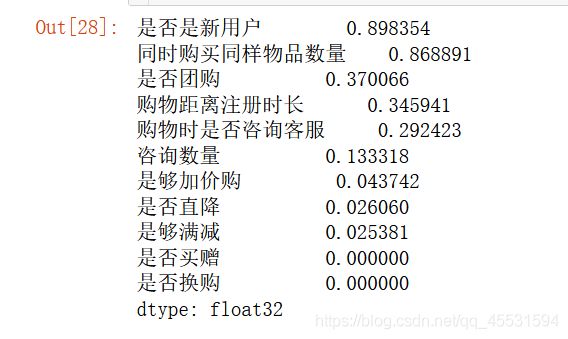
做一个简单的验证
pd.DataFrame(abs(shap_values),columns=train_x.columns).mean().sort_values(ascending=False)
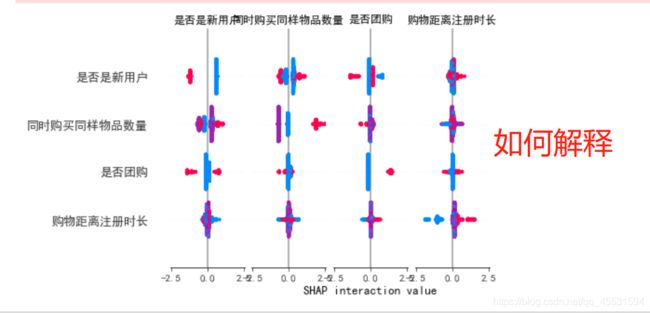
# 多个变量交互
shap_interaction_values = shap.TreeExplainer(model).shap_interaction_values(train_x)
shap.summary_plot(shap_interaction_values, train_x, max_display=4)
依赖图
依赖图
同样可以通过单变量的依赖图看出单变量对目标的影响,横坐标是特征值纵坐标是shap值:
shap.dependence_plot('购物距离注册时长',
shap_values,train_x,
interaction_index=None,
show=False)
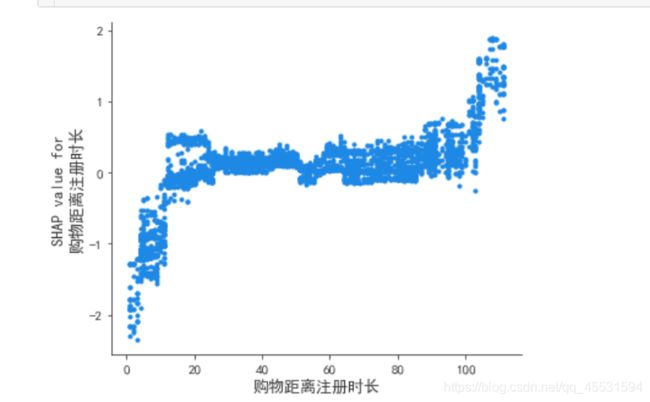
可以看出购物距离注册市场对于用户的留存存在正相关的作用
类似案例的参考解释:


那么双变量呢? 参考案例如下:
其他别人案例代码:
shap.dependence_plot('Pclass', shap_values[1], X_test, interaction_index='Sex_encoding', show=False)
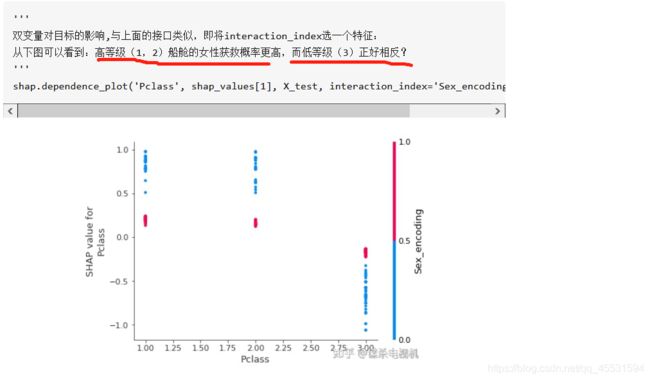
得出一个经验:不要看太多的颜色而是方向
[添加链接描述] 可再去参考这个教程(https://blog.csdn.net/weixin_43615654/article/details/103436632?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param)
观察某一行各个特征对结果的影响
shap.initjs()
shap.force_plot(explainer.expected_value, shap_values[5], train_x.iloc[5])

模型调参
from sklearn.model_selection import GridSearchCV
#这里交叉验证也可以 K折
from sklearn.model_selection import StratifiedKFold
#设定网格搜索的xgboost参数搜索范围,值搜索XGBoost的主要6个参数.
#注意看这里是个字典
param_dist = {
'n_estimators':range(80,150,5),
'max_depth':range(3,10,1),
'learning_rate':np.linspace(0.01,0.1,20),
'subsample':np.linspace(0.7,0.9,20),
'colsample_bytree':np.linspace(0.5,0.98,10),
'min_child_weight':range(1,9,1)
}
网格搜索
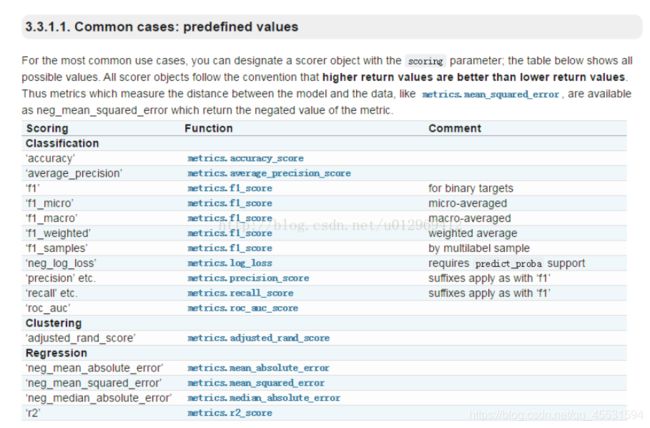
grid = GridSearchCV(model,param_dist,cv = 3,scoring = 'neg_log_loss',
n_jobs = -1)
#在训练集上训练
grid.fit(train_x, train_y)
#返回最优的训练器
grid.best_params_
model_best = XGBClassifier(grid.best_params_)
速度慢下3.
#上面这个速度太慢
model1 = XGBClassifier()
learning_rate = [0.0001, 0.001, 0.01, 0.1,0.12,0.15,0.2,0.3]
#转成字典
param_grid = dict(learning_rate=learning_rate)```
```python
param_grid
![]()
score 在不同场景情况下的取值
Python-sklearn包中StratifiedKFold和KFold生成交叉验证数据集的区别
利用KFOLD 实现交叉验证
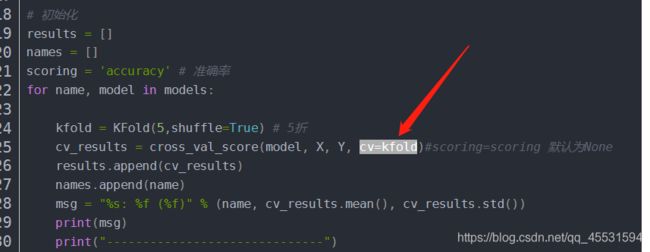
model1 = XGBClassifier()
learning_rate = [0.0001, 0.001, 0.01, 0.1,0.12,0.15,0.2,0.3]
param_grid = dict(learning_rate=learning_rate)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
grid_search = GridSearchCV(model1, param_grid, scoring="neg_log_loss",
n_jobs=-1, cv=kfold)
grid_result = grid_search.fit(train_x, train_y)
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))

model2 = XGBClassifier()
n_estimators = range(80,200,5)
param_grid = dict(n_estimators = n_estimators)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)
grid_search = GridSearchCV(model2, param_grid, scoring="neg_log_loss",
n_jobs=-1, cv=kfold)
grid_result = grid_search.fit(train_x, train_y)
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
![]()
# 调参
model3 = XGBClassifier(n_estimators=110,learning_rate= 0.12)
model3.fit(train_x,train_y)
# 预测模型
pred_y = model3.predict(test_x)
metrics.accuracy_score(test_y, pred_y)
0.7625979843225084
保存模型
# 保存模型
import pickle
pickle.dump(model,open("C:/Users/lb/Desktop/test/tl.dat","wb"))
# 可以进行读
# 读取模型,重新打开jupyter
import pickle
load_file = open("C:/Users/lb/Desktop/test/tl.dat","rb")
load_game_data = pickle.load(load_file)
load_file.close()
load_game_data

接着预测
load_game_data.predict(train_x)